Power Network
| Time Limit: 2000MS | Memory Limit: 32768K | |
| Total Submissions: 23684 | Accepted: 12379 |
Description
A power network consists of nodes (power stations, consumers and dispatchers) connected by power transport lines. A node u may be supplied with an amount s(u) >= 0 of power, may produce an amount 0 <= p(u) <= pmax(u) of power, may consume an amount 0 <= c(u) <= min(s(u),cmax(u)) of power, and may deliver an amount d(u)=s(u)+p(u)-c(u) of power. The following restrictions apply: c(u)=0 for any power station, p(u)=0 for any consumer, and p(u)=c(u)=0 for any dispatcher. There is at most one power transport line (u,v) from a node u to a node v in the net; it transports an amount 0 <= l(u,v) <= lmax(u,v) of power delivered by u to v. Let Con=Σuc(u) be the power consumed in the net. The problem is to compute the maximum value of Con.
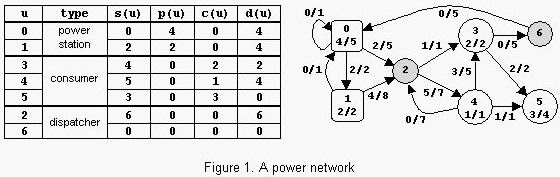
An example is in figure 1. The label x/y of power station u shows that p(u)=x and pmax(u)=y. The label x/y of consumer u shows that c(u)=x and cmax(u)=y. The label x/y of power transport line (u,v) shows that l(u,v)=x and lmax(u,v)=y. The power consumed is Con=6. Notice that there are other possible states of the network but the value of Con cannot exceed 6.
An example is in figure 1. The label x/y of power station u shows that p(u)=x and pmax(u)=y. The label x/y of consumer u shows that c(u)=x and cmax(u)=y. The label x/y of power transport line (u,v) shows that l(u,v)=x and lmax(u,v)=y. The power consumed is Con=6. Notice that there are other possible states of the network but the value of Con cannot exceed 6.
Input
There are several data sets in the input. Each data set encodes a power network. It starts with four integers: 0 <= n <= 100 (nodes), 0 <= np <= n (power stations), 0 <= nc <= n (consumers), and 0 <= m <= n^2 (power transport lines). Follow m data triplets (u,v)z, where u and v are node identifiers (starting from 0) and 0 <= z <= 1000 is the value of lmax(u,v). Follow np doublets (u)z, where u is the identifier of a power station and 0 <= z <= 10000 is the value of pmax(u). The data set ends with nc doublets (u)z, where u is the identifier of a consumer and 0 <= z <= 10000 is the value of cmax(u). All input numbers are integers. Except the (u,v)z triplets and the (u)z doublets, which do not contain white spaces, white spaces can occur freely in input. Input data terminate with an end of file and are correct.
Output
For each data set from the input, the program prints on the standard output the maximum amount of power that can be consumed in the corresponding network. Each result has an integral value and is printed from the beginning of a separate line.
Sample Input
2 1 1 2 (0,1)20 (1,0)10 (0)15 (1)20
7 2 3 13 (0,0)1 (0,1)2 (0,2)5 (1,0)1 (1,2)8 (2,3)1 (2,4)7
(3,5)2 (3,6)5 (4,2)7 (4,3)5 (4,5)1 (6,0)5
(0)5 (1)2 (3)2 (4)1 (5)4
Sample Output
15 6
哎、英语是硬伤、
上面的问题都是单源单汇问题,这题是多源多汇,关键在于把多源多汇问题转化为单源单汇,只要构造一个超级源点和一个超级汇点就行了,把超级源点和各个源点之间加一条边,把各个汇点和超级汇点之间加一条边。
EK算法:
#include <iostream> #include <cstdio> #include <cstring> #include <queue> #include <map> #include <string> using namespace std; #define INF 0x3f3f3f3f #define N 110 int n; int src; int des; int p,c,l; int pre[N]; int mpt[N][N]; queue<int> q; int bfs() { while(!q.empty()) q.pop(); memset(pre,-1,sizeof(pre)); pre[src]=0; q.push(src); while(!q.empty()) { int u=q.front(); q.pop(); for(int v=1;v<=n;v++) { if(pre[v]==-1 && mpt[u][v]>0) { pre[v]=u; if(v==des) return 1; q.push(v); } } } return 0; } int EK() { int maxflow=0; while(bfs()) { int minflow=INF; for(int i=des;i!=src;i=pre[i]) minflow=min(minflow,mpt[pre[i]][i]); maxflow+=minflow; for(int i=des;i!=src;i=pre[i]) { mpt[i][pre[i]]+=minflow; mpt[pre[i]][i]-=minflow; } } return maxflow; } int main() { while(scanf("%d",&n)!=EOF) { n+=2; src=1; des=n; memset(mpt,0,sizeof(mpt)); scanf("%d%d%d",&p,&c,&l); for(int i=1;i<=l;i++) { int u,v,w; scanf(" (%d,%d)%d",&u,&v,&w); if(u==v) continue; u+=2; v+=2; mpt[u][v]+=w; } for(int i=1;i<=p;i++) //超级起点 { int v,w; scanf(" (%d)%d)",&v,&w); v+=2; mpt[1][v]+=w; } for(int i=1;i<=c;i++) //超级汇点 { int u,w; scanf(" (%d)%d)",&u,&w); u+=2; mpt[u][n]+=w; } printf("%d ",EK()); } return 0; }