我的相关博文
三种工厂模式详解
策略模式
在GOF的《设计模式:可复用面向对象软件的基础》一书中对策略模式是这样说的:
定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。该模式使得算法可独立于使用它的客户而变化。
策略模式为了适应不同的需求,只把变化点封装了,这个变化点就是实现不同需求的算法,例如加班工资,不同的加班情况,有不同的计算加班工资的方法。
我们不能在程序中将计算工资的算法进行硬编码,而能够自由变化。
这就是策略模式。
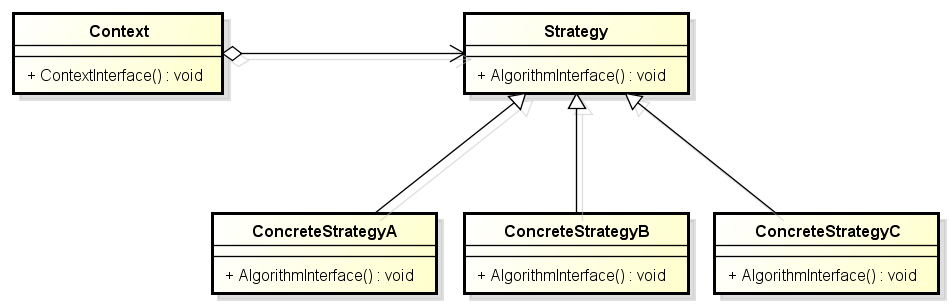

实验1 策略模式+简单工厂
代码
#include <iostream>
using namespace std;
// Define the strategy type
typedef enum StrategyType
{
StrategyA,
StrategyB,
StrategyC
}STRATEGYTYPE;
// The abstract strategy
class Strategy
{
public:
virtual void AlgorithmInterface(int x, int y) = 0;
virtual ~Strategy() = 0;
};
Strategy::~Strategy()
{}
class ConcreteStrategyA : public Strategy
{
public:
void AlgorithmInterface(int x, int y)
{
cout << "I am from ConcreteStrategyA: result=X+Y, = " << x+y << endl;
}
~ConcreteStrategyA(){
cout << "~ConcreteStrategyA()." << endl;
}
};
class ConcreteStrategyB : public Strategy
{
public:
void AlgorithmInterface(int x, int y)
{
cout << "I am from ConcreteStrategyB: result=X*Y, = " << x*y << endl;
}
~ConcreteStrategyB(){
cout << "~ConcreteStrategyB()." << endl;
}
};
class ConcreteStrategyC : public Strategy
{
public:
void AlgorithmInterface(int x, int y)
{
cout << "I am from ConcreteStrategyC: result=X-Y, = " << x-y << endl;
}
~ConcreteStrategyC(){
cout << "~ConcreteStrategyC()." << endl;
}
};
// 用户类 : 使用算法的用户
class Context
{
public:
// 该构造函数内使用简单工厂模式
Context(STRATEGYTYPE strategyType)
{
switch (strategyType)
{
case StrategyA:
pStrategy = new ConcreteStrategyA;
break;
case StrategyB:
pStrategy = new ConcreteStrategyB;
break;
case StrategyC:
pStrategy = new ConcreteStrategyC;
break;
default:
break;
}
}
~Context()
{
if (pStrategy)
delete pStrategy;
}
void ContextInterface(int x, int y) // 定义一个接口来让Stategy访问用户的数据
{
if (pStrategy)
pStrategy->AlgorithmInterface(x, y);
}
private:
Strategy *pStrategy; // 维护一个对Stategy对象的引用或指针
int a; // 私有数据,这是用户数据,该用户是独立于算法的用户,用户不需要了解算法内部的数据结构
int b;
};
int main()
{
Context *pContext = new Context(StrategyA);
pContext->ContextInterface(100, 6);
if (pContext)
delete pContext;
}
上述的例子是策略模式,我们还能看到一点简单工厂模式的影子。
百度到的绝大多数都是这种例子了。 这个代码完美吗?看下GoF的要领:

