先看下面几个问题,如果你能准确地回答,那么此篇文章将不适合你:
- 计算机中怎样表示浮点数的,与整型的表示方法有什么不同?
- 32位精度的float类型和64位精度的double类型能表示浮点数最大范围是多少?
- 该C语言语句 printf("%d\n", 2.5); 输出结果是什么,为什么?
我先说在此之前我如果回答,答案如下:
- 计算机中有符号整型采用补码进行表示,浮点型怎么表示没想过。
- float类型可以表示-232-1~232,double类型可以表示-264-1~264。
- 输出格式要求输出整型,而数是浮点型,类型转化之后输出结果为2。
有一点可以明确,我的回答都是错误的。那好吧,下面是我查看一些资料总结出来的,希望能解释清楚其中的”奥秘“。
IEEE754标准(以下简称”标准“)是使用最广泛的浮点数运算标准,为许多CPU与浮点运算器所采用。该标准定义了表示浮点数的格式,如下图所示:

下面只讨论二进制浮点数的表示,分成了三个部分:
符号位、指数、尾数,它们的含义可以类比科学计数法。如:
科学计数法中:
(102.35045)10 = +1.0235045 × 102 符号位为正,指数是2,尾数是1.0235045。
(-0.00023103)10 = -2.3103 × 10-4 符号位为负,指数是-4,尾数是2.3103。
同样在规格化二进制浮点数中:
(1001.0111010)2 = +1.001011101 × 23 符号位为正,指数是3,尾数是1.001011101。
(-0.0001010011)2 = -1.010011 × 2-4 符号位为负,指数是-4,尾数是1.010011。
由上面的实例可以知道,在二进制浮点数被规格化后,尾数的格式都是1.****,指数表示将小数点移动多少位可以实现规格化(向左指数加1,向右指数减1),因此可以正也可为负。
标准同时规定:
- 符号位用1位表示,0表示正数,1表示负数;
- 指数采用移码表示(原来的实际的指数值加上一个固定值得到的),这个固定值为2e-1-1(e为指数部分比特长度),之所以加上这个偏移量,是为了将负数变成非负数,这样两个指数的大小很容易就可以比较。
- 尾数采用原码表示,正如上所说,规格化二进制浮点数最高位均为1,那么小数点前这个就没必要用一个比特位去存储,我们默认已经存在,称为”隐藏位“。
标准规定了四种浮点数的表示方式:单精确度(32位)、双精确度(64位)、延伸单精确度(43比特以上,很少使用)与延伸双精确度(79比特以上,通常以80比特实做)。C语言中float和double浮点型分别对应的是单精度和双精度浮点数,下面介绍这两种浮点数的存储格式:
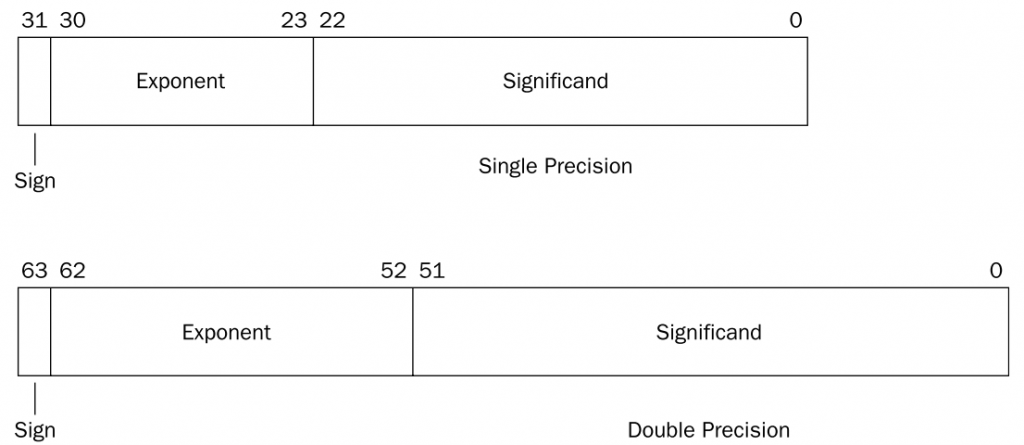
如上面两个例子,分别使用单精度和双精度表示如下:
至此,应该已经解释清楚了浮点数在计算机中的存储格式和方法了,也就等于回答了上面的第一个问题,至于第二个问题,如果理解了上面所说的,求浮点数表示的范围就应该很简单了,下表为单精度浮点数各种极值情况:
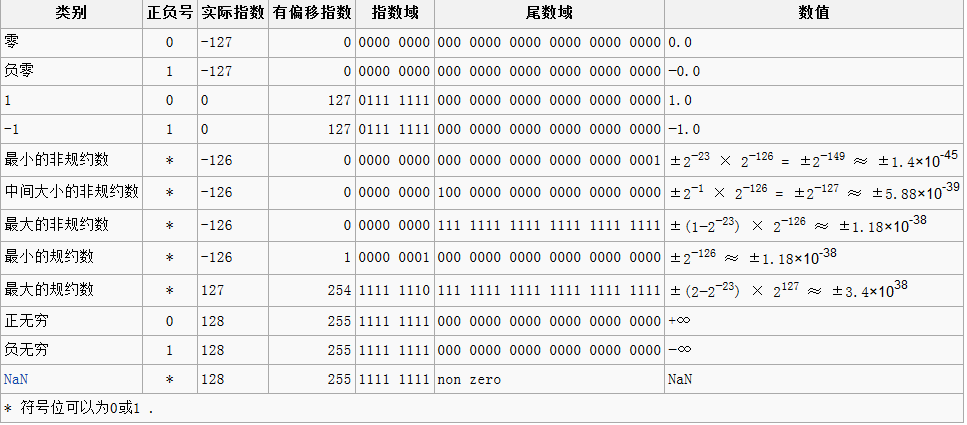
至于最后一个问题,我们写一个C语言程序进行测试:
#include <stdio.h>
int main()
{
printf("%d\n", 2.5);
return 0;
}
编译运行结果如下:
[guohl@guohl]$ gcc -o test test.c -g [guohl@guohl]$ ./test 0
运行结果和我们预期的2不一样,使用gdb调试,在main函数处插入断点,并且反汇编main函数之后得到:
(gdb) break main
Breakpoint 1 at 0x8048415: file test.c, line 5.
