过去的一年里,我们准备在Ali-HBase上突破这个被普遍认知的痛点,为此进行了深度分析及全面创新的工作,获得了一些比较好的效果。以蚂蚁风控场景为例,HBase的线上young GC时间从120ms减少到15ms,结合阿里巴巴JDK团队提供的利器——AliGC,进一步在实验室压测环境做到了5ms。本文主要介绍我们过去在这方面的一些工作和技术思想。
背景
JVM的GC机制对开发者屏蔽了内存管理的细节,提高了开发效率。说起GC,很多人的第一反应可能是JVM长时间停顿或者FGC导致进程卡死不可服务的情况。但就HBase这样的大数据存储服务而言,JVM带来的GC挑战相当复杂和艰难。原因有三:
1、内存规模巨大。线上HBase进程多数为96G大堆,今年新机型已经上线部分160G以上的堆配置
2、对象状态复杂。HBase服务器内部会维护大量的读写cache,达到数十GB的规模。HBase以表格的形式提供有序的服务数据,数据以一定的结构组织起来,这些数据结构产生了过亿级别的对象和引用
3、young GC频率高。访问压力越大,young区的内存消耗越快,部分繁忙的集群可以达到每秒1~2次youngGC, 大的young区可以减少GC频率,但是会带来更大的young GC停顿,损害业务的实时性需求。
思路
1. HBase作为一个存储系统,使用了大量的内存作为写buffer和读cache,比如96G的大堆(4G young + 92G old)下,写buffer+读cache会占用70%以上的内存(约70G),本身堆内的内存水位会控制在85%,而剩余的占用内存就只有在10G以内了。所以,如果我们能在应用层面自管理好这70G+的内存,那么对于JVM而言,百G大堆的GC压力就会等价于10G小堆的GC压力,并且未来面对更大的堆也不会恶化膨胀。 在这个解决思路下,我们线上的young GC时间获得了从120ms到15ms的优化效果。
2. 在一个高吞吐的数据密集型服务系统中,大量的临时对象被频繁创建与回收,如何能够针对性管理这些临时对象的分配与回收,AliJDK团队研发了一种新的基于租户的GC算法—AliGC。集团HBase基于这个新的AliGC算法进行改造,我们在实验室中压测的young GC时间从15ms减少到5ms,这是一个未曾期望的极致效果。
下面将逐一介绍Ali-HBase版本GC优化所使用的关键技术。
消灭一亿个对象:更快更省的CCSMap
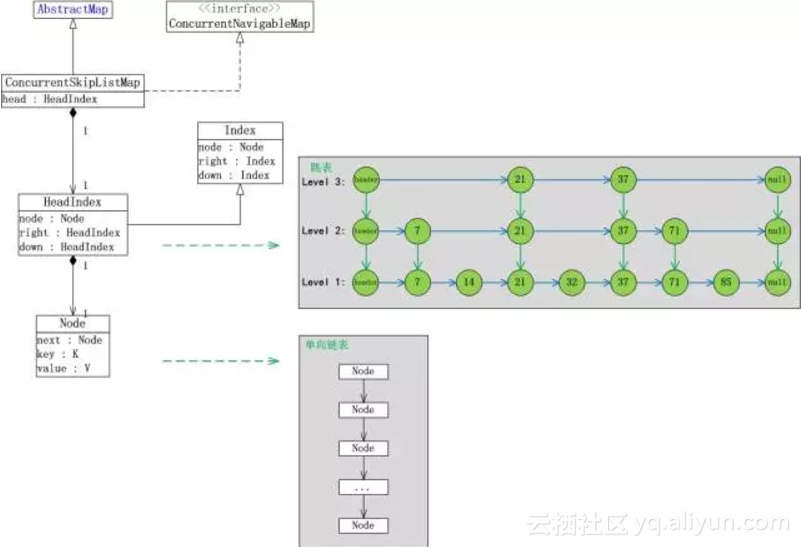
目前HBase使用的存储模型是LSMTree模型,写入的数据会在内存中暂存到一定规模后再dump到磁盘上形成文件。
下面我们将其简称为写缓存。写缓存是可查询的,这就要求数据在内存中有序。为了提高并发读写效率,并达成数据有序且支持seek&scan的基本要求,SkipList是使用得比较广泛的数据结构。
58f76b7ba750e50270ef32dd46824307a5d3645b
我们以JDK自带的ConcurrentSkipListMap为例子进行分析,它有下面三个问题:
1. 内部对象繁多。每存储一个元素,平均需要4个对象(index+node+key+value,平均层高为1)
2. 新插入的对象在young区,老对象在old区。当不断插入元素时,内部的引用关系会频繁发生变化,无论是ParNew算法的CardTable标记,还是G1算法的RSet标记,都有可能触发old区扫描。
3. 业务写入的KeyValue元素并不是规整长度的,当它晋升到old区时,可能产生大量的内存碎片。
问题1使得young区GC的对象扫描成本很高,young GC时晋升对象更多。问题2使得young GC时需要扫描的old区域会扩大。问题3使得内存碎片化导致的FGC概率升高。当写入的元素较小时,问题会变得更加严重。我们曾对线上的RegionServer进程进行统计,活跃Objects有1亿2千万之多!
