一、Guava
Strings
package com.google.common.base;
Srings类程序中经常使用。
比如判断字符串是否为空,我们在之前用jdk方法判断是会用下面这个判断语句。
if( input==null || input.equals("") ){
System.out.println("输入字符串为空");
}
上面的代码如果不注意的话就容易写错,并且不优美。现在采用guava的Strings类进行判断,请看下面的
if(Strings.isNullOrEmpty(input)){
System.out.println("输入字符串为空");
}
这样是不是看起来很优雅。
下面开始阅读Strings的源码:
1、nullToEmpty()
public static String nullToEmpty(@Nullable String string) {
return (string == null) ? "" : string;
}
从源码中可以看到:return (string == null) ? "" : string;
如果字符串对象为空,则返回空字符串"",否则就返回原字符串。
看一下怎么使用的:
Strings.nullToEmpty(null);//""
Strings.nullToEmpty("zhang");//返回"zhang"
2、emptyToNull()
public static String emptyToNull(@Nullable String string) {
return isNullOrEmpty(string) ? null : string;
}
这个方法就与上面的emptyToNull()方法相反了,如果输入的是空字符串,那么就返回null,否则返回原字符串
Strings.emptyToNull("");//返回null
Strings.emptyToNull("zhang");//返回"zhang"
3、isNullOrEmpty()
public static boolean isNullOrEmpty(@Nullable String string) {
return Platform.stringIsNullOrEmpty(string);
}
Returns {@code true} if the given string is null or is the empty string.
这句话的意思是如果输入的字符串对象是null或者输入的字符串内容为空,那么就返回true。
Strings.isNullOrEmpty("");//返回true
Strings.nullToEmpty(null);//""
4、padStart()方法
public static String padStart(String string, int minLength, char padChar) {
checkNotNull(string); // eager for GWT.
if (string.length() >= minLength) {
return string;
}
StringBuilder sb = new StringBuilder(minLength);
for (int i = string.length(); i < minLength; i++) {
sb.append(padChar);
}
sb.append(string);
return sb.toString();
}
从源码中我们可以看出,输入参数为为三个,一个是字符串,一个是长度,一个是 字符
结果返回一个长度至少是minLength的字符串,如果string长度不够就在它前面添加若干个padChar,以使结果字符串长度为minLength。
看一下了例子:
padStart("7", 3, '0');
returns {"007"} padStart("2010", 3, '0');
returns {"2010"}
5、padEnd()
public static String padEnd(String string, int minLength, char padChar) {
checkNotNull(string); // eager for GWT.
if (string.length() >= minLength) {
return string;
}
StringBuilder sb = new StringBuilder(minLength);
sb.append(string);
for (int i = string.length(); i < minLength; i++) {
sb.append(padChar);
}
return sb.toString();
}
那么padEnd方法就与上面的padStart方法相反了。
如果长度不够,在string后补padChar。
padEnd("4.", 5, '0');
returns {"4.000"}
padEnd("2010", 3, '!');
returns { "2010"}
6、repeat()
public static String repeat(String string, int count) {
checkNotNull(string); // eager for GWT.
if (count <= 1) {
checkArgument(count >= 0, "invalid count: %s", count);
return (count == 0) ? "" : string;
}
// IF YOU MODIFY THE CODE HERE, you must update StringsRepeatBenchmark
final int len = string.length();
final long longSize = (long) len * (long) count;
final int size = (int) longSize;
if (size != longSize) {
throw new ArrayIndexOutOfBoundsException("Required array size too large: " + longSize);
}
final char[] array = new char[size];
string.getChars(0, len, array, 0);
int n;
for (n = len; n < size - n; n <<= 1) {
System.arraycopy(array, 0, array, n, n);
}
System.arraycopy(array, 0, array, n, size - n);
return new String(array);
}
这个方法就是将输入的字符串重复拼接count次
repeat("hey", 3) ;
returns the string {"heyheyhey"}
7、commonPrefix()
public static String commonPrefix(CharSequence a, CharSequence b) {
checkNotNull(a);
checkNotNull(b);
int maxPrefixLength = Math.min(a.length(), b.length());
int p = 0;
while (p < maxPrefixLength && a.charAt(p) == b.charAt(p)) {
p++;
}
if (validSurrogatePairAt(a, p - 1) || validSurrogatePairAt(b, p - 1)) {
p--;
}
return a.subSequence(0, p).toString();
}
通过源码我们很好理解这个方法的目的是查询两个字符串的最长公共前缀。如果没有公共前缀的话就返回空字符串。
