1. 为什么要爬虫?
“大数据时代”,数据获取的方式:
- 大型企业公司有海量用户,需要收集数据来提升产品体验
【百度指数(搜索),阿里指数(网购),腾讯数据(社交)】 - 数据管理咨询公司: 通过数据团队专门提供大量数据,通过市场调研,问卷调查等
- 政府/机构提供的公开数据
- 中华人民共和国统计局
- World bank
- Nasdaq
- 第三方数据平台购买数据
- 数据堂
- 贵阳大数据交易平台
- 爬虫数据
2. 什么是爬虫?
抓取网页数据的程序
3. 爬虫如何抓取网页数据?
首先需要了解网页的三大特征:
- 每个网页都有自己的
URL(统一资源定位符)来定位 - 网页都使用
HTML(超文本标记语言)来描述页面信息 - 网页都使用
HTTP/HTTPS(超文本传输协议)来传输HTML数据
爬虫的设计思路:
- 首先确定需要爬取的网
URL地址 - 通过
HTTP/HTTPS协议来获取对应的HTML页面 - 提取
HTML页面内有用的数据:
a. 如果是需要的数据--保存
b. 如果有其他URL,继续执行第二步
4. Python爬虫的优势?
| 语言 | 优点 | 缺点 |
|---|---|---|
| PHP | 世界上最好的语言 | 对多线程,异步支持不好,并发处理不够 |
| Java | 网络爬虫生态圈完善 | Java语言本身笨重,代码量很大,数据重构成本高 |
| C/C++ | 运行效率和性能几乎最强 | 学习成本很高 |
| python | 语法优美,代码简洁,开发效率高,模块多 |
5. 学习路线
- 抓取
HTML页面:
- HTTP请求的处理:
urllib, urlib2, requests - 处理器的请求可以模拟浏览器发送请求,获取服务器响应的文件
- 解析服务器相应的内容:
re, xpath, BeautifulSoup(bs4), jsonpath, pyquery等- 使用某种描述性语言来给我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会被匹配
- 采集动态
HTML,验证码的处理
- 通用动态页面采集:
Selenium + PhantomJS:模拟真实浏览器加载JS - 验证码处理:
Tesseract机器学习库,机器图像识别系统
Scrapy框架:
- 高定制性,高性能(异步网络框架
twisted)->数据下载快 - 提供了数据存储,数据下载,提取规则等组件
- 分布式策略:
scrapy redis:在scarpy基础上添加了以redis数据库为核心的一套组件,主要在redis做请求指纹去重、请求分配、数据临时存储
- 爬虫、反爬虫、反反爬虫之间的斗争:
User-Agent,代理,验证码,动态数据加载,加密数据
6. 爬虫的分类
6.1 通用爬虫:
1.定义: 搜索引擎用的爬虫系统
2.目标: 把所有互联网的网页爬取下来,放到本地服务器形成备份,在对这些网页做相关处理(提取关键字,去除广告),最后提供一个用户可以访问的借口
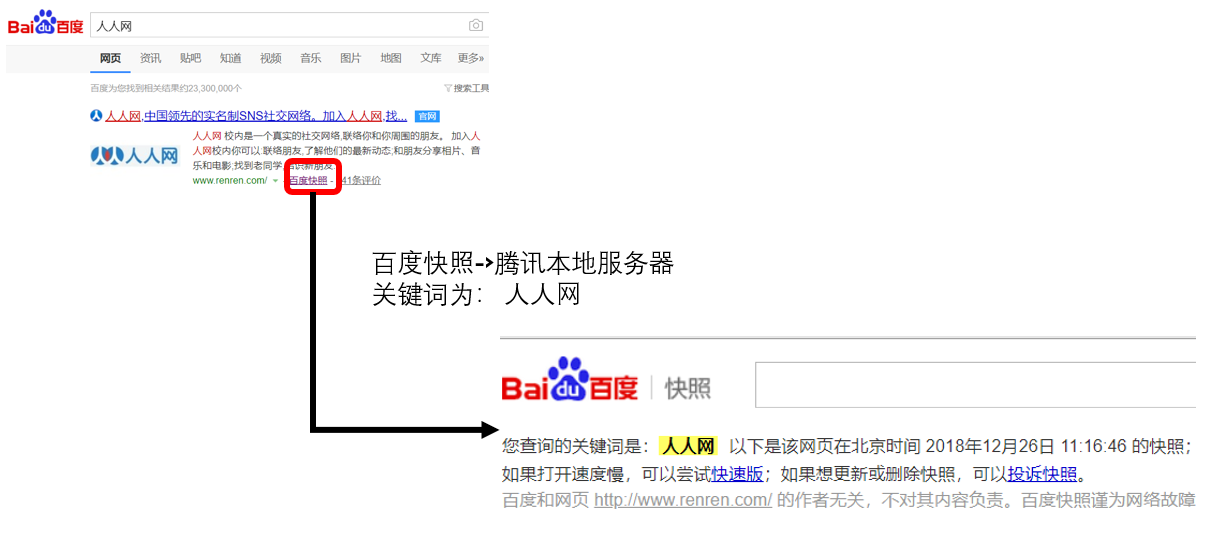
3.抓取流程:
a) 首先选取一部分已有的URL, 把这些URL放到带爬取队列中
b) 从队列中取出来URL,然后解析NDS得到主机IP,然后去这个IP对应的服务器里下载HTML页面,保存到搜索引擎的本地服务器里,之后把爬过的URL放入已爬取队列
c) 分析网页内容,找出网页里其他的URL连接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取一个新网站的URL:
- 主动向搜索引擎提交网址: https://ziyuan.baidu.com/linksubmit/index
- 在其他网站设置网站的外链: 其他网站上面的友情链接
- 搜索引擎会和DNS服务商进行合作,可以快速收录新网站
5.通用爬虫注意事项
通用爬虫并不是万物皆可以爬,它必须遵守规则:
Robots协议:协议会指明通用爬虫可以爬取网页的权限
我们可以访问不同网页的Robots权限
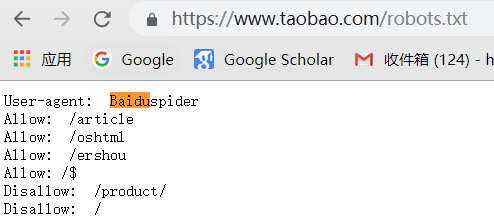
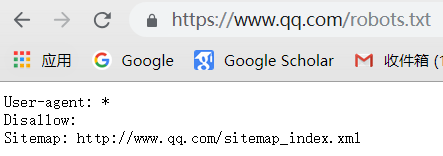
6.通用爬虫通用流程:

7.通用爬虫缺点
- 只能提供和文本相关的内容(HTML,WORD,PDF)等,不能提供多媒体文件(msic,picture, video)及其他二进制文件
- 提供结果千篇一律,不能针对不同背景领域的人听不同的搜索结果
- 不能理解人类语义的检索
- 聚焦爬虫的优势所在
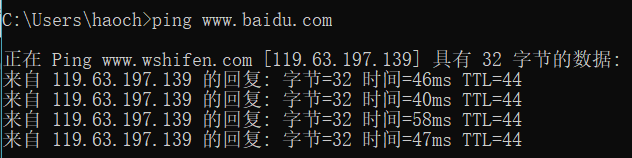
DNS 域名解析成IP: 通过在命令框中输入ping www.baidu.com,得到服务器的IP
6.2 聚焦爬虫:
爬虫程序员写的针对某种内容的爬虫-> 面向主题爬虫,面向需要爬虫