折腾了几天,爬了大大小小若干的坑,特记录如下。代码在最后面。
环境:
Python3.6.4 + TensorFlow 1.5.1 + Win7 64位 + I5 3570 CPU
方法:
先用MNIST手写数字库对CNN(卷积神经网络)进行训练,准确度达到98%以上时,再准备独家手写数字10个、画图软件编辑的数字10个共计20个,让训练好的CNN进行识别,考察其识别准确度。
调试代码:
坑1:ModuleNotFoundError: No module named 'google'
解决:pip install protobuf
不用FQ
坑2:ModuleNotFoundError: No module named 'absl'
解决:pip install absl-py
坑3:tensorflow.python.framework.errors_impl.InvalidArgumentError: You must feed a value for placeholder tensor 'Placeholder_2' with dtype float
解决:这个问题折腾我好久,但是最终的解决方法很无语。。。
原来的代码是这样的:
output = sess.run(y_conv, feed_dict={x: ndarrayImgs}) # ndarrayImgs为自己的样本图片数据
查了不少资料,最后发现是自己少写了一个参数 /笑哭/笑哭, 写成这样就没问题了:
output = sess.run(y_conv, feed_dict={x: ndarrayImgs, keep_prob:1.0})
代码调通了之后,大坑来了:训练后的CNN识别自己的手写数字和用画图软件编辑出来的数字,正确率只有70%左右,惨不忍睹。
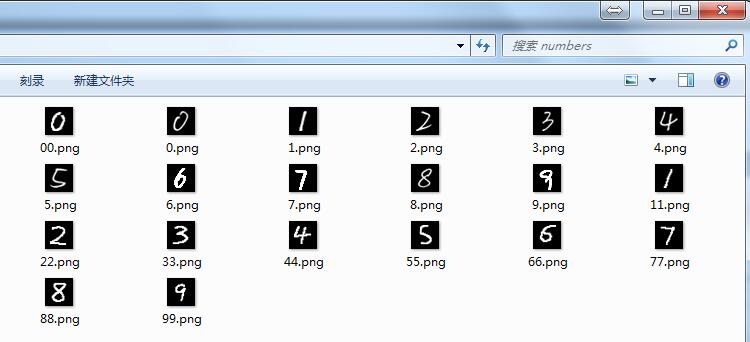
考虑到上面20个数字都是五官端正的,那么准确率低多半是其它原因。调试思路:
1)检查20个数字图片的格式:灰度图片,黑底白字,28x28像素。没问题。
2)用MNIST自带的测试数据进行测试,正确率95%左右。说明CNN训练的还算到位。
3)去网上搜索,终于在知乎里发现了一条回复:MNIST的数字都是20*20大小,图片大小28*28。把自己的图片伸缩到20*20大小,然后平移到28*28的中心就可以了。
纳尼??原来数字轮廓大小是20x20像素,这个细节我没注意到。开动PS,利用裁切和调整画布功能,对图片处理了一番。
附:MNIST数据库及其说明 http://yann.lecun.com/exdb/mnist/
再次测试,正确率在85-90%左右,有明显提升。
然而仔细分析发现,有几个数字的识别结果经常出错,分别是手写的6、7、9。将这几个数字的图片和样本库中的图片对比了一下,猜想可能是这几个图片中的数字的线条有些细,于是用PS又调整了一下,把线条变粗,结果识别正确率可以达到95-100%了(奇怪的是,数字1-5线条也细,为何能准确识别?)