Strings.commonPrefix("aaab", "aac");//"aa"否则返回""
8、commonSuffix()
public static String commonSuffix(CharSequence a, CharSequence b) {
checkNotNull(a);
checkNotNull(b);
int maxSuffixLength = Math.min(a.length(), b.length());
int s = 0;
while (s < maxSuffixLength && a.charAt(a.length() - s - 1) == b.charAt(b.length() - s - 1)) {
s++;
}
if (validSurrogatePairAt(a, a.length() - s - 1)
|| validSurrogatePairAt(b, b.length() - s - 1)) {
s--;
}
return a.subSequence(a.length() - s, a.length()).toString();
}
该方法返回两个字符串的最长公共后缀。
Strings.commonSuffix("aaac", "aac");//"aac"否则返回""
Files
package com.google.common.io;
之前读文件时一直采用类似这种方式:
bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
Files,文件操作类。
readLines(File file, Charset charset),这个方法将File按行存入list<String>中。
return readLines(
file,
charset, //编码方式,通常都是utf-8
new LineProcessor<List<String>>() {
final List<String> result = Lists.newArrayList();
@Override
public boolean processLine(String line) {
result.add(line);
return true;
}
@Override
public List<String> getResult() {
return result;
}
});
public static <T> T readLines(File file, Charset charset, LineProcessor<T> callback) //这个方法在将文件按行存储为Lists<String>时,同时调用行处理方法,只有满足要求的结果才会存到结果中。
throws IOException {
return asCharSource(file, charset).readLines(callback);
}
public static String toString(File file, Charset charset) throws IOException { //将文件转化为String,并返回,包含文件中的所有字符,包括换行符
return asCharSource(file, charset).read();
}
public static boolean equal(File file1, File file2) throws IOException //如果这两个文件相同,则返回true。这时不仅是内容,还包括文件长度。
if (file1 == file2 || file1.equals(file2)) {
return true;
}
if (len1 != 0 && len2 != 0 && len1 != len2) {
return false;
}
public static void copy(File from, File to) throws IOException { //拷贝一个文件里的所以字符给另一个文件
checkArgument(!from.equals(to), "Source %s and destination %s must be different", from, to);
asByteSource(from).copyTo(asByteSink(to));
}
public static void write(CharSequence from, File to, Charset charset) throws IOException {
//将指定内容写入文件,如果文件原本存在内容,则覆盖
asCharSink(to, charset).write(from);
}
public static void append(CharSequence from, File to, Charset charset) throws IOException { //追加文件,将指定内容追加到文件尾
write(from, to, charset, true);
}
MultiSet
package com.google.common.collect;
我们在进行字符统计时,同常采用的方法就是:
String[] text=new String[]{"the weather is good ","today is good","today has good weather","good weather is good"};
HashMap<String, Integer> hashMap=new HashMap<String, Integer>();
for (int i=0;i<text.length;i++){
String temp=text[i];
String[] words=temp.split("\s");
for(int j=0;j<words.length;j++){
if(!hashMap.containsKey(words[j])){
hashMap.put(words[j], new Integer(1));
}else{
int k=hashMap.get(words[j]).intValue()+1;
hashMap.put(words[j], new Integer(k));
}
}
}
这种方法的思想就是:首先建立一个Map,key值存储单词,value存储出现次数,在循环添加单词,如果没有相同的key,则将单词添加到key中,并设置它的value值为1,如果map中含有相同的key,则将对应的value值加1。这种方法冗余且容易出错。guava设计了一个集合类,Multiset,就是今天我们要介绍的。
先看看Multiset怎么进行词频统计的:
String[] text=new String[]{"the weather is good ","today is good","today has good weather","good weather is good"};
Multiset<String> set = HashMultiset.create(list);for (int i=0;i<text.length;i++){
String temp=text[i];
String[] words=temp.split("\s");
for(int j=0;j<words.length;j++){
set.add(words[j]);
}
}
在获取某个单词的个数时:
System.out.println(set.count("the")); //这样就可以了哦
简单吧,Mutiset解决了我们很多问题,从类名上我们就可以知道这个set集合可以存放相同的元素。
现在看看它的主要用法:
Multiset接口定义的接口主要有:
add(E element) :向其中添加单个元素
add(E element,int occurrences) : 向其中添加指定个数的元素
count(Object element) : 返回给定参数元素的个数
remove(E element) : 移除一个元素,其count值 会响应减少
