谈谈 Callable 任务是怎么运行的?它的执行结果又是怎么获取的?
向线程池提交Callable任务,会创建一个新线程(执行任务的线程)去执行这个Callable任务,但是通过Future#get获取任务的执行结果是在提交任务的调用者线程中,那问题一:调用者线程如何获取执行任务的线程的结果?
在JDK中,有2种类型的任务,Runnable和Callable,但是具体到线程池执行任务的java.util.concurrent.ThreadPoolExecutor#execute(Runnable)方法,它只接收Runnable任务,那问题二:Callable任务是提交给线程池后是如何执行的呢?
Callable 任务是怎么运行的?
import java.util.concurrent.*;
public class FutureTest {
public static void main(String[] args) {
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
//sleep 是为了调试方便
TimeUnit.SECONDS.sleep(4);
return 3;
}
};
//创建一个 ThreadPoolExecutor 对象
ExecutorService executorService = Executors.newFixedThreadPool(1);
Future<Integer> future = executorService.submit(callable);
try {
Integer i = future.get();
System.out.println(i);
} catch (Exception e) {
System.out.println(e);
}
}
}
Future<Integer> future = executorService.submit(callable);
//java.util.concurrent.AbstractExecutorService#submit(java.util.concurrent.Callable<T>)
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
//FutureTask其实是个RunnableFuture, RunnableFuture其实是个Runnable
//重点是: Runnable#run方法的执行,其实就是 FutureTask#run方法的执行!!!
RunnableFuture<T> ftask = newTaskFor(task);
//java.util.concurrent.ThreadPoolExecutor#execute
execute(ftask);
return ftask;
}
RunnableFuture<T> ftask = newTaskFor(task);
//java.util.concurrent.AbstractExecutorService#newTaskFor(java.util.concurrent.Callable<T>)
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
当submit一个Callable任务时,会生成一个RunnableFuture接口对象,默认情况下 RunnableFuture对象是一个FutureTask对象。看java.util.concurrent.AbstractExecutorService类的源码注释:我们也可以重写 newTaskFor 方法生成我们自己的 RunnableFuture。一个具体的示例可参考ES源码org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor#newTaskFor(java.util.concurrent.Callable<T>),它就重写了 newTaskFor 方法,实现了执行优先级任务时,获取任务执行结果的逻辑。
the implementation of submit(Runnable) creates an associated RunnableFuture that is executed and returned. Subclasses may override the newTaskFor methods to return RunnableFuture implementations other than FutureTask
然后再来看FutureTask这个类的run()方法:java.util.concurrent.FutureTask#run,它会触发执行我们定义的Callable#call()方法。搞清楚java.util.concurrent.FutureTask#run方法是怎么被调用的,就搞清楚了线程池执行Callable任务的原理。该方法主要是做了2件事:
- 执行Callable#call方法,即:FutureTest.java中 我们定义的处理逻辑:返回一个Integer 3
- 设置任务的执行结果:
set(result)
java.util.concurrent.AbstractExecutorService#submit(java.lang.Runnable) 中execute(ftask)提交任务(注意:FutureTask implements Runnable)
ThreadPoolExecutor是AbstractExecutorService具体实现类,因此最终会执行到:java.util.concurrent.ThreadPoolExecutor#execute提交任务。
//java.util.concurrent.ThreadPoolExecutor#execute, 重点看addWorker()实现
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
java.util.concurrent.ThreadPoolExecutor#addWorker 有2行代码很关键:
//java.util.concurrent.ThreadPoolExecutor#addWorker
try {
w = new Worker(firstTask);//关键代码1, firstTask 本质上是 FutureTask对象
final Thread t = w.thread;
if (t != null) {
//...省略非关键代码
if (workerAdded) {
t.start();//关键代码 2
workerStarted = true;
}
}
}
w = new Worker(firstTask)创建一个新线程!把Worker作为this对象传进去,因为Worker implements Runnable,并且实现了java.lang.Runnable#run方法。
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;//
this.thread = getThreadFactory().newThread(this);
}
这意味着啥?执行java.lang.Runnable#run 就会去真正地执行 java.util.concurrent.ThreadPoolExecutor.Worker#run,那么java.lang.Runnable#run是被谁调用的呢?