如果我们需要新增新的算法,我们需要修改Context类的构造函数,在里面新增新的算法,这显然不符合GoF采用扩展、子类化的精要。
所以引出了我下面的策略模式+抽象工厂的解决方案。
实验2 策略模式+抽象工厂
代码
#include <iostream>
using namespace std;
// The abstract strategy
class Strategy
{
public:
virtual void AlgorithmInterface(int x, int y) = 0;
virtual ~Strategy() = 0;
};
Strategy::~Strategy()
{}
class ConcreteStrategyA : public Strategy
{
public:
void AlgorithmInterface(int x, int y)
{
cout << "I am from ConcreteStrategyA: result=X+Y, = " << x+y << endl;
}
~ConcreteStrategyA(){
cout << "~ConcreteStrategyA().析够" << endl;
}
};
class ConcreteStrategyB : public Strategy
{
public:
void AlgorithmInterface(int x, int y)
{
cout << "I am from ConcreteStrategyB: result=X*Y, = " << x*y << endl;
}
~ConcreteStrategyB(){
cout << "~ConcreteStrategyB().析够" << endl;
}
};
class ConcreteStrategyC : public Strategy
{
public:
void AlgorithmInterface(int x, int y)
{
cout << "I am from ConcreteStrategyC: result=X-Y, = " << x-y << endl;
}
~ConcreteStrategyC(){
cout << "~ConcreteStrategyC().析够" << endl;
}
};
// 用户类 : 使用算法的用户
class Context
{
public:
Context(Strategy* paraStrategy)
{
pStrategy = paraStrategy;
}
~Context()
{
// 这里不需要析够pStrategy, pStrategy对应对象的析够会在delete pAbstractStrategyFactory时进行。
// 即,销毁具体某个策略工厂对象时会负责析够具体的策略对象。所以这里就不需要了。
}
void ContextInterface(int x, int y) // 定义一个接口来让Stategy访问用户的数据
{
if (pStrategy)
pStrategy->AlgorithmInterface(x, y);
}
private:
Strategy *pStrategy; // 维护一个对Stategy对象的引用或指针
int a; // 私有数据,这是用户数据,该用户是独立于算法的用户,用户不需要了解算法内部的数据结构
int b;
};
// 点评该类: 一条产品线下的产品,通常存在共性,
// 也就是说,维护一个对产品的抽象类通常是需要的,而不是必须的。
class AbstractStrategyFactory // 抽象工厂这里可以实现多个纯虚方法
{
public:
virtual Strategy* createStrategy(string Strategy)=0;
virtual ~AbstractStrategyFactory(){}
};
class StrategyA_Factory:public AbstractStrategyFactory
{
Strategy *pStrategy;
public:
StrategyA_Factory():pStrategy(NULL)
{}
Strategy* createStrategy(string Strategy)
{
if(Strategy == "StrategyA"){
pStrategy = new ConcreteStrategyA();
return pStrategy;
}
return NULL;
}
~StrategyA_Factory()
{
cout << "~StrategyA_Factory(). 析够" << endl;
if(pStrategy)
delete pStrategy;
}
};
class StrategyB_Factory:public AbstractStrategyFactory
{
Strategy *pStrategy;
public:
StrategyB_Factory():pStrategy(NULL)
{}
Strategy* createStrategy(string Strategy)
{
if(Strategy == "StrategyB"){
pStrategy = new ConcreteStrategyB();
return pStrategy;
}
return NULL;
}
~StrategyB_Factory()
{
if(pStrategy)
delete pStrategy;
}
};
class StrategyC_Factory:public AbstractStrategyFactory
{
Strategy *pStrategy;
public:
StrategyC_Factory():pStrategy(NULL)
{}
Strategy* createStrategy(string Strategy)
{
if(Strategy == "StrategyC"){
pStrategy = new ConcreteStrategyC();
return pStrategy;
}
return NULL;
}
~StrategyC_Factory()
{
if(pStrategy)
delete pStrategy;
}
};
int main(int argc, char *argv[])
{
AbstractStrategyFactory* pAbstractStrategyFactory; // 创建抽象工厂指针
pAbstractStrategyFactory = new StrategyA_Factory(); // 创建策略A的工厂
Strategy* pStrategy = pAbstractStrategyFactory->createStrategy("StrategyA"); //使用策略A工厂来生产出策略A
if(pStrategy == NULL)
{
cout << "pStrategy is NULL" << endl;
}
else
{
// 供用户来使用策略A : 用户使用策略A 和 策略A的实现,是松耦合的。
Context *pContext = new Context(pStrategy);
pContext->ContextInterface(100, 6);
delete pAbstractStrategyFactory;
if (pContext)
delete pContext;
}
return 0;
}
编译运行:

此时,如果要新增算法,那我觉得可以采用扩展、子类化的解决方案了,而不用像本博文上一个例子那样,去修改已有的代码了。
说大白话,如果要新增算法,现在只需要在已有代码基础上去新增新算法的相关代码,而不是去修改已经写好的一些函数的内部实现。
当然,这样的设计会导致代码量变大,所以一切都需要权衡,适合自己的就是最好的。
.