分析完当前young GC的最大敌人后,一个大胆的想法就产生了,既然写缓存的分配,访问,销毁,回收都是由我们来管理的,如果让JVM“看不到”写缓存,我们自己来管理写缓存的生命周期,GC问题自然也就迎刃而解了。
说起让JVM“看不到”,可能很多人想到的是off-heap的解决方案,但是这对写缓存来说没那么简单,因为即使把KeyValue放到offheap,也无法避免问题1和问题2。而1和2也是young GC的最大困扰。
问题现在被转化成了:如何不使用JVM对象来构建一个有序的支持并发访问的Map。
当然我们也不能接受性能损失,因为写入Map的速度和HBase的写吞吐息息相关。
需求再次强化:如何不使用对象来构建一个有序的支持并发访问的Map,且不能有性能损失。
为了达成这个目标,我们设计了这样一个数据结构:
- 它使用连续的内存(堆内or堆外),我们通过代码控制内部结构而不是依赖于JVM的对象机制
- 在逻辑上也是一个SkipList,支持无锁的并发写入和查询
- 控制指针和数据都存放在连续内存中
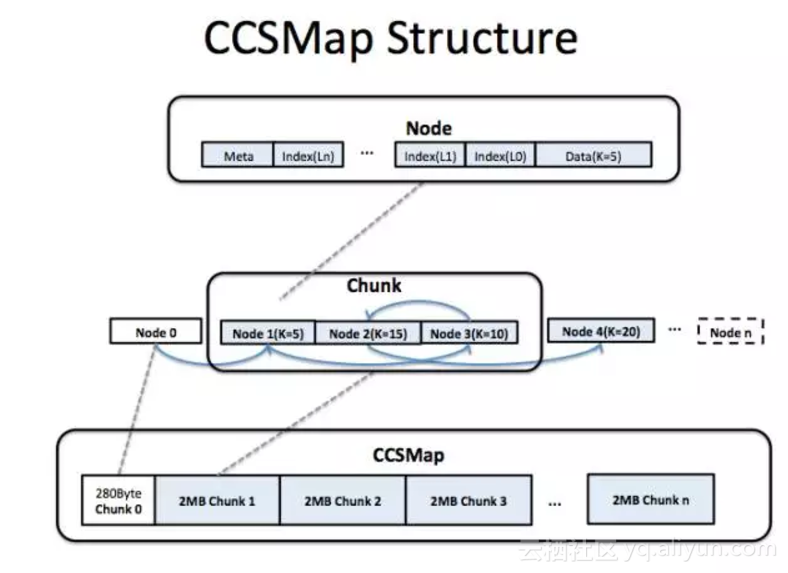
ca814f49b62436a12186d01fd39a285c32fa86ef
上图所展示的即是CCSMap(CompactedConcurrentSkipListMap)的内存结构。 我们以大块的内存段(Chunk)的方式申请写缓存内存。每个Chunk包含多个Node,每个Node对应一个元素。新插入的元素永远放在已使用内存的末尾。Node内部复杂的结构,存放了Index/Next/Key/Value等维护信息和数据。新插入的元素需要拷贝到Node结构中。当HBase发生写缓存dump时,整个CCSMap的所有Chunk都会被回收。当元素被删除时,我们只是逻辑上把元素从链表里"踢走",不会把元素实际从内存中收回(当然做实际回收也是有方法,就HBase而言没有那个必要)。
插入KeyValue数据时虽然多了一遍拷贝,但是就绝大多数情况而言,拷贝反而会更快。因为从CCSMap的结构来看,一个Map中的元素的控制节点和KeyValue在内存上是邻近的,利用CPU缓存的效率更高,seek会更快。对于SkipList来说,写速度其实是bound在seek速度上的,实际拷贝产生的overhead远不如seek的开销。根据我们的测试,CCSMap和JDK自带的ConcurrentSkipListMap相比,50Byte长度KV的测试中,读写吞吐提升了20~30%。
