这篇文章主要是记录HanLP标准分词算法整个实现流程。
- HanLP的核心词典训练自人民日报2014语料,语料不是完美的,总会存在一些错误。这些错误可能会导致分词出现奇怪的结果,这时请打开调试模式排查问题:
HanLP.Config.enableDebug();
那什么是语料呢?通俗的理解,就是HanLP里面的二个核心词典。假设收集了人民日报若干篇文档,通过人工手工分词,统计人工分词后的词频:①统计分词后的每个词出现的频率,得到一元核心词典;②统计两个词两两相邻出现的频率,得到二元核心词典。根据贝叶斯公式:
其中(count(A,B))表示词A和词B 在语料库中共同出现的频率;(count(B))表示词B 在语料库中出现的频率。有了这两个频率,就可以计算在给定词B的条件下,下一个词是 A的概率。
分词流程
采用维特比分词器:基于动态规划的维特比算法。
List<Term> termList = HanLP.segment(sentence);
在进入正式分词流程前,可选择是否进行归一化,然后进入到正式的分词流程。
if (HanLP.Config.Normalization)
{
CharTable.normalization(text);
}
return segSentence(text);
第一步,构建词网WordNet,参考:词图的生成
词网包含起始顶点和结束顶点,以及待分词的文本内容,文本内容保存在charArray数组中。vertexes表示词网中结点的个数:vertexes = new LinkedList[charArray.length + 2],加2的原因是:起始顶点和结束顶点。
再将每个结点初始化,每个结点由一个LinkedList存储,值为空
for (int i = 0; i < vertexes.length; ++i)
{
vertexes[i] = new LinkedList<Vertex>();//待分词的句子的每个字符 对应的 LinkedList
}
最后将起始结点和结束结点初始化,LinkedList中添加进相应的顶点。
vertexes[0].add(Vertex.newB());//添加起始顶点
vertexes[vertexes.length - 1].add(Vertex.newE());//添加结束顶点
size = 2;//结点size
在添加起始顶点和结束顶点的时候,会从核心词典构建出一棵双数组树。比如,创建一个起始结点:
public static Vertex newB()
{
return new Vertex(Predefine.TAG_BIGIN, " ", new CoreDictionary.Attribute(Nature.begin, Predefine.MAX_FREQUENCY / 10), CoreDictionary.getWordID(Predefine.TAG_BIGIN));
}
每个顶点Vertex包括如下属性:
/**
* 节点对应的词或等效词(如未##数)
*/
public String word;
/**
* 节点对应的真实词,绝对不含##
*/
public String realWord;
/**
* 词的属性,谨慎修改属性内部的数据,因为会影响到字典<br>
* 如果要修改,应当new一个Attribute
*/
public CoreDictionary.Attribute attribute;
/**
* 等效词ID,也是Attribute的下标
*/
public int wordID;//CoreDictionary.txt 每个词的编号,从下标0开始
/**
* 在一维顶点数组中的下标,可以视作这个顶点的id
*/
public int index;//Vertex中 顶点的编号
下面来一 一解释Vertex类中各个属性的意义:
- 什么是等效词呢?可参考:[Bigram分词中的等效词串]。在PreDefine.java中就定义一些等效词串:
/**
* 结束 end
*/
public final static String TAG_END = "末##末";
/**
* 句子的开始 begin
*/
public final static String TAG_BIGIN = "始##始";
/**
* 数词 m
*/
public final static String TAG_NUMBER = "未##数";
也即句子的开始用符号"始##始"来表示,结束用"末##末"表示。也即前面提到的起始顶点和结束顶点。