(gdb) run
Starting program: /home/guohl/Documents/AS/test
Breakpoint 1, main () at test.c:5
5 printf("%d\n", 2.5);
(gdb) disassemble
Dump of assembler code for function main:
0x0804840c <+0>: push %ebp
0x0804840d <+1>: mov %esp,%ebp
0x0804840f <+3>: and $0xfffffff0,%esp
0x08048412 <+6>: sub $0x10,%esp
=> 0x08048415 <+9>: fldl 0x80484e0
0x0804841b <+15>: fstpl 0x4(%esp)
0x0804841f <+19>: movl $0x80484d8,(%esp)
0x08048426 <+26>: call 0x80482f0 <printf@plt>
0x0804842b <+31>: mov $0x0,%eax
0x08048430 <+36>: leave
0x08048431 <+37>: ret
End of assembler dump.
fldl addr 指令将内存addr中的双精度浮点数加载到FPU寄存器堆栈,fstpl value 将双精度数据从FPU寄存器堆栈出栈,保存到value中。因此,
0x08048415 <+9>: fldl 0x80484e0 0x0804841b <+15>: fstpl 0x4(%esp)
首先取出内存0x80484e0处的双精度浮点数加载到FPU寄存器st0中,再从st0中取出放到esp-4处。先使用gdb -x命令查看内存0x80484e0处的内容:
(gdb) x/fg 0x80484e0 0x80484e0: 2.5 (gdb) x/2xw 0x80484e0 0x80484e0: 0x00000000 0x40040000 (gdb) x/8tb 0x80484e0 0x80484e0: 00000000 00000000 00000000 00000000 00000000 00000000 00000100 01000000
从上可以看到,以双字的小数查看结果为2.5,由于我们平台采用的是小端格式存储(little-edian,低位字节存储在低内存位置),所以将以字节查看得到的结果恢复成下面的表示方法:
01000000 00000100 00000000 00000000 00000000 00000000 00000000 00000000
我们用IEEE754标准的双精度格式解析上面这段二进制,符号位为0,即为正;指数位为10000000000(1024)减去偏移量1023为1;尾数0100…000,加上隐藏位1,为1.01(即十进制1.25)。所以结果为+1.25×21 = 2.5,符合我们的预期。
那么fstpl指令将该浮点数加载到esp-4处作为printf函数的参数,再接着指令“movl $0x80484d8,(%esp) ”将输出格式控制符"%d" 的指针保存到esp指向的位置作为printf函数的函数,我们可以使用gdb查看内存0x80484d8处是不是格式控制符字符串:
(gdb) x/4cb 0x80484d8 0x80484d8: 37 '%' 100 'd' 10 '\n' 0 '\000'
确实如我们所想,现在在调用printf之前函数堆栈的结构如下所示:
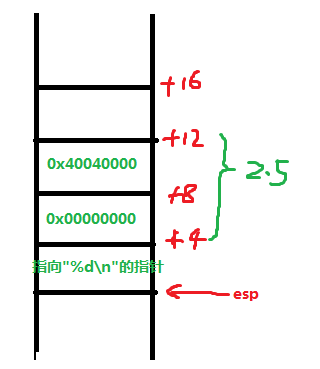
进入printf函数,解析第一个参数输出格式控制字符串,遇到%d,函数从之前压栈的参数取出一个整型即取到上图中esp+4处的值,以整型数输出,为0。这就是我们上面运行./test 的输出结果,而不是我想当然的程序会将2.5强制类型转化为整型得到2!
参考资料:
http://zh.wikipedia.org/wiki/IEEE_754
Richard Blum, Professional Assembly Language