由于没有了JVM对象,每个JVM对象至少占用16Byte空间也可以被节省掉(8byte为标记预留,8byte为类型指针)。还是以50Byte长度KeyValue为例,CCSMap和JDK自带的ConcurrentSkipListMap相比,内存占用减少了40%。
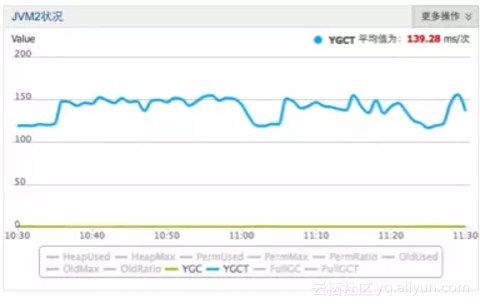
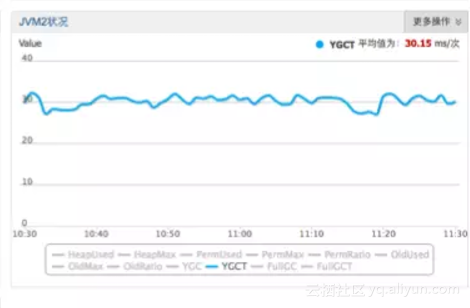
CCSMap在生产中上线后,实际优化效果: young GC从120ms+减少到了30ms
ae9cd66c2bd2f434820907ab924260deba709d58
优化前
103ee25343ec5a45342a12d3fc7478005bf2ff72
优化后
使用了CCSMap后,原来的1亿2千万个存活对象被缩减到了千万级别以内,大大减轻了GC压力。由于紧致的内存排布,写入吞吐能力也得到了30%的提升。
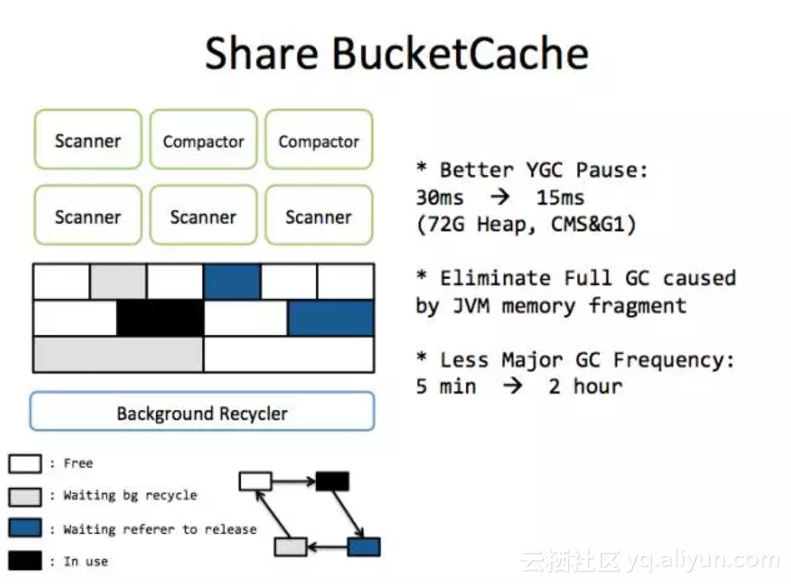
永不晋升的Cache:BucketCache
HBase以Block的方式组织磁盘上的数据。一个典型的HBase Block大小在16K~64K之间。HBase内部会维护BlockCache来减少磁盘的I/O。BlockCache和写缓存一样,不符合GC算法理论里的分代假说,天生就是对GC算法不友好的 —— 既不稍纵即逝,也不永久存活。
一段Block数据从磁盘被load到JVM内存中,生命周期从分钟到月不等,绝大部分Block都会进入old区,只有Major GC时才会让它被JVM回收。它的麻烦主要体现在:
1. HBase Block的大小不是固定的,且相对较大,内存容易碎片化
2. 在ParNew算法上,晋升麻烦。麻烦不是体现在拷贝代价上,而是因为尺寸较大,寻找合适的空间存放HBase Block的代价较高。
读缓存优化的思路则是,向JVM申请一块永不归还的内存作为BlockCache,我们自己对内存进行固定大小的分段,当Block加载到内存中时,我们将Block拷贝到分好段的区间内,并标记为已使用。当这个Block不被需要时,我们会标记该区间为可用,可以重新存放新的Block,这就是BucketCache。关于BucketCache中的内存空间分配与回收(这一块的设计与研发在多年前已完成),详细可以参考 : http://zjushch.iteye.com/blog/1751387