聪明的你一定知道了,new Thread(Runnable).start()执行时,会由jvm去自动调用java.lang.Runnable#run
所以,上面java.util.concurrent.ThreadPoolExecutor#addWorker 中的关键代码2 t.start();,触发了java.util.concurrent.ThreadPoolExecutor.Worker#run的调用。
java.util.concurrent.ThreadPoolExecutor.Worker#run里面只是调用了runWoker(this)而已。
//java.util.concurrent.ThreadPoolExecutor.Worker#run
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
重点来了!再跟进去看看runWoker是何方神圣:
//java.util.concurrent.ThreadPoolExecutor#runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;//task 实际上是FutureTask类型的对象
w.firstTask = null;
try {
while (task != null || (task = getTask()) != null) {
//省略一些 非关键代码....
try {
beforeExecute(wt, task);//
try {
//重点代码!触发 java.util.concurrent.FutureTask#run 执行
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
//去看看afterExecute方法注释,无论线程执行过程中是否抛异常,afterExecute()都会 执行,看了源码,明白为什么是这样了,因为catch异常处理里面会执行afterExecute
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
看懂了java.util.concurrent.ThreadPoolExecutor#runWorker几乎就明白线程池执行任务时的beforeExecute、afterExecute方法的所起的作用了(比如经常在afterExecute方法里面做一些线程池任务运行时间的统计工作)。
总结以下点:
-
Callable任务被submit时,会生成一个FutureTask对象,封装Callable,在FutureTask的run方法里面执行Callable#call方法,并且调用
java.util.concurrent.FutureTask#set设置Callable任务的执行结果(结果保存在一个FutureTask的Object类型的实例变量里面:private Object outcome;)。 -
Future<Integer> future = executorService.submit(callable);返回一个Future,它实际上是一个FutureTask对象,通过java.util.concurrent.FutureTask#get()获取Callable任务的执行结果。 -
java.util.concurrent.FutureTask#run方法是由java.util.concurrent.ThreadPoolExecutor#runWorker触发调用的;而java.util.concurrent.ThreadPoolExecutor#runWorker又是由java.util.concurrent.ThreadPoolExecutor.Worker#run触发调用的;而java.util.concurrent.ThreadPoolExecutor.Worker#run又是由java.util.concurrent.ThreadPoolExecutor#addWorker里面的t.start();这条语句触发调用的;而t.start();会触发Runnable#run方法的执行。这就是前面提到的这个原理:new Thread(Runnable).start()会由jvm来调用Runnable#run。具体可参考:用一个词表示就是多态。用一张图表示就是:
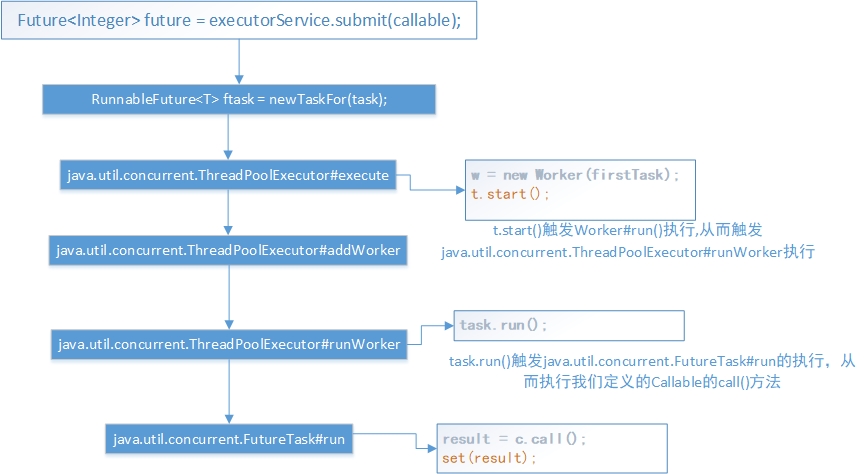
-
继承 ThreadPoolExecutor 实现自定义的线程池时,可重写 afterExecute()方法做一些异常处理逻辑的实现,不管任务正常执行完成、还是抛出异常,都会调用afterExecute(),具体可看JDK源码关于ThreadPoolExecutor#runWorker方法的注释。有兴趣可研究下ES SEARCH线程池源码就使用afterExecute来统计提交给线程池的每个任务的等待时间、执行时间,从而根据Little's law 自动调整线程池任务队列的长度:
org.elasticsearch.common.util.concurrent.QueueResizingEsThreadPoolExecutor#afterExecute
最后,想说的是:Callable任务,到ThreadPoolExecutor线程池执行 层面,它实际上是一个Runnable任务在执行。因为,ExecutorService submit Callable时,其实是将Callable封装到FutureTask/RunnableFuture中,而RunnableFuture implements Runnable,因此可以提交给线程池的java.util.concurrent.ThreadPoolExecutor#execute(Runnable command)执行,这就回答了本文开头提出的第二个问题。
//java.util.concurrent.RunnableFuture
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
用一张图表示就是:

Callable任务的设置与获取,则都是在FutureTask这个层面上完成,把Callable封装到FutureTask中,而FutureTask implements Runnable,从而转化成ThreadPoolExecutor#execute执行Runnable任务。
Callable任务的执行结果又是怎么获取的?Future.get为什么会阻塞?
