0x0前言:
带来一首小歌:
之前看了小迪老师讲的课,仔细做了些笔记
然后打算将其写成一个脚本。
0x01准备:
requests模块
socket模块
optparser模块
time模块
0x02笔记和思路:
笔记: 信息收集四大件 6.快速判断网站系统类型: 改一个网站后缀名文件,看它对大小写是否敏感 windows:不区分大小写 Linux:区分大小写 7.判断网站语言格式 看后缀 动态语言 疑问:伪静态该怎么判断 8.判断网站的数据库类型 端口扫描、 SQL报错注入 搭建分析 以下3种方法会导致探测数据库失败: 知识点: ACCESS:无端口 MYSQL:3306 MSSQL:1433 ORACLE:1521 1.内网服务器 (通过内网穿透将本机的东西眏射出来,就是转发某个端口(类似于ngrok)) 2.将数据库默认端口修改了 3.站库分离(网站源码和数据库不在一台服务器上) 9.判断网站架构 审查元素(F12)
判断系统的思路:
随便找一个网站的目录然后将其后缀其中一个改为大写
如果页面返回和原来一样的页面就是windows系统
如果页面返回和原来的页面不一样就是Linux系统
那我们也就可以知道了,返回也面的字节是不一样的
我们就可以写一个判断了
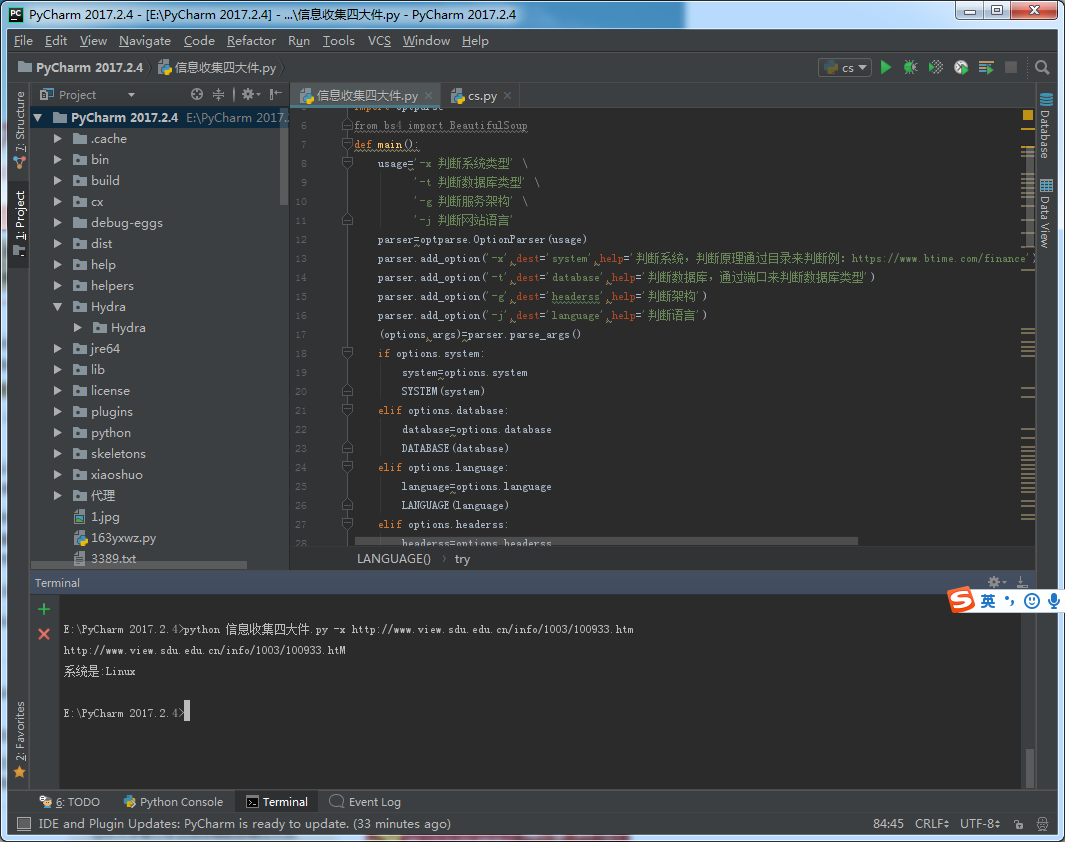
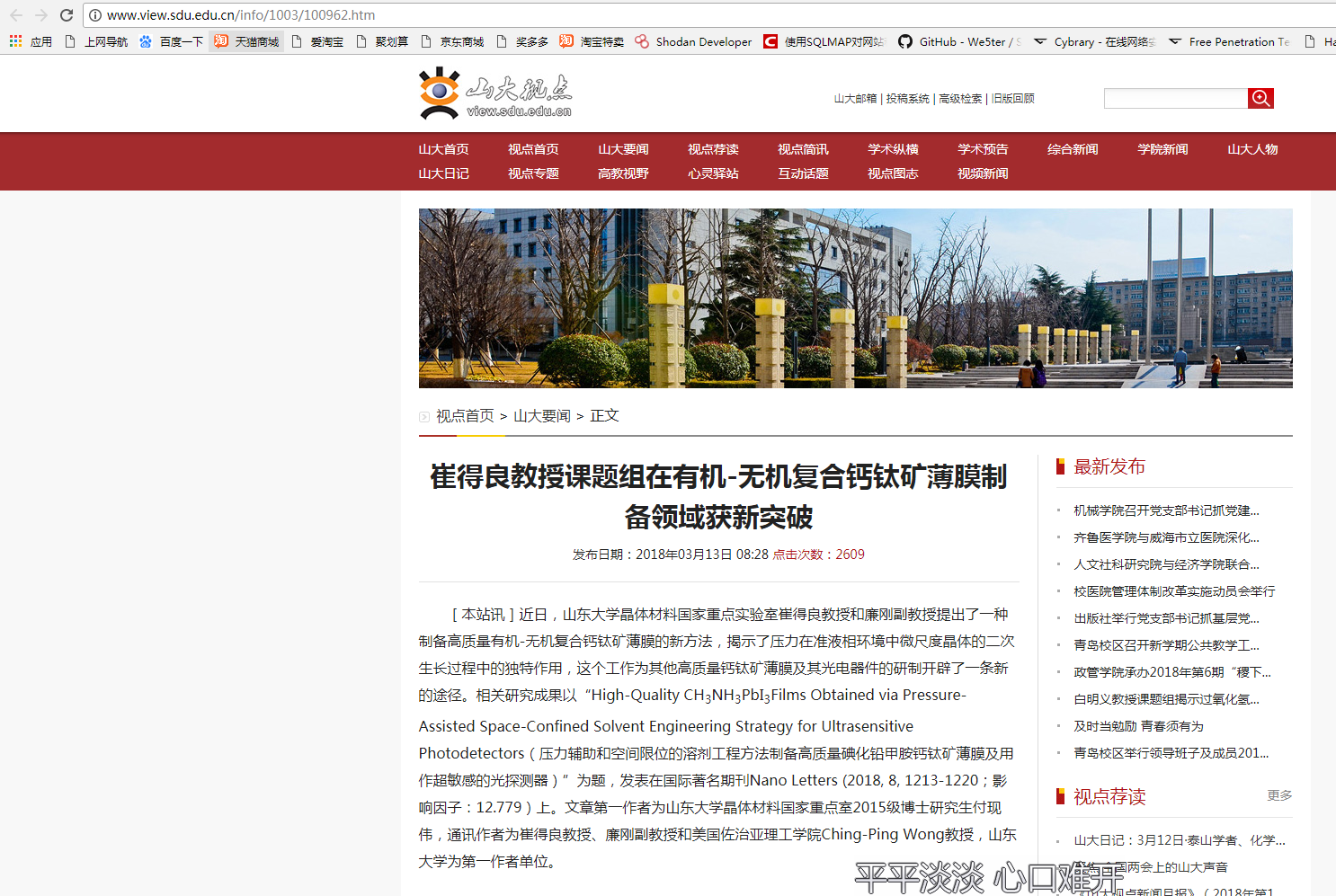
证实:
原来的页面
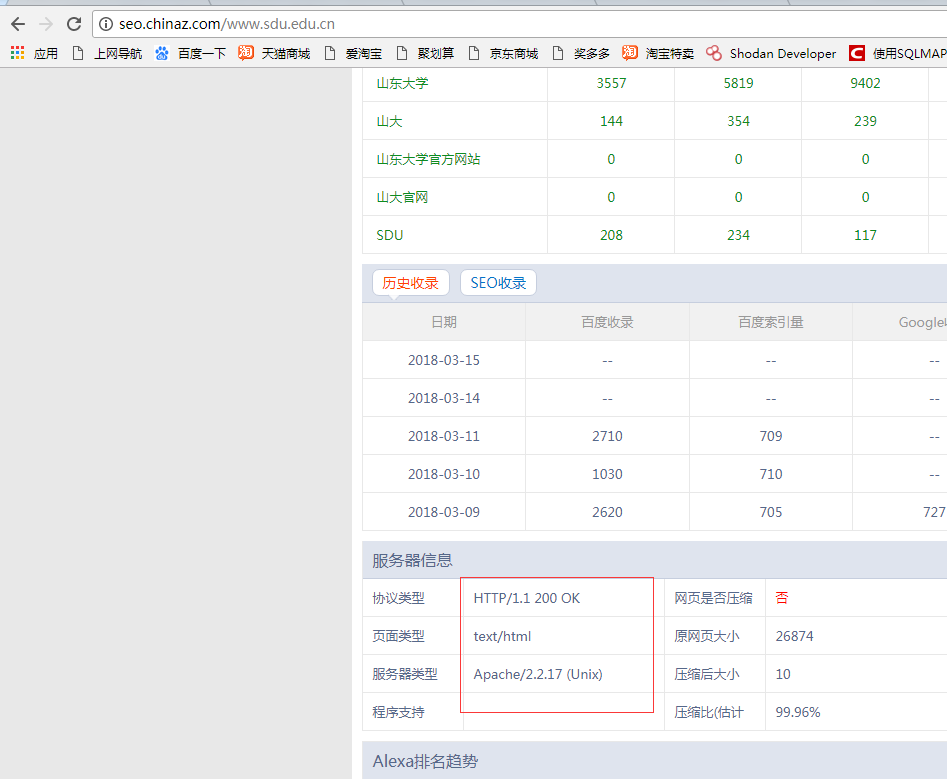
更改后缀最后一个字符

结果:返回的页面不一样,是Linux或者Unix
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
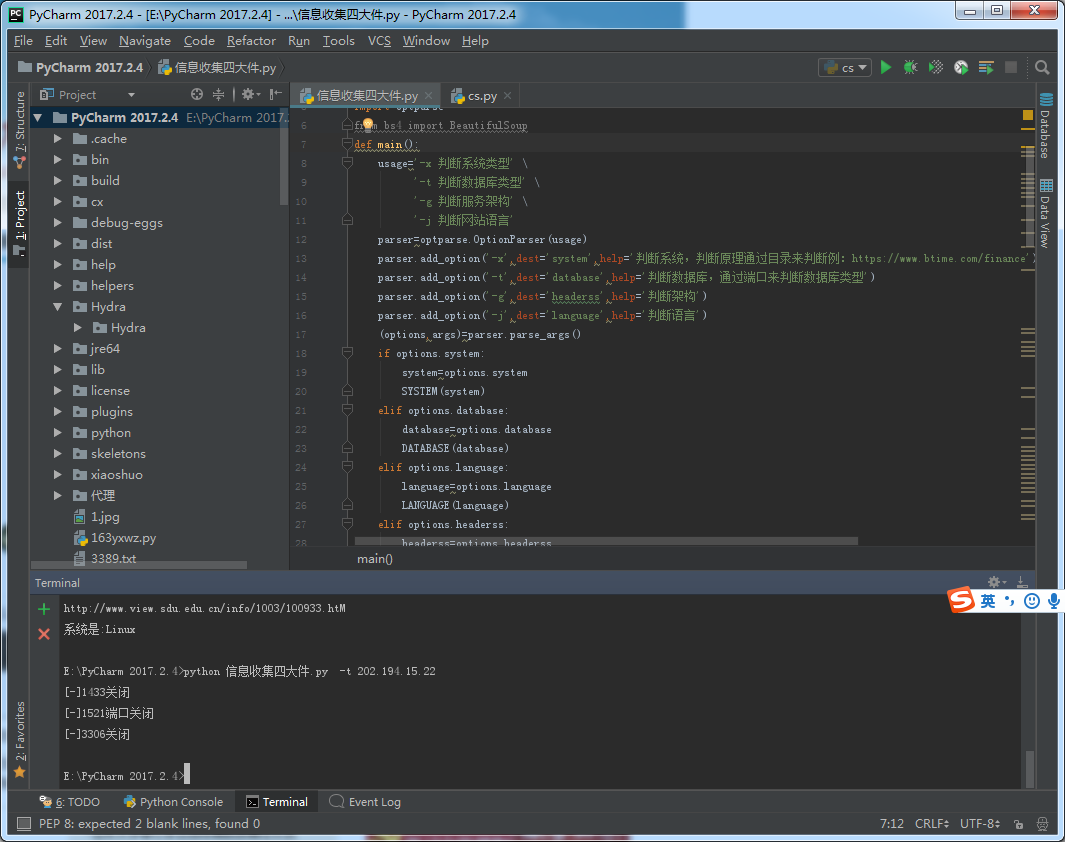
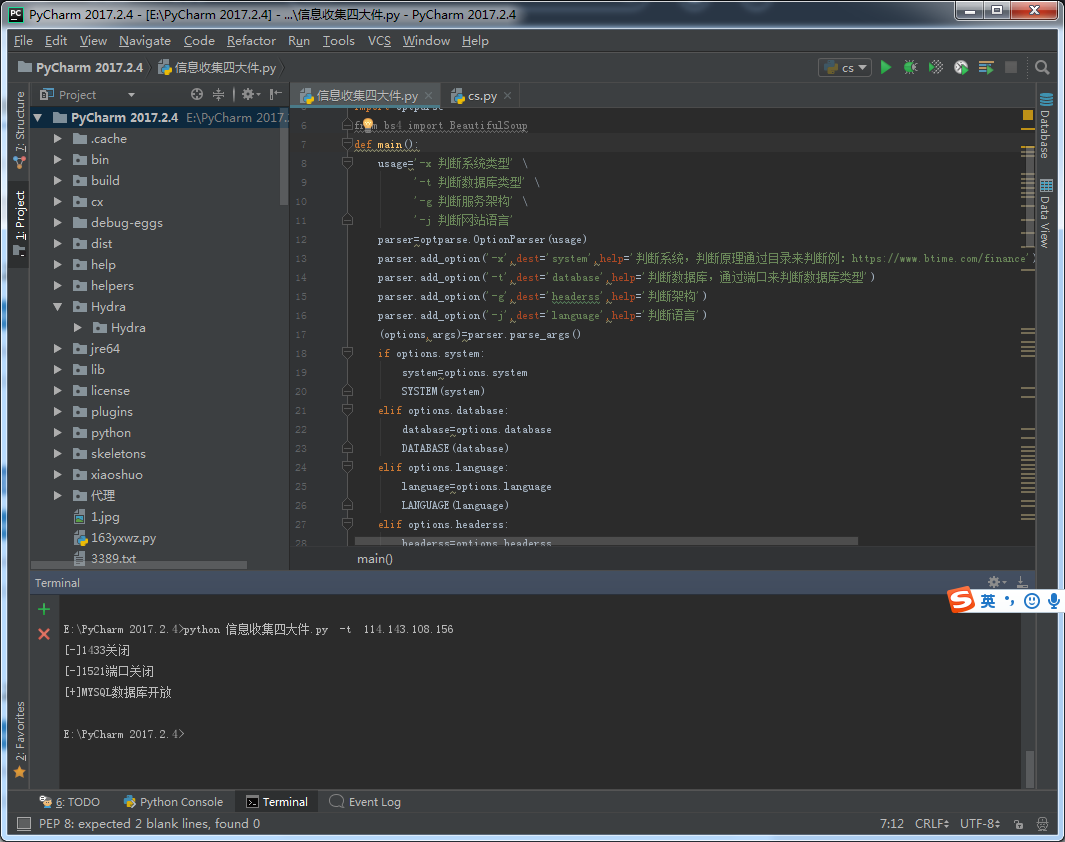
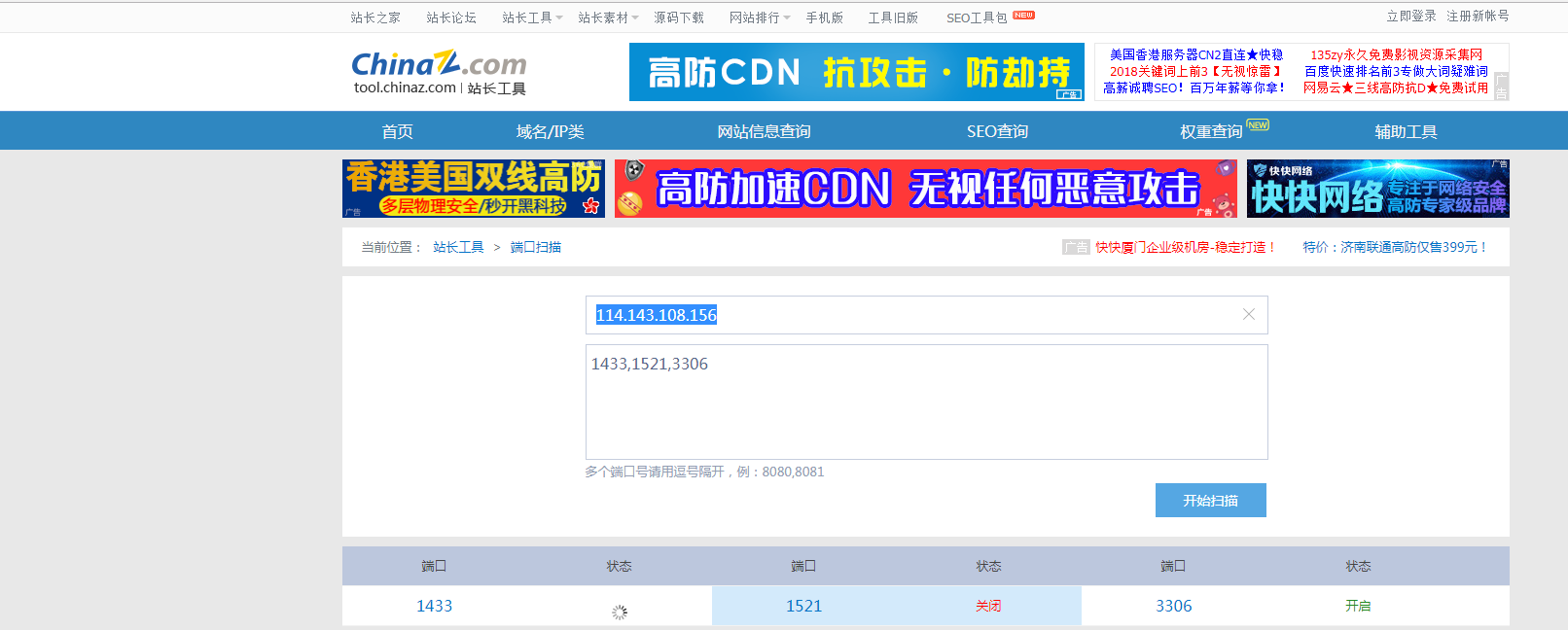
判断数据库类型思路:这里我采用端口判断,如果目标网站改了默认端口或站库分离是识别不出来的,到时候写个SQL注入的判断的脚本。