42997fe9fa81105c96bfe60f00c29bd7e88c7785
很多基于堆外内存的RPC框架,也会自己管理堆外内存的分配和回收,一般通过显式释放的方式进行内存回收。但是对HBase来说,却有一些困难。我们将Block对象视为需要自管理的内存片段。Block可能被多个任务引用,要解决Block的回收问题,最简单的方式是将Block对每个任务copy到栈上(copy的block一般不会晋升到old区),转交给JVM管理就可以。
实际上,我们之前一直使用的是这种方法,实现简单,JVM背书,安全可靠。但这是有损耗的内存管理方式,为了解决GC问题,引入了每次请求的拷贝代价。由于拷贝到栈上需要支付额外的cpu拷贝成本和young区内存分配成本,在cpu和总线越来越珍贵的今天,这个代价显得高昂。
于是我们转而考虑使用引用计数的方式管理内存,HBase上遇到的主要难点是:
- HBase内部会有多个任务引用同一个Block
- 同一个任务内可能有多个变量引用同一个Block。引用者可能是栈上临时变量,也可能是堆上对象域。
- Block上的处理逻辑相对复杂,Block会在多个函数和对象之间以参数、返回值、域赋值的方式传递。
- Block可能是受我们管理的,也可能是不受我们管理的(某些Block需要手动释放,某些不需要)。
- Block可能被转换为Block的子类型。
这几点综合起来,对如何写出正确的代码是一个挑战。但在C++ 上,使用智能指针来管理对象生命周期是很自然的事情,为什么到了Java里会有困难呢?
Java中变量的赋值,在用户代码的层面上,只会产生引用赋值的行为,而C++ 中的变量赋值可以利用对象的构造器和析构器来干很多事情,智能指针即基于此实现(当然C++的构造器和析构器使用不当也会引发很多问题,各有优劣,这里不讨论)
于是我们参考了C++的智能指针,设计了一个Block引用管理和回收的框架ShrableHolder来抹平coding中各种if else的困难。它有以下的范式:
- ShrableHolder可以管理有引用计数的对象,也可以管理非引用计数的对象
- ShrableHolder在被重新赋值时,释放之前的对象。如果是受管理的对象,引用计数减1,如果不是,则无变化。
- ShrableHolder在任务结束或者代码段结束时,必须被调用reset