java.util.concurrent.FutureTask 的private volatile int state;变量:
//java.util.concurrent.FutureTask#run
public void run() {
if (state != NEW ||
!RUNNER.compareAndSet(this, null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//Callable#call执行成功, ran=true
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
//ran=true,才会设置Callable任务的执行结果
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
set方法设置Callable任务的执行结果时,会修改 FutureTask的 state 实例变量的值!
//java.util.concurrent.FutureTask#set
protected void set(V v) {
if (STATE.compareAndSet(this, NEW, COMPLETING)) {
outcome = v;
STATE.setRelease(this, NORMAL); // final state
finishCompletion();
}
}
而java.util.concurrent.FutureTask#get()方法,也正是通过检查 state 的值,来确定是否能够拿到Callable任务的执行结果。
//java.util.concurrent.FutureTask#get()
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
//如果 state 不是在 NORMAL 状态,FutureTask#get()就会阻塞
//这就是 java.util.concurrent.Future#get() 阻塞的原因
s = awaitDone(false, 0L);//这里面会调用:Thread.yield()、LockSupport.park(this)
return report(s);
}
java.util.concurrent.FutureTask#awaitDone
//java.util.concurrent.FutureTask#awaitDone
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
WaitNode q = null;
//省略一些无关代码...
for (;;) {//for循环一直检查任务的运行状态....直到可以"结束"
int s = state;
//state的值大于 COMPLETING 说明已经有Callable任务的结果了
//java.util.concurrent.FutureTask#set 设置了Callable任务的结果,修改了state的值
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
//COMPLETING 任务的运行状态是:正在执行中
else if (s == COMPLETING)
// We may have already promised (via isDone) that we are done
// so never return empty-handed or throw InterruptedException
Thread.yield();//挂起获取执行结果的线程(这就是Futur#get阻塞的原因)
else if (Thread.interrupted()) {
removeWaiter(q);//任务可能被中断了,当然就不需要等待获取执行结果了
throw new InterruptedException();
}
else if (q == null) {
if (timed && nanos <= 0L)
return s;
q = new WaitNode();
}
else if (!queued)
queued = WAITERS.weakCompareAndSet(this, q.next = waiters, q);
//java.util.concurrent.Future#get(long, java.util.concurrent.TimeUnit)超时阻塞的实现原理
else if (timed) {
final long parkNanos;
if (startTime == 0L) { // first time
startTime = System.nanoTime();
if (startTime == 0L)
startTime = 1L;
parkNanos = nanos;
} else {
long elapsed = System.nanoTime() - startTime;
if (elapsed >= nanos) {
removeWaiter(q);
return state;
}
parkNanos = nanos - elapsed;
}
// nanoTime may be slow; recheck before parking
if (state < COMPLETING)
LockSupport.parkNanos(this, parkNanos);
}
else
LockSupport.park(this);
}
}
总结一下:通过 state变量来判断Callable任务的执行结果是否已经生成。如果已经生成了执行结果,那么 java.util.concurrent.FutureTask#set会把结果放到private Object outcome;outcome这个变量中。然后设置state的值为NORMAL,那么java.util.concurrent.FutureTask#get()通过检查 state 的值,就能拿到执行结果了,当然了,如果执行结果还未生成,java.util.concurrent.FutureTask#awaitDone就会导致 get 阻塞。
将Happens-Before的程序顺序规则与其他某个顺序规则(监视器锁规则或者volatile变量规则)结合起来,从而对某个未被锁保护的变量的访问操作进行排序。那么,正如本文所分析的,某个未被锁保护的变量就是Callable任务的执行结果outcome,而state就是一个volation修饰的变量,通过修改/读写 volatile 变量的值(即任务的运行状态变量state),从而实现了设置任务执行结果与获取任务执行结果的排序---当一个线程调用set保存结果并且另一个线程调用get获取结果时,这2个线程是按照Happens-Before进行排序的,它们是基于volatile 修饰的state 变量实现的,背后的原理就是: volatile 变量规则 。
原理参考:《Java并发编程实战》第14章
最后的最后,留一个问题:由于JDK里面Future#get都是阻塞的,那有没有什么方法使得获取 Callable 任务的执行结果不阻塞?
看看Netty的源码?借鉴一下Listener回调机制。哈哈……