另外,在分词过程中,会产生一些数量词,比如一人、两人……而这些数量词统一用"未##数"表示。为什么要这样表示呢?由于分词是基于n-gram模型的(n=2),一人、两人 这样的词统计出来的频率不太靠谱,导致在二元核心词典中找不到词共现频率,因此使用等效词串来进行处理。
-
真实词
String realWord真实词是待分词的文本字符。比如:“商品和服务”,真实词就是其中的每个char,“真”、“品”、“和”……
-
Attribute属性
记录这个词在一元核心词典中的词性、词频。由于一个词可能会有多个词性和词频,因此词性和词频都有一维数组来存储。
-
wordId
该词在一元核心词典中的位置(行号)
-
index
这个词在词网(词图)中的顶点的编号
构建双数组树过程
如果有bin文件,则直接是以二进制流的形式构建了一颗双数组树,否则从CoreNatureDictionary.txt中读取词典构建双数组中。关于双数组树的原理比较复杂,等以后彻底弄清楚了再来解释。
基于核心一元词典构建好了双数组树之后,就可以用双数组树来查询结点的wordId、词频、词性……信息,
return new Vertex(Predefine.TAG_BIGIN, " ", new CoreDictionary.Attribute(Nature.begin, Predefine.MAX_FREQUENCY / 10), CoreDictionary.getWordID(Predefine.TAG_BIGIN));CoreDictionary.getWordID(Predefine.TAG_BIGIN)//查询得到一元词典中该结点所代表的字符对应的wordId至此,创建了一个Vertex对象。
WordNet wordNetAll = new WordNet(sentence);只是(初始化了)生成了词网中的顶点,为各个顶点分配了存储空间,并初始化了起始结点和结束结点。接下来,需要初始化待分词的文本中的各个字符了。GenerateWordNet(wordNetAll);生成完整的词网。生成完整词网
生成完整词网的流程是:根据待分词的文本 使用双数组树 对一元核心词典进行 最大匹配查询,将命中的词创建一个Vertex对象,然后添加到词网中。
while (searcher.next()) { wordNetStorage.add(searcher.begin + 1, new Vertex(new String(charArray, searcher.begin, searcher.length), searcher.value, searcher.index)); }具体举例来说:假设待分词的文本是"商品和服务",首先将该文本分解成单个的字符。

然后,对每一个单个的字符,在双数组树(基于一元核心词典构建的)中进行最大匹配查找:
对于 '商' 而言,最大匹配查找得到:'商'--->‘商品’
对于'品'而言,最大匹配查找得到:'品'
对于'和’而言,最大匹配查找得到:'和'--->'和服'
对于'服'而言,最大匹配查找得到:'服'--->'服务'
对于'务'而言,最大匹配查找得到:'务'
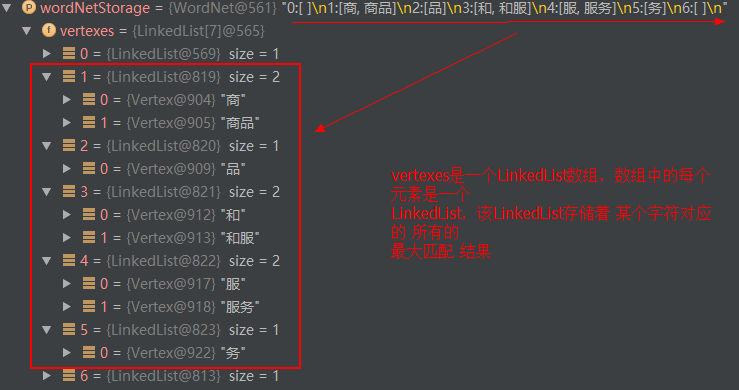
下面来具体分析 '商' 这个顶点是如何构建的:
由于'商'这个字存在于一元核心词典中
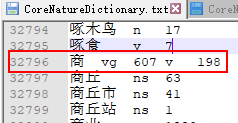
searcher.next()肯定会命中了'商' ,于是查找到了双数组树中'商'这个顶点的所有信息:
wordID:32769
词性vg,对应的词频是607;词性v对应的词频是198
因此,将双数组树中的顶点信息提取出来,用来构建 '商' 这个Vertex对象,并将之加入到LinkedList中
public Vertex(String word, String realWord, CoreDictionary.Attribute attribute, int wordID)
{
if (attribute == null) attribute = new CoreDictionary.Attribute(Nature.n, 1); //attribute为null,就赋一个默认值 安全起见
this.wordID = wordID;
this.attribute = attribute;
//初始时,所有词的等效词串word=null,当碰到数词/地名...时, 会为这些词生成等效词串.