- ShrableHolder不可直接赋值。必须调用ShrableHolder提供的方法进行内容的传递
- 因为ShrableHolder不可直接赋值,需要传递包含生命周期语义的Block到函数中时,ShrableHolder不能作为函数的参数。
根据这个范式写出来的代码,原来的代码逻辑改动很少,不会引入if else。虽然看上去仍然有一些复杂度,所幸的是,受此影响的区间还是局限于非常局部的下层,对HBase而言还是可以接受的。为了保险起见,避免内存泄漏,我们在这套框架里加入了探测机制,探测长时间不活动的引用,发现之后会强制标记为删除。
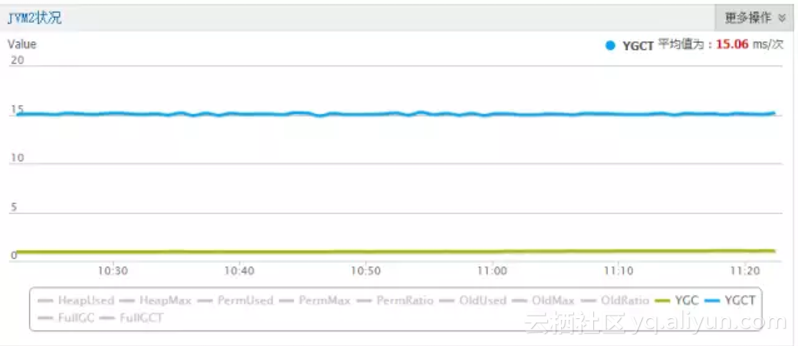
将BucketCache应用之后,减少了BlockCache的晋升开销,减少了young GC时间:
124c501dc766d397bbe5eee44b9036d38dbcd2e0
e859b25742e535f64d892f75aacd68854dd9948f
(CCSMap+BucketCache优化后的效果)
追求极致:AliGC
经过以上两个大的优化之后,蚂蚁风控生产环境的young GC时间已经缩减到15ms。由于ParNew+CMS算法在这个尺度上再做优化已经很困难了,我们转而投向AliGC的怀抱。AliGC在G1算法的基础上做了深度改进,内存自管理的大堆HBase和AliGC产生了很好的化学反应。
AliGC是阿里巴巴JVM团队基于G1算法, 面向大堆 (LargeHeap) 应用场景,优化的GC算法的统称。这里主要介绍下多租户GC。
多租户GC包含的三层核心逻辑:
1、在JavaHeap上,对象的分配按照租户隔离,不同的租户使用不同的Heap区域;
2、允许GC以更小的代价发生在租户粒度,而不仅仅是应用的全局;
3、允许上层应用根据业务需求对租户灵活映射。
AliGC将内存Region划分为了多个租户,每个租户内独立触发GC。在个基础上,我们将内存分为普通租户和中等生命周期租户。中等生命周期对象指的是,既不稍纵即逝,也不永久存在的对象。由于经过以上两个大幅优化,现在堆中等生命周期对象数量和内存占用已经很少了。但是中等生命周期对象在生成时会被old区对象引用,每次young GC都需要扫描RSet,现在仍然是young GC的耗时大头。
借助于AJDK团队的ObjectTrace功能,我们找出中等生命周期对象中最"大头"的部分,将这些对象在生成时直接分配到中等生命周期租户的old区,避免RSet标记。而普通租户则以正常的方式进行内存分配。
