背景
领域驱动中关于聚合设计的原则一直存在一个模糊的定义,比如:不变量、一致性和一个边界。根据这些规则很难清晰的划分聚合,不排除聚合的设计有一定的艺术性,但是在限定的领域内或许有某种可以明确遵循的规则,前几天我好像思考到了这样一个规则,这里分享给大家,跪求批评。
规则(在基于关系数据库的领域,聚合的边界等于并发管理的边界。)
为了满足不变量和一致性,毫无疑问我们要采用并发管理。
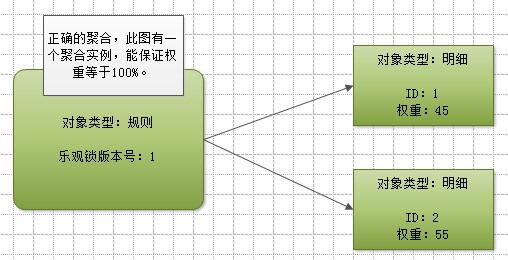
正确的聚合设计
下图中只有一个聚合实例,在聚合根中应用乐观锁保证聚合的一致性,一个聚合必须做为一个整体进行操作,如:客户端修改“明细”时,其加载和保存的JSON数据必须包含“聚合根”。
错误的聚合设计
下图中只有三个聚合实例,在聚合根中应用乐观锁保证聚合的一致性(注意是三个聚合),因为每个聚合都可以独立的操作,因此很难保证概念的一致性(明细的权重之和等于100%),比如:假如目前明细的权重之和还差10%,两个人同时添加一个10%的明细。这种设计不是不能保证概念的一致性,是需要额外的成本,如上面的问题:采用双验证(插入前后都进行一次验证)。

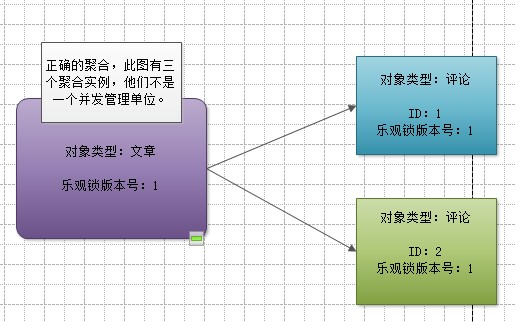
正确的聚合设计
多数对象之间不存在并发管理的需要(独自还是有这个需求的),像文章和评论之间是没有任何并发管理需求的,你不期望A发表评论的时候B就不能发表了或者你修改文章的时候别人不能发表评论了。
备注
聚合的设计也就是领域模型的设计是DDD的重点,我也没有太多经验可言(失败的倒是有),希望朋友们多给意见。