remove(E element,int occurrences): 移除相应个数的元素
elementSet() : 将不同的元素放入一个Set中
entrySet(): 类似与Map.entrySet 返回Set<Multiset.Entry>。包含的Entry支持使用getElement()和getCount()
setCount(E element ,int count): 设定某一个元素的重复次数
setCount(E element,int oldCount,int newCount): 将符合原有重复个数的元素修改为新的重复次数
retainAll(Collection c) : 保留出现在给定集合参数的所有的元素
removeAll(Collectionc) : 去除出现给给定集合参数的所有的元素
实例:
Multiset<String> wordsMultiset = HashMultiset.create();
wordsMultiset.addAll(wordList);
for(String key:wordsMultiset.elementSet()){
System.out.println(key+" count:"+wordsMultiset.count(key));
}
if(!wordsMultiset.contains("peida")){
wordsMultiset.add("peida", 2);
}
for(String key:wordsMultiset.elementSet()){
System.out.println(key+" count:"+wordsMultiset.count(key));
}
if(wordsMultiset.contains("peida")){
wordsMultiset.setCount("peida", 23);
}
System.out.println("============================================");
for(String key:wordsMultiset.elementSet()){
System.out.println(key+" count:"+wordsMultiset.count(key));
}
if(wordsMultiset.contains("peida")){
wordsMultiset.setCount("peida", 23,45);
}
System.out.println("============================================");
for(String key:wordsMultiset.elementSet()){
System.out.println(key+" count:"+wordsMultiset.count(key));
}
if(wordsMultiset.contains("peida")){
wordsMultiset.setCount("peida", 44,67);
}
System.out.println("============================================");
for(String key:wordsMultiset.elementSet()){
System.out.println(key+" count:"+wordsMultiset.count(key));
}
二、java8
上面带大家熟悉一下guava工具包。
现在主要介绍下常用的java8。
我们程序里用到了很多的lamada表达式,那么什么是lamada表达式呢?
一段带有输入参数的可执行语句块。
比如:
List<String> names = Lists.newArrayList("apple","pear","banana");
Collections.sort(names,((o1, o2) -> o1.compareTo(o2)));
如果不用lambda表达式,应该怎么样编写呢?
List<String> names = Lists.newArrayList("apple","pear","banana");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
可以明显的看出lambda表达式的优点。
现在有一个题目:将字符串类型的列表里的元素全部转换成大写。
如果采用原始的方法:
List<String> list = new ArrayList<String>();
list.add("I am a boy");
list.add("I love the girl");
list.add("But the girl loves another girl");
List<String> upperCaseList = new ArrayList<String>();
for(String name : list){
upperCaseList.add(name.toUpperCase());
}
采用guava:
List<String> upcaseNames = FluentIterable.from(list).transform(new Function<String, String>() {
@Override
public String apply(String input) {
return input.toUpperCase();
}
}).toList();
假如使用lambda:
List<String> upcaseNames = list.stream().map(String::toUpperCase).collect(Collectors.toList());
我们在此抽象一下lambda表达式的一般语法:
(Type1 param1, Type2 param2, ..., TypeN paramN) -> {
statment1;
statment2;
//.............
return statmentM;
}
从lambda表达式的一般语法可以看出来,lambda确实是“一段带有输入参数的可执行语句块”。
1. 参数类型省略–绝大多数情况,编译器都可以从上下文环境中推断出lambda表达式的参数类型。这样lambda表达式就变成了:
(param1,param2, ..., paramN) -> { statment1; statment2; //............. return statmentM; }
比如:
List<String> upperCaseNames = names.stream().map((name) -> {return name.toUpperCase();}).collect(Collectors.toList());
2、当lambda表达式的参数个数只有一个,可以省略小括号。lambda表达式简写为:
param1 -> {
statment1;
statment2;
//.............
return statmentM;
}
比如:
List<String>
upperCaseNames= names.stream().map(name -> {returnname.toUpperCase();}).collect(Collectors.toList());
3、 当lambda表达式只包含一条语句时,可以省略大括号、return和语句结尾的分号。lambda表达式简化为:param1 -> statment
比如:
List<String> upperCaseNames = names.stream().map(name -> name.toUpperCase()).collect(Collectors.toList());
在这里需要说明一下,从上面看到lambda表达一直是接收内部变量,那么是否可以接收外部参数呢?
我们尝试了一下:

发现有错误。提示说lamada表达式只能接收不可变的参数。
那么这是为什么呢?