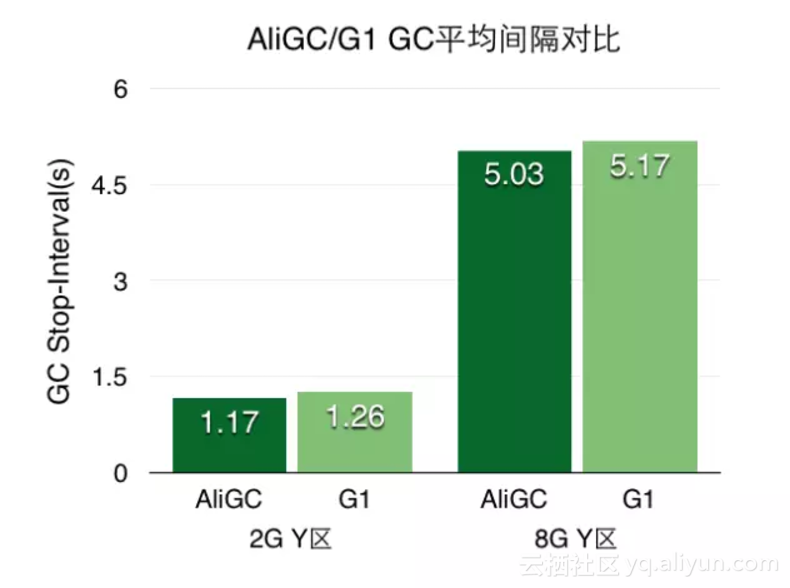
普通租户GC频率很高,但是由于晋升的对象少,跨代引用少,Young区的GC时间得到了很好的控制。在实验室场景仿真环境中,我们将young GC优化到了5ms。
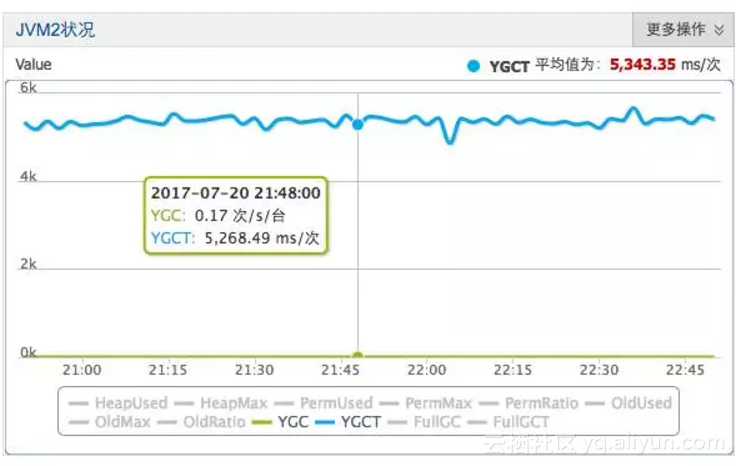
124bff446b4f1a76df9ff40cce0d023040d7fbdf
(AliGC优化后的效果,单位问题,此处为us)
2f3dbfac848d5ca74c6f8c99c3c4322e05f625dc
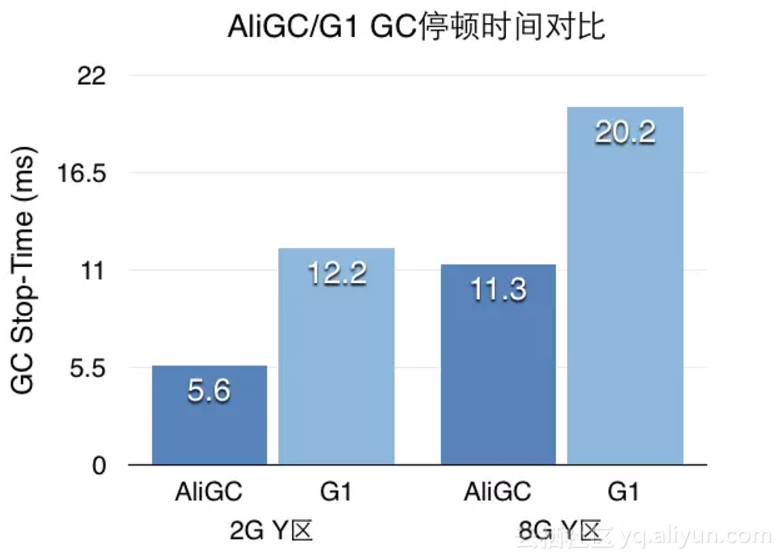
fcaa74ac18167a988559fa275478347a46713ae1
云端使用
阿里HBase目前已经在阿里云提供商业化服务,任何有需求的用户都可以在阿里云端使用深入改进的、一站式的HBase服务。云HBase版本与自建HBase相比在运维、可靠性、性能、稳定性、安全、成本等方面均有很多的改进,更多内容欢迎大家关注 https://www.aliyun.com/product/hbase
写在最后 如果你对大数据存储、分布式数据库、HBase等感兴趣,欢迎加入我们,一起做最好的大数据在线存储,联系方式:tianwu.sch@alibaba-inc.com;也欢迎一起交流问题,一起学习新技术。
转载: https://yq.aliyun.com/articles/277268
资料
HBase:https://pan.baidu.com/s/1jILzgns
知乎HBase讨论:https://www.zhihu.com/topic/19600820/hot
hbase-help:http://hbase-help.com/
CSDN HBase资料库:http://lib.csdn.net/hbase/node/734
这些资料是笔者整理,以供有大规模结构化需求的用户及HBase爱好者学习交流,以使用HBase更好的解决实际的问题。
交流
如果大家对HBase有兴趣,致力于使用HBase解决实际的问题,欢迎加入Hbase技术社区群交流:
微信HBase技术社区群,假如微信群加不了,可以加秘书微信: SH_425 ,然后邀请您。

钉钉HBase技术社区群