if (word == null) word = compileRealWord(realWord, attribute);//1人 或者 2人 这样的词,转化为:未##数@人
assert realWord.length() > 0 : "构造空白节点会导致死循环!";
this.word = word;
this.realWord = realWord;
}
compileRealWord()函数的作用是:当碰到数量词……生成等效词串
同理,下一步从双数组树中找到词是'商品',类似地,构建'商品'这个Vertex对象,并将之添加到LinkedList下一个元素。
关于词图的生成,可参考:词图的生成。词图中建立各个节点之间的联系,是通过文章中提到的快速offset法实现的。其实就是通过快速offset法来寻找某个节点的下一个节点。因为后面会使用基于动态规划的维特比算法来求解词图的最短路径,而求解最短路径就需要根据某个节点快速定位该节点的后继节点。
下面,以 商品和服务为例,详细解释一下快速offset法:
| 0 始##始 | |
|---|---|
| 1 商 | 商品 |
| 2 品 | |
| 3 和 | 和服 |
| 4 服 | 服务 |
| 5 务 | |
| 6 末##末 |
上表可用一个LinkedList数组存储。每一行代表一个LinkedList,存储该字符最大匹配到的所有结果。这与图:词图的链接表示 是一致的。使用这种方式存储词图,不仅简单而且也易于查找下一个词。
-
从词网转化成词图
然后,接下来是:原子分词,保证图连通。这一部分,不是太理解
// 原子分词,保证图连通 LinkedList<Vertex>[] vertexes = wordNetStorage.getVertexes(); for (int i = 1; i < vertexes.length; ) { if (vertexes[i].isEmpty()) { int j = i + 1; for (; j < vertexes.length - 1; ++j) { if (!vertexes[j].isEmpty()) break; } wordNetStorage.add(i, quickAtomSegment(charArray, i - 1, j - 1)); i = j; } else i += vertexes[i].getLast().realWord.length(); }至此,得到一个粗分词网,如下:

构建好了词图之后,有了词图中各条边以及边上的权值。接下来,来到了基于动态规划的维特比分词,使用维特比算法来求解最短路径。
动态规划之维特比分词算法
List<Vertex> vertexList = viterbi(wordNetAll);计算顶点之间的边的权值
先把词图画出来,如下:
nodes数组就是用来存储词图的链表数组:
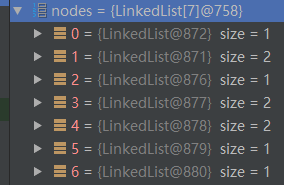
计算起始顶点的权值
起始顶点"始##始"到第一层顶点"商"和"商品"的权值:
//始##始 到 第一层顶点之间的 边以及权值 构建 for (Vertex node : nodes[1]) { node.updateFrom(nodes[0].getFirst()); }需要注意的是,每个顶点Vertex的weight属性,保存的是从起始顶点到该顶点的最短路径。
public void updateFrom(Vertex from) { double weight = from.weight + MathTools.calculateWeight(from, this); if (this.from == null || this.weight > weight)//this.weight>weight 表明寻找到了一条比原路径更短的路径 { this.from = from;//记录 更短路径上 的前驱顶点,用来回溯得到最短路径上的节点 this.weight = weight;//记录 更短路径 的权值 } }updateFrom()方法实现了动态规划自底向上计算最短路径。当计算出的weight比当前顶点的路径this.weight还要短时,就意味着找到一条更短的路径。
路径上的权值的计算
MathTools.calculateWeight()方法计算权值。这个权值是如何得出的呢?这就涉及到核心二元词典CoreNatureDictionary.ngram.txt了。
