1、把需要的处理的文件先得传输到hdfs上去
2、把mapreducer程序打成jar包传输到linux中
3、在yarn上跑jar包 hadoop jar jar包名 main方法的入口名称
一、导入pom文件
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
二、mapper阶段
/**
* @ClassName WordCountMapper
* @Description mapTask程序 任务:K1,V1--->K2,V2
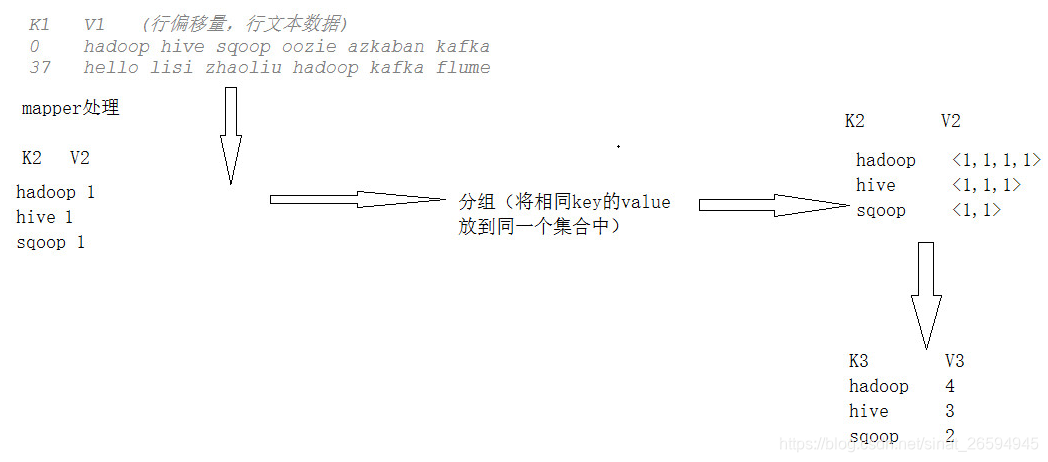
* K1 V1 (行偏移量,行文本数据)
* 0 hadoop hive sqoop oozie azkaban kafka
* 37 hello lisi zhaoliu hadoop kafka flume
*------------------------------------------
* K2 V2
* hadoop 1
* hive 1
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
/*
map方法的调用,看上游的InputFormat的类型,比如这里我们会是用TextInputFormat,一行一行的发送,每发送一行数据,就调用一次map方法
参数1和2 K1和V1 参数3:context上下文 环境 域对象
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.得到V1 根据空格切割 v1是通过inputformat得到的 inputformat默认的是一行一行的读数据的
String[] words = value.toString().split(" ");
Text text = new Text();
LongWritable longWritable = new LongWritable();
//循环发送
for (String word : words) {
//2.发送数据 K2,V2 (hadoop,1)
text.set(word);
longWritable.set(1);
// 发送
context.write(text,longWritable);
}
}
}
三、reducer阶段
/**
* @ClassName WordCountReducer
* @Description reducer合并 K2,V2--->K3,V3
* K2 V2
* hadoop <1,1,1>
* hive <1,1>
* ------------------------
* K3 V3
* hadoop 3
* hive 2
*/
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1.遍历V2集合,进行统计操作
long count = 0;
for (LongWritable value : values) {
count+=value.get();
}
//2.将K2作为K3 将统计的结果作为V3 向下发送
context.write(key,new LongWritable(count));
}
四、runner阶段
/**
* @ClassName WordCountRunner
* @Description 任务的组装和任务的提交
*/
public class WordCountRunner implements Serializable{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
//创建任务
Job job = Job.getInstance(conf, "wordcount"); //wordcount为任务的名称
job.setJarByClass(WordCountRunner.class);//在集群上运行要加上
//第一步:设置InputFormat和数据的输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:9000/hadoop32/words.txt"));
//第二步:设置自定义的Mapper类并且设置输出类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//第三、四、五、六步 省略
//第七步:设置自定义的Reducer类并且设置输出类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步:设置OutputFormat和数据的输出路径
job.setOutputFormatClass(TextOutputFormat.class);
//强调,MR默认输出路径是不能存在的,如果存在会报错
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:9000/hadoop32/wordcount"));
//得到该文件夹 防止hdfs中已存在文件输入的文件夹
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), conf);
if(fileSystem.exists(new Path("hdfs://node01:9000/hadoop32/wordcount"))){
fileSystem.delete(new Path("hdfs://node01:9000/hadoop32/wordcount"), true);
}
// 任务的提交
boolean bl = job.waitForCompletion(true);
System.exit(bl?0:1);
}
}