最近看了《Go并发编程实战》,学了最后一章的crawler。这是一个很好的demo, 设计功能完备,同时具有可扩展性。
根据学到的思路简单总结一下,同时重复发明一下轮子。
Version 01:
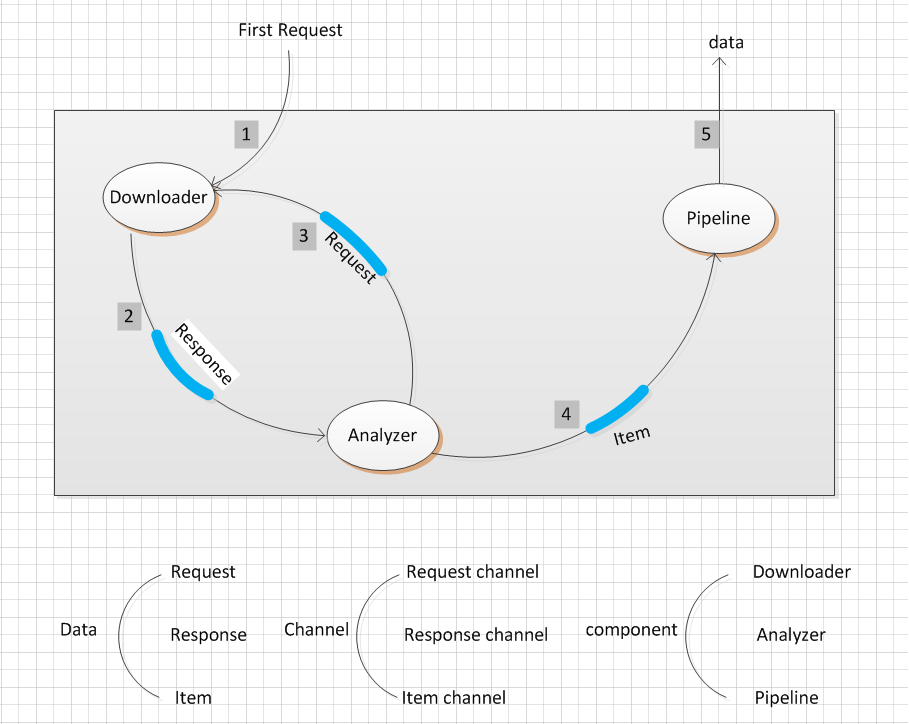
比如:我们想爬一下一个外贸网站所有的 商品。
其中,有三个component,
(1) Downloader, 用来根据根据 request中的URL下载对应的页面。
(2) Analyzer 分析下载下来的页面,提取其中的 商品信息,作为Item。 同时提取其中内部链接
(3) Pipeline 对应后处理, 我们可以对 Item信息做一系列后处理,比如提取 商品名称、分类、价格等信息。对数据结构化结构化等一系列操作。
我们需要三个channel 分别装载Request, Response, Item。
version 02:
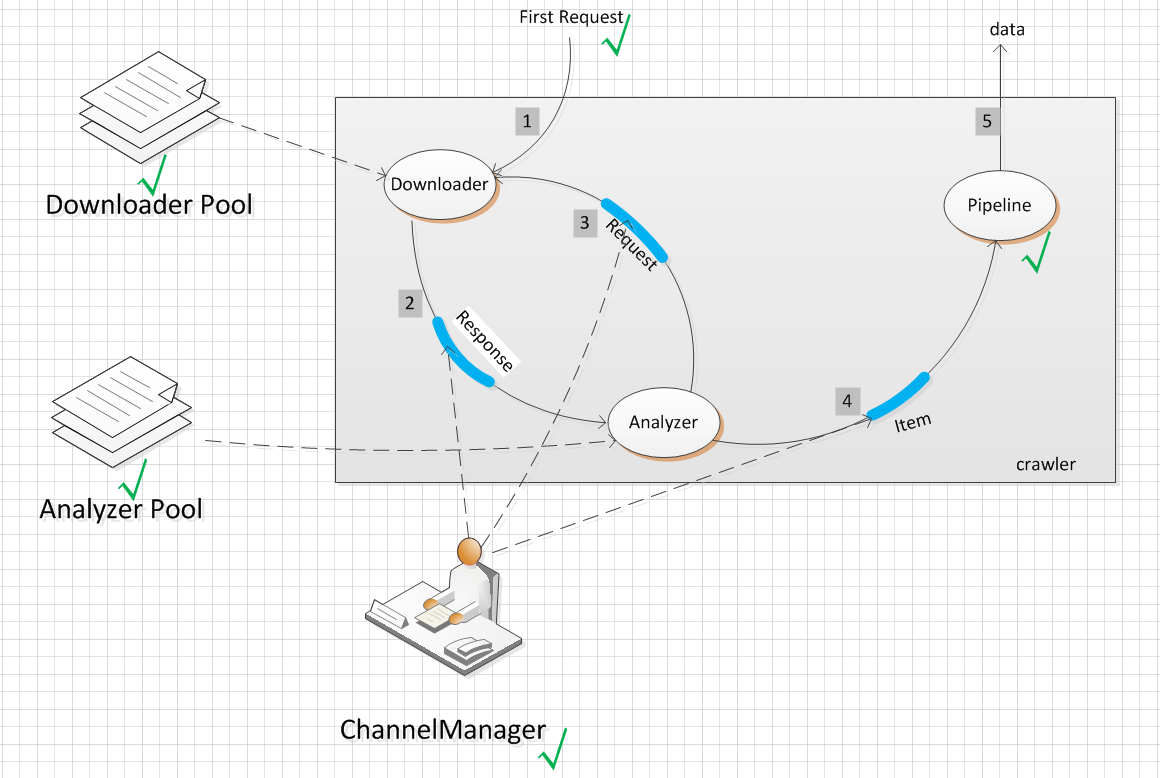
为了管理component, 我们引入了Pool;为了统一管理Channel,我们引入了ChannelManager。
我们只需要 图中打上 √ 的 组件来初始化我们的 crawler。
Version 03:
为了增加组建灵活性,Analyzer 中接受用户自定义处理函数,Piple 中接收用户自定义函数。
继续增加:
Log, error(包括time out) 处理
可以优雅的Start and Stop crawler