int nTwoWordsFreq = CoreBiGramTableDictionary.getBiFrequency(from.wordID, to.wordID);会开始加载核心二元词典CoreNatureDictionary.ngram.txt到内存中,然后查找这两个词:from@to 的词共现频率。显然,这里的词典采用了延迟加载的模式,也即当需要查询词共现频率的时候,才会去加载核心二元词典,从词典中找到对应的频率。比如 始##始@商 即表示:语料中以第一个字'商'开头的频率是46
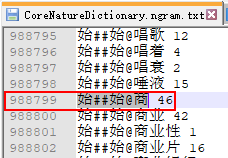
有了从一元核心词典中查询到的单个词的词频,以及两个词之间的词共现频率,就可以计算“概率”了。(背后的思想是贝叶斯概率,并且需要进行平滑)。关于平滑,可参考这个issue
double value = -Math.log(dSmoothingPara * frequency / (MAX_FREQUENCY) + (1 - dSmoothingPara) * ((1 - dTemp) * nTwoWordsFreq / frequency + dTemp));
计算其他顶点的权值
for (int i = 1; i < nodes.length - 1; ++i)
{
LinkedList<Vertex> nodeArray = nodes[i];
if (nodeArray == null) continue;
for (Vertex node : nodeArray)//当前节点为 node
{
if (node.from == null) continue;
for (Vertex to : nodes[i + node.realWord.length()])//获取当前节点 node的下一个节点 to
{
to.updateFrom(node);
}
}
}
看updateFrom()方法,通过比较节点的权重(权重代表着概率),更新最优路径上的节点(DP求解最优路径)
public void updateFrom(Vertex from)
{
double weight = from.weight + MathTools.calculateWeight(from, this);
if (this.from == null || this.weight > weight)//DP求解 2-gram 概率最大的路径
{
this.from = from;
this.weight = weight;
}
}
最终生成的词图如下:

以"商品"节点为例,它的下一个节点有两个:"和服" 、 "和"
| 0 始##始 | |
|---|---|
| 1 商 | 商品 |
| 2 品 | |
| 3 和 | 和服 |
| 4 服 | 服务 |
| 5 务 | |
| 6 末##末 |
"商品"的行号为1,长度为2,那么它的下一个节点存储在行号为 1+2 =3 的链表中。
同理,"品"的行号为2,长度为1,那么它的下一个节点存储在行号为2+1=3的链表中。
从上面的词图中可验证:节点"商品"的下一个节点是"和" 、"和服",正确无误。
最终,计算出起始顶点到词图中各个顶点的最短路径的权值。然后从结束顶点开始,回溯,找到最短路径上的各个结点。
Vertex from = nodes[nodes.length - 1].getFirst();//最后一个顶点的from属性记录着到达该顶点的前缀顶点
while (from != null)
{
vertexList.addFirst(from);
from = from.from;//weight属性是最短路径的权值,所以直接回溯就能得到最短路径上的各个结点
}
return vertexList;
现在已经通过维特比算法求得最短路径上的结点,可使用用户自定义的词典合并结果。这里的使用用户自定义词典合并结果的原理,有待进一步研究。(可参考:)
if (config.useCustomDictionary)
{
if (config.indexMode > 0)
combineByCustomDictionary(vertexList, wordNetAll);
else combineByCustomDictionary(vertexList);
}
至此,粗分结果完毕。粗分结果如下:
粗分结果[商品/n, 和/cc, 服务/vn]
粗分完成之后,根据Config中的相应配置:是否开启数字识别、NER命名识别、将最终的最短路径上的分词结果输出。
return convert(vertexList, config.offset);
从而,最终的分词结果如下:
[商品/n, 和/cc, 服务/vn]