端口扫描用socket就能实现。
ACCESS:无端口 MYSQL:3306 MSSQL:1433 ORACLE:1521
--------------------------------------------------------------------------------------------------------------------------
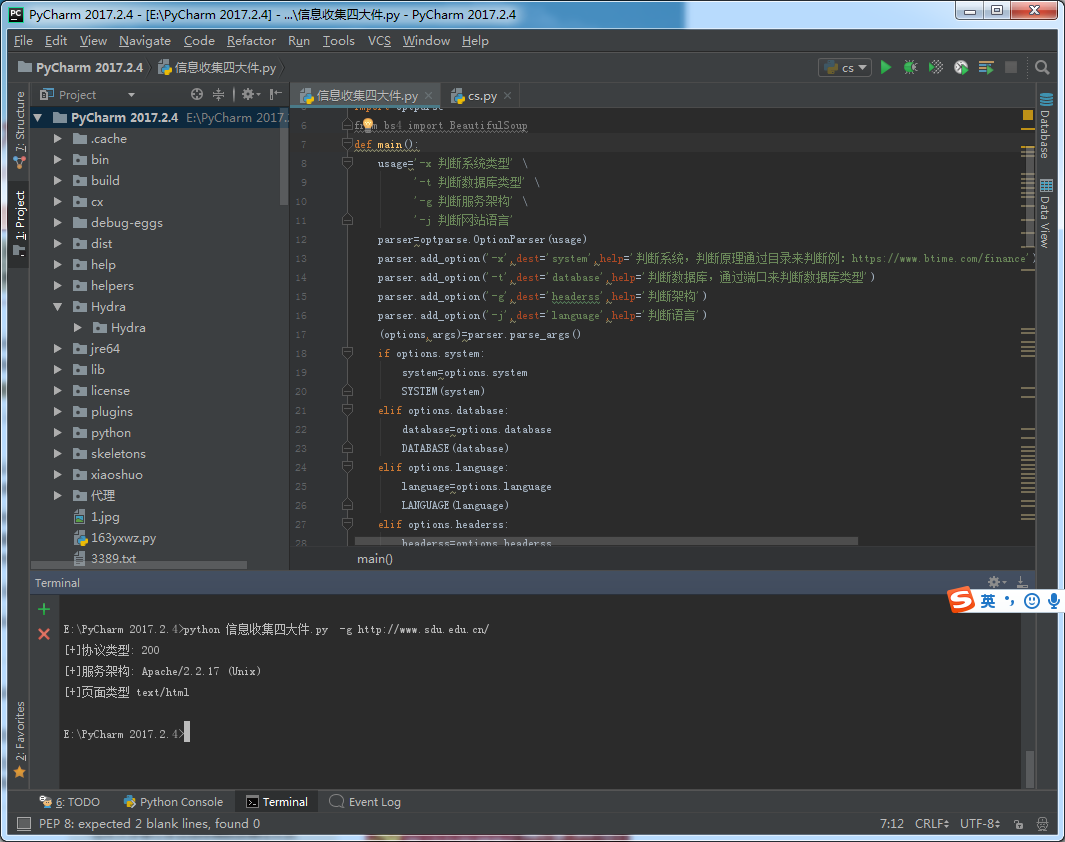
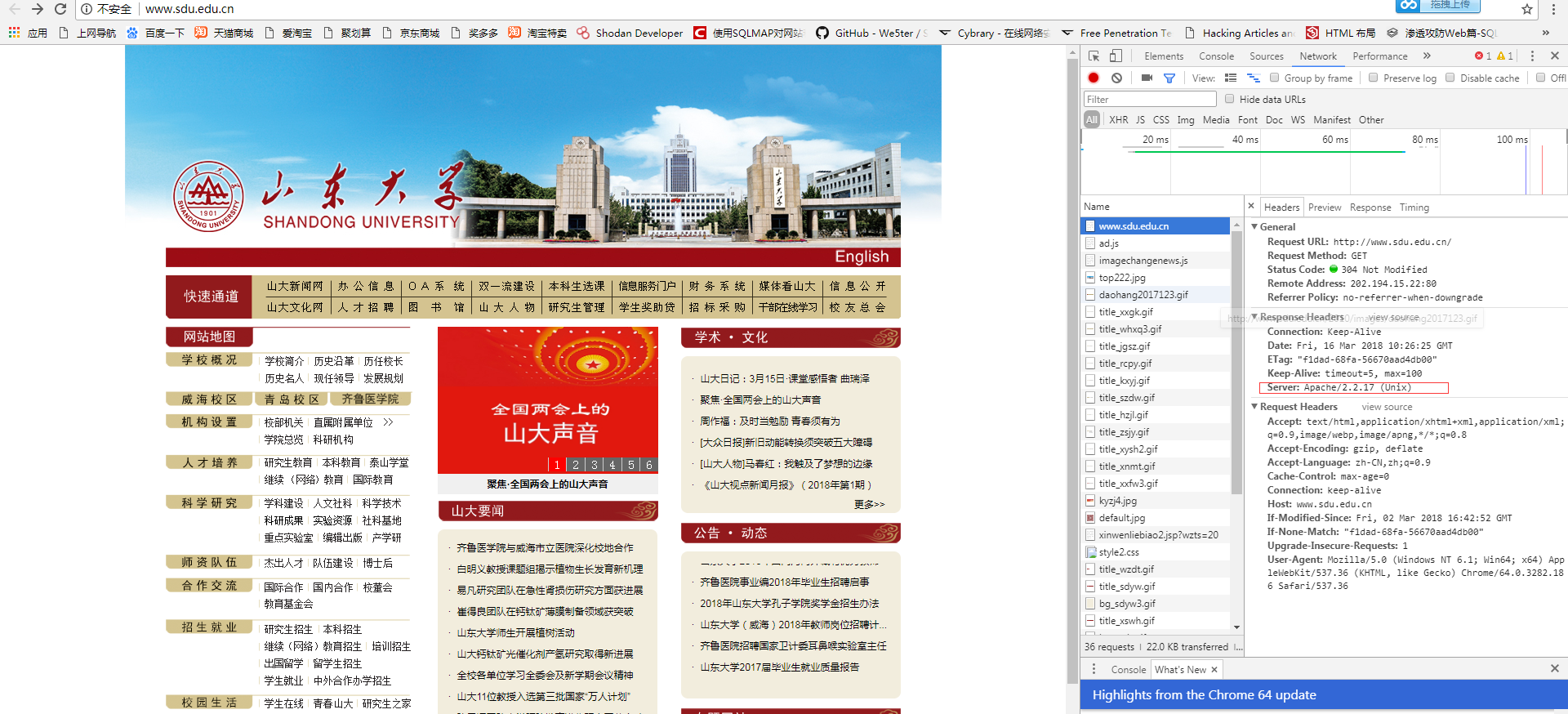
判断服务架构思路:看http响应头就行
0x03代码:
import requests
import os
import socket
import time
import optparse
from bs4 import BeautifulSoup
def main():
usage='-x 判断系统类型'
'-t 判断数据库类型'
