本文主要对Python如何读取结构化数据进行总结梳理,涵盖从文本文件,尤其是excel文件(用于离线数据探索分析),以及结构化数据库(以Mysql为例)中读取数据等内容。
约定:
import numpy as np
import pandas as pd
1、从文本文件中读取
(1)使用Python标准库中的read、readline、readlines方法读取
a. 一般流程:
step1: 通过open方法创建一个文件对象
setp2: 通过read、readline、readlines方法读取文件内容
step3: 通过close方法关闭文件对象
b. 区别:
示例:test.txt
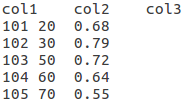
read方法:读取全部数据,结果为一个字符串(所有行合并为一个字符串)
#打开文件
f = open('/labcenter/python/pandas/test.txt')
#使用read方法读取文件
data1 = f.read()
print data1
type(data1)
#关闭文件
f.close()
结果:
col1 col2 col3
101 20 0.68
102 30 0.79
103 50 0.72
104 60 0.64
105 70 0.55
str
readline方法:读取一行数据,结果为一个字符串,需要seek ext等指针操作方法配合实现所有记录的遍历。
#打开文件
f = open('/labcenter/python/pandas/test.txt')
#使用readline方法读取文件
data2 = f.readline()
print data2
type(data2)
#关闭文件
f.close()
结果:
col1 col2 col3
str
readlines方法:读取全部数据,结构为一个列表(一行为列表中的一个元素)
#打开文件
f = open('/labcenter/python/pandas/test.txt')
#使用readlines方法读取文件
data3 = f.readlines()
print data3
type(data3)
for line in data3:
print line
#关闭文件
f.close()
结果:
['col1 col2 col3
', '101 20 0.68
', '102 30 0.79
', '103 50 0.72
', '104 60 0.64
', '105 70 0.55']
list
col1 col2 col3
101 20 0.68
102 30 0.79
103 50 0.72
104 60 0.64
105 70 0.55
c. 支持文件范围:
txtcsv sv及所有以固定分隔符分隔的文本文件。
(2)使用Numpy库中的loadtxt、load、fromfile方法读取
a. loadtxt方法
从txt文本文件中读取,返回一个数组。
np.loadtxt('/labcenter/python/pandas/test.txt',skiprows=1)
Out[413]:
array([[ 101. , 20. , 0.68],
[ 102. , 30. , 0.79],
[ 103. , 50. , 0.72],
[ 104. , 60. , 0.64],
[ 105. , 70. , 0.55]])
b. load方法
读取Numpy专用的二进制数据文件,该文件通常基于Numpy的save或savez方法生成。
write = np.array([[1,2,3,4],[5,6,7,8]])
np.save('output',write)
data = np.load('output.npy')
print data
type(data)
结果:
[[1 2 3 4]
[5 6 7 8]]
numpy.ndarray
c. fromfile方法
读取简单的文本文件和二进制文件,该文件通常基于Numpy的tofile方法生成。
write = np.array([[1,2,3,4],[5,6,7,8]])
write.tofile('output')
data = np.fromfile('output',dtype='float32')
print data
type(data)
结果:
[ 1.40129846e-45 0.00000000e+00 2.80259693e-45 ..., 0.00000000e+00
1.12103877e-44 0.00000000e+00]
numpy.ndarray
(3)使用Pandas库中的read_csv、read_table、read_excel等方法读取
a. read_csv方法
读取csv文件,返回一个DataFrame对象或TextParser对象。
示例:
test.csv

data = pd.read_csv('/labcenter/python/pandas/test.csv')
print data
type(data)
结果:
col1 col2 col3
0 101 20 0.68
1 102 30 0.79
2 103 50 0.72
3 104 60 0.64
4 105 70 0.55
pandas.core.frame.DataFrame
b. read_table方法
读取通用分隔符分隔的文本文件,返回一个DataFrame对象或TextParser对象。
data = pd.read_table('/labcenter/python/pandas/test.csv',sep=',')
print data
type(data)
结果:
col1 col2 col3
0 101 20 0.68
1 102 30 0.79
2 103 50 0.72
3 104 60 0.64
4 105 70 0.55
pandas.core.frame.DataFrame
c. read_excel方法
读取excel文件,返回一个DataFrame对象或TextParser对象。
示例:
test.xlsx

data = pd.read_excel('/labcenter/python/pandas/test.xlsx')
print data
type(data)
结果:
col1 col2 col3
0 101 21 22.6
1 102 31 31.2
2 103 41 32.7
3 104 51 28.2
4 105 61 18.9
pandas.core.frame.DataFrame
d. 其他方法
read_sql方法:读取sql请求或者数据库中的表。
read_json方法:读取json文件。
(4)如何选择?
a. 选取自己最熟悉的方法。
b. 根据场景选择:
① 对纯文本、非结构化的数据:标准库的三种方法
② 对结构化、数值型,并且要用于矩阵计算、数据建模的:Numpy的loadtxt方法
③ 对于二进制数据:Numpy的load和fromfile方法
④ 对于结构化的数据,并且要用于数据探索分析的:Pandas方法
2、从Excel文件中读取
excel往往是在进行离线数据探索分析时提供的数据文件格式,因此这里单独拿出来多总结一下。
(1)使用Pandas库的read_excel方法
见上文1.3.c内容。
(2)使用其他第三方库
以xlrd库为例, xlrd模块实现对excel文件内容读取。
import xlrd
#打开一个excel文件
xlsx=xlrd.open_workbook('/labcenter/python/pandas/test.xlsx')
#读取sheet清单
sheets=xlsx.sheet_names()
sheets
#获取一个sheet数据
sheet1=xlsx.sheets()[0]
#获取指定sheet的名称
sheet1.name
#获取指定sheet的行数
sheet1.nrows
#获取指定sheet的列数
sheet1.ncols
#获取指定sheet某行的数据
sheet1.row_values(1)
#获取指定sheet某列的数据
sheet1.col_values(1)
#获取指定sheet某单元格的数据
sheet1.row(1)[2].value
sheet1.cell_value(1,2)
#逐行获取指定sheet的数据
for i in range(sheet1.nrows):
print sheet1.row_values(i)
结果:
[u'Sheet1', u'Sheet2']
u'Sheet1'
6
3
[101.0, 21.0, 22.6]
[u'col2', 21.0, 31.0, 41.0, 51.0, 61.0]
22.6
22.6
[u'col1', u'col2', u'col3']
[101.0, 21.0, 22.6]
[102.0, 31.0, 31.2]
[103.0, 41.0, 32.7]
[104.0, 51.0, 28.2]
[105.0, 61.0, 18.9]
##3、从结构化数据库中读取 根据数据库选择相应的库,如:mysql数据库使用MySQLdb库,oracle数据库使用cx_Oracle库,teradata数据库使用teradata库,等等。 一般流程: step1: 建立数据库连接 step2: cursor方法获取游标 step3: execute方法执行SQL