因为lambda表达式是内部类。
内部类里面使用外部类的局部变量时,其实就是内部类的对象在使用它,内部类对象生命周期中都可能调用它,
而内部类试图访问外部方法中的局部变量时,外部方法的局部变量很可能已经不存在了,那么就得延续其生命
,拷贝到内部类中,而拷贝会带来不一致性,从而需要使用final声明保证一致性。
上面在介绍lambda时,会发现使用了很多stream的东西。
那么什么是stream(流)。
Stream是元素的集合,这点让Stream看起来用些类似Iterator;
可以支持顺序和并行的对原Stream进行汇聚的操作;
大家可以把Stream当成一个高级版本的Iterator。原始版本的Iterator,用户只能一个一个的遍历元素并对其执行某些操作;高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,比如“过滤掉长度大于10的字符串”、“获取每个字符串的首字母”等。
//Lists是Guava中的一个工具类 List<Integer> nums = Lists.newArrayList(1,null,3,4,null,6); nums.stream().filter(num -> num != null).count();
看上面这段代码

在此我们总结一下使用Stream的基本步骤:
- 创建Stream;
- 转换Stream,每次转换原有Stream对象不改变,返回一个新的Stream对象(**可以有多次转换**);
- 对Stream进行聚合(Reduce)操作,获取想要的结果;
分析好stream的处理流程后,看看stream可以进行哪些操作:
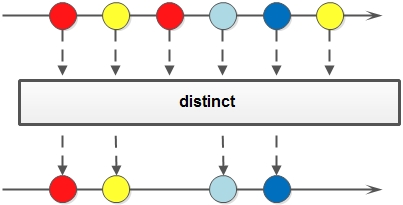
1. distinct: 对于Stream中包含的元素进行去重操作(去重逻辑依赖元素的equals方法),新生成的Stream中没有重复的元素;
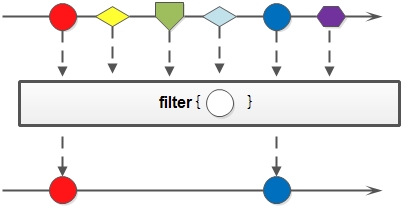
2. filter: 对于Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素;
filter方法示意图:
3. map:
对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗;
map方法示意图:
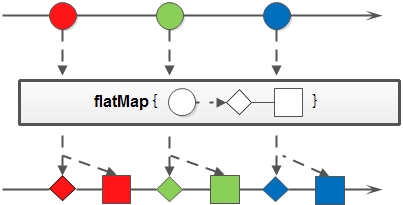
4. flatMap:和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中;
flatMap方法示意图:
5. peek: 生成一个包含原Stream的所有元素的新Stream,观察流的内容,返回原来的流保持不变,action用来观察流中的每个元素,该方法主要用来调试,并不产生实际作用
peek方法示意图:
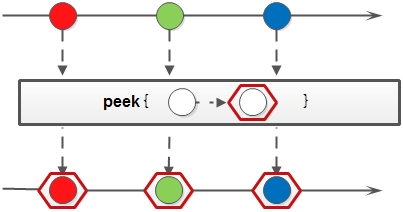
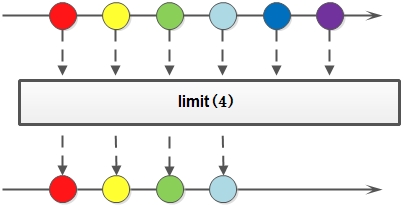
6. limit: 对一个Stream进行截断操作,获取其前N个元素,如果原Stream中包含的元素个数小于N,那就获取其所有的元素;
limit方法示意图:
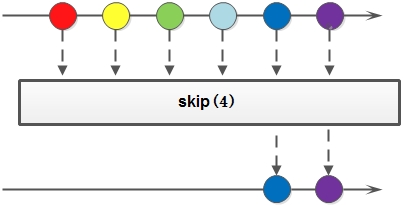
7. skip: 返回一个丢弃原Stream的前N个元素后剩下元素组成的新Stream,如果原Stream中包含的元素个数小于N,那么返回空Stream;
skip方法示意图:
8. 上面的操作组合在一起:
List<Integer> nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
System.out.println(“sum is:”+nums.stream().filter(num -> num != null).
distinct().mapToInt(num -> num * 2).
peek(System.out::println).skip(2).limit(4).sum());
当然,进行任何操作,最终都是想得到一个结果,stream同样提供了很多聚合操作,主要分为两部分:
- 可变汇聚:把输入的元素们累积到一个可变的容器中,比如Collection或者StringBuilder;
- 其他汇聚:除去可变汇聚剩下的,一般都不是通过反复修改某个可变对象,而是通过把前一次的汇聚结果当成下一次的入参,反复如此。比如reduce,count,allMatch;
比如:
list.stream().map(String::toUpperCase).collect(Collectors.toList());
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce(0, (sum, item) -> sum + item));
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().count());
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10); System.out.println(ints.stream().allMatch(item -> item < 100)); ints.stream().max((o1, o2) -> o1.compareTo(o2)).ifPresent(System.out::println);