调试过程记录完毕,放代码。使用时注意系统环境和相关软件版本,如开头所述。
这个代码在每次识别前都会先训练,在CPU上进行计算真是痛苦。。。以后打算将训练和预测分开,训练好的模型保存起来,预测的时候直接加载,这样能省不少时间。
代码没优化,有点凌乱,建议移步去看我的《使用TensorFlow的卷积神经网络识别手写数字》1、2、3系列。
1 import matplotlib 2 import matplotlib.pyplot as plt 3 import matplotlib.cm as cm 4 import pylab 5 from tensorflow.examples.tutorials.mnist import input_data 6 7 8 def showMnistImg(nBytes): 9 imgBytes = nBytes.reshape((28, 28)) 10 print(imgBytes) 11 plt.figure(figsize=(2.8,2.8)) 12 #plt.grid() #开启网格 13 plt.imshow(imgBytes, cmap=cm.gray) 14 pylab.show() 15 16 17 def MaxMinNormalization(x,Max,Min): 18 x = (x - Min) / (Max - Min); 19 return x; 20 21 22 def loadHandWritingImage(strFilePath): 23 im=Image.open(strFilePath, 'r') 24 ndarrayImg = np.array(im.convert("L"), dtype='float64') 25 26 return ndarrayImg 27 28 def normalizeImage(ndarrayImg, maxVal = 255, minVal = 0): 29 w, h = ndarrayImg.shape[0], ndarrayImg.shape[1] 30 for i in range(w): 31 for j in range(h): 32 ndarrayImg[i,j] = MaxMinNormalization(ndarrayImg[i,j], maxVal, minVal) #??? 33 34 return ndarrayImg 35 36 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) 37 38 # 单个手写数字的784个字节的灰度值,浮点数,范围[0,1) 39 print('type(mnist.train.images): ', type(mnist.train.images)) # <class 'numpy.ndarray'> 40 print('mnist.train.images.shape: ', mnist.train.images.shape) 41 ##print(mnist.train.images[0]) 42 ##showMnistImg(mnist.train.images[0]) 43 44 45 # 单个手写数字的标签 46 # 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0 47 # 数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。 48 #print('type(mnist.train.labels[0]): ', type(mnist.train.labels[0]))# <class 'numpy.ndarray'> 49 #print(mnist.train.labels[19]) # [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] 50 51 52 53 #构造自己的手写图片集合,作为test。 cnblogs.com/hatemath 54 from PIL import * 55 import numpy as np 56 import tensorflow as tf 57 58 # 构建测试样本集合 59 files = ['0.png', '1.png', '2.png', '3.png', '4.png', '5.png', '6.png', '7.png', '8.png', '9.png', 60 '00.png', '11.png', '22.png', '33.png', '44.png', '55.png', '66.png', '77.png', '88.png', '99.png'] 61 62 ndarrayImgs = np.zeros((len(files), 784)) # x行784列 63 #print('type(ndarrayImgs): ', type(ndarrayImgs)) 64 #print('ndarrayImgs.shape: ', ndarrayImgs.shape) 65 66 index = 0 67 for file in files: 68 69 # 加载图片 70 ndarrayImg = loadHandWritingImage('numbers/' + file) 71 72 #print('type(ndarrayImg): ', type(ndarrayImg)) 73 #print(ndarrayImg) 74 75 # 归一化 76 normalizeImage(ndarrayImg) 77 78 # 转为1x784的数组 79 ndarrayImg = ndarrayImg.reshape((1, 784)) 80 #print('type(ndarrayImg): ', type(ndarrayImg)) 81 #print('ndarrayImg.shape: ', ndarrayImg.shape) 82 83 # 放到测试样本集中 84 ndarrayImgs[index] = ndarrayImg 85 index = index + 1 86 87 88 # 构建测试样本的实际值集合,用于计算正确率 89 ndarrayLabels = np.array([ [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], 90 [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], 91 [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], 92 [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], 93 [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], 94 [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], 95 [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], 96 [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], 97 [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], 98 [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], 99 [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], 100 [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], 101 [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], 102 [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], 103 [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], 104 [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], 105 [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], 106 [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], 107 [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], 108 [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.] 