'-g 判断服务架构'
'-j 判断网站语言'
parser=optparse.OptionParser(usage)
parser.add_option('-x',dest='system',help='判断系统,判断原理通过目录来判断例:https://www.btime.com/finance')
parser.add_option('-t',dest='database',help='判断数据库,通过端口来判断数据库类型')
parser.add_option('-g',dest='headerss',help='判断架构')
parser.add_option('-j',dest='language',help='判断语言')
(options,args)=parser.parse_args()
if options.system:
system=options.system
SYSTEM(system)
elif options.database:
database=options.database
DATABASE(database)
elif options.language:
language=options.language
LANGUAGE(language)
elif options.headerss:
headerss=options.headerss
HEADERSS(headerss)
else:
parser.print_help()
exit()
def SYSTEM(system):
sc = "{}".format(system)
gs = sc[-1].capitalize()
sw = sc.strip(sc[-1])
url = sw + gs
sg = requests.get(url)
print(sg.url)
a = requests.get(sc).content
b = requests.get(url).content
if a != b:
print('系统是:Linux')
else:
print('系统是:windows')
def DATABASE(database):
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
try:
s.settimeout(3)
s.connect((database,1433))
print('[+]MSSQL数据库开放')
except:
print('[-]1433关闭')
time.sleep(0.1)
try:
s.settimeout(3)
s.connect((database,1521))
print('[+]oracle数据库开放')
except:
print('[-]1521端口关闭')
time.sleep(0.1)
try:
s.settimeout(3)
s.connect((database,3306))
print('[+]MYSQL数据库开放')
except:
print('[-]3306关闭')
def HEADERSS(headerss):
url="{}".format(headerss)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
r=requests.get(url,headers=headers)
print('[+]协议类型:',url[0],url[1],url[2],url[3],'/',r.status_code)
print('[+]服务架构:',r.headers['Server'])
print('[+]页面类型',r.headers['Content-Type'])
def LANGUAGE(language):
url="{}".format(language)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
g=requests.get(url,headers=headers)
try:
print('[+]程序支持',g.headers['X-Powered-By'])
except:
print('[-]没有找出该网站的程序支持')
if __name__ == '__main__':
main()
脚本运行: