分布式中的 transaction log
在分布式系统中,有很多台node组成一个cluster,对于client 的一个写操作请求而言,在什么样的情况下,cluster告诉client此次写操作请求是成功的呢?
首先来定义一下什么是写操作成功?
假设有一个三节点的cluster,一个primary node,两个replica node如下图所示:
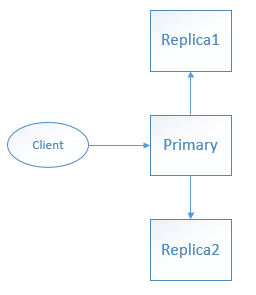
- 方案1. client 向primary发写请求,primary 将待写的数据持久化后,返回响应给client此次写操作成功,然后primary再将数据复制给其他两台replica node。
- 方案2. client 向primary发写请求,primary 将待写的数据 复制 到其他两台 replica node,等待 replic node将数据持久化后给primary响应,然后primary再返回响应给client此次写操作成功。
方案1,client有着良好的响应性,因为只需要primary持久化了,就给client响应;并发性更高,因为对于cluster而言,只需要primary持久化了,cluster 就算“暂时”成功处理了一个请求。
但是对于client而言,读操作就不方便了。因为,client要想读到最新的数据,读primary node是没问题的,但是读 replic node就有可能读不到最新的数据,因为:primary 还未来得及将最新的数据 复制到 replica 时,client向replica 发起了读数据请求,如下图所示:
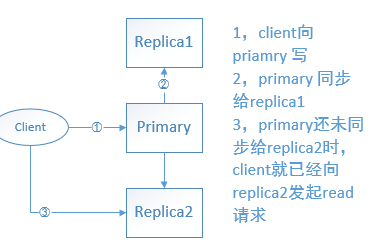
这样,client就读不到它刚才明明已经写入成功的数据了。
方案2,client 读取任何一台node都能读取到最新写入的数据,但是client的响应性不佳。
上面的讨论是从client角度、cluster角度来讨论的,还可以从数据的角度来讨论,就是数据是否被丢失。
一个cluster,一般是要接收大量的client的写请求的,如果来一个写请求,cluster就执行一次磁盘写操作(将数据持久化)那么性能应该是不佳的。因此,可以先将若干个写请求的数据都放到一个buffer中,然后等一段时间再批量将这些数据刷新到磁盘(sync)。
当引入了buffer,将写操作数据批量写磁盘 这种机制时,什么时候给client返回写操作成功的响应呢?是等若干个写操作数据批量同步到磁盘后,再给client返回写请求成功的响应、还是数据只是存储到所谓的buffer里面,就给client返回写操作成功的响应?而buffer的引入,又对 primary node 将数据 复制到 replica node 产生何种影响?
另外,就算真的不引入所谓的buffer,如果client的写操作很复杂、代价很大,难不成真的是要等数据持久化到磁盘才能给client响应成功吗?这种方式是不是有点与“并发控制 锁操作中的”悲观锁……
这个真的就不好说了,可能不同的产品有不同的实现细节吧。比如ElasticSearch、Mongodb
而当引入了buffer之后,由于将client的写操作数据都批量缓存起来了,那万一机器挂了,那这些缓存的数据就全丢失了,而如果client发一个请求,就同步一次磁盘,那处理性能又受到了影响,这似乎是一个两难的问题。
因此,为了解决这个问题,引入了一个叫“replication log”的概念。relication log有多种不同的实现方式,比如 write ahead log(WAL),而在ElasticSearch里面也有一个类似的东西,叫做transaction log(不知道我理解的对不对)
replication log的思想就是:针对client的写操作,生成一条日志,该日志详细记录了写操作对数据进行何种操作。一般日志只支持append操作的,一般地,相比于写数据操作、写日志要轻量级得多。另外日志还有个好处是:如果node在写操作过程中失败了,比如数据写到一半失败了,那及有可能造成数据的不一致性,那它还可以再读取日志,从日志中恢复出来。
下面来举个具体的例子,个人理解。
client 向 elasticsearch cluster 发起 index 操作。文档要分词,到Lucene底层要构造segment,生成 倒排索引(posting list)这种数据结构。这是一种“费时费力、代价很大的操作”,因此,不可能 针对 一篇文档一个index请求,就flush 一次segment。因此可以每隔一段时间、批量flush segment。而如果批量flush 的话,如果机器宕机了,那就会丢失很多数据。因此,es 引入了translog:
all the index/delete/update operations are written to the translog and the translog is fsynced after every index/delete/update operations to make sure the changes are persistent. the client receives acknowledgement for writes after the translog is fsynced on both primary and replic shards
写translog 应该要比 lucene segment flush 操作要轻量级得多。另外,primary shards 只需要将translog持久化、并同步给replica 后,就可以给client返回 写操作成功的响应了,这样可支持写操作的高并发。
总结
本文从三个角度:client、cluster、数据是否丢失 阐述了分布式中的读写一致性及数据可靠性。
- 节点之间的数据复制方式(同步复制、异步复制)是宏观上(针对的是各个node)的一种影响数据可靠性的因素
- replication log(transaction log)是一种微观上(针对的是具体的写操作)影响数据可靠性的因素
个人理解,可能有错。
原文:https://www.cnblogs.com/hapjin/p/9655879.html