109 ]) 110 print('type(ndarrayLabels): ', type(ndarrayLabels)) 111 112 113 #print(ndarrayImgs[3]) 114 ##showMnistImg(ndarrayImgs[3]) 115 #print(ndarrayLabels[3]) 116 117 118 # 下面开始CNN相关 119 120 def conv2d(x, W): 121 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') 122 123 def max_pool_2x2(x): 124 return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], 125 strides=[1, 2, 2, 1], padding='SAME') 126 127 128 def weight_variable(shape): 129 initial = tf.truncated_normal(shape, stddev=0.1) 130 return tf.Variable(initial) 131 132 def bias_variable(shape): 133 initial = tf.constant(0.1, shape=shape) 134 return tf.Variable(initial) 135 136 137 x = tf.placeholder(tf.float32, shape=[None, 784]) 138 y_ = tf.placeholder(tf.float32, shape=[None, 10]) 139 140 141 W_conv1 = weight_variable([5, 5, 1, 32]) 142 b_conv1 = bias_variable([32]) 143 144 x_image = tf.reshape(x, [-1, 28, 28, 1]) 145 146 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) 147 h_pool1 = max_pool_2x2(h_conv1) 148 149 150 W_conv2 = weight_variable([5, 5, 32, 64]) 151 b_conv2 = bias_variable([64]) 152 153 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) 154 h_pool2 = max_pool_2x2(h_conv2) 155 156 157 158 W_fc1 = weight_variable([7 * 7 * 64, 1024]) 159 b_fc1 = bias_variable([1024]) 160 161 h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) 162 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) 163 164 165 keep_prob = tf.placeholder(tf.float32) 166 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) 167 168 169 W_fc2 = weight_variable([1024, 10]) 170 b_fc2 = bias_variable([10]) 171 172 y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2 173 #print(y_conv) 174 175 176 177 cross_entropy = tf.reduce_mean( 178 tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=y_conv)) 179 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) 180 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) 181 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) 182 183 with tf.Session() as sess: 184 sess.run(tf.global_variables_initializer()) 185 for i in range(1000): 186 batch = mnist.train.next_batch(50) 187 188 if i % 100 == 0: 189 train_accuracy = accuracy.eval(feed_dict={ 190 x: batch[0], y_: batch[1], keep_prob: 1.0}) 191 print('step %d, training accuracy %g' % (i, train_accuracy)) 192 if(train_accuracy>0.98): 193 break 194 195 train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) 196 197 198 199 print('测试Mnist test数据集 准确率 %g' % accuracy.eval(feed_dict={ 200 x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})) 201 202 # 测试耗时 203 import time 204 start = time.time() 205 accu = accuracy.eval(feed_dict={x: ndarrayImgs, y_: ndarrayLabels, keep_prob: 1.0}) 206 end = time.time() 207 208 print('识别zzh手写数据%d个, 准确率为 %g, 每个耗时%g秒' % (len(ndarrayImgs), accu, (end-start)/len(ndarrayImgs))) 209 210 output = sess.run(y_conv, feed_dict={x: ndarrayImgs, keep_prob:1.0}) 211 print('预测值:', output.argmax(axis=1)) # axis:0表示按列,1表示按行 212 print('实际值:', ndarrayLabels.argmax(axis=1))
贴2次运行结果,供参考:
Extracting MNIST_data rain-images-idx3-ubyte.gz Extracting MNIST_data rain-labels-idx1-ubyte.gz Extracting MNIST_data 10k-images-idx3-ubyte.gz Extracting MNIST_data 10k-labels-idx1-ubyte.gz type(mnist.train.images): <class 'numpy.ndarray'> mnist.train.images.shape: (55000, 784) type(ndarrayLabels): <class 'numpy.ndarray'> step 0, training accuracy 0.14 step 100, training accuracy 0.86 step 200, training accuracy 0.82 step 300, training accuracy 0.98 测试Mnist test数据集 准确率 0.9213 识别zzh手写数据20个, 准确率为 0.9, 每个耗时0.000750029秒 预测值: [0 1 2 3 4 5 6 1 8 9 0 1 2 3 4 5 6 2 8 9] 实际值: [0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9] >>>
Extracting MNIST_data rain-images-idx3-ubyte.gz Extracting MNIST_data rain-labels-idx1-ubyte.gz Extracting MNIST_data 10k-images-idx3-ubyte.gz Extracting MNIST_data 10k-labels-idx1-ubyte.gz type(mnist.train.images): <class 'numpy.ndarray'> mnist.train.images.shape: (55000, 784) type(ndarrayLabels): <class 'numpy.ndarray'> step 0, training accuracy 0.14 step 100, training accuracy 0.84 step 200, training accuracy 0.92 step 300, training accuracy 0.88 step 400, training accuracy 0.96 step 500, training accuracy 0.98 测试Mnist test数据集 准确率 0.9445 识别zzh手写数据20个, 准确率为 1, 每个耗时0.000779998秒 预测值: [0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9] 实际值: [0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9] >>>
总结:
1) CNN虽然是个神器,但是要想提高手写数字识别率,除了CNN的训练外,还要在手写图片上做足前戏,啊呸,做足预处理,要把手写图片按照MNIST规范进行调整,毕竟训练的样本就是按照那些规范来的。
2) 再次重申一下图片规范:灰度图片,黑底白字,数字的外围轮廓大小是20x20像素,图片总体的大小是28x28像素。自动化的预处理可以用opencv来做。
3) 用CPU做训练,非常慢。我的机器上,训练500次耗时1分钟,每次调试都这么等,太浪费时间了。考虑保存/加载模型的方案,或者搞一块N卡,用CUDA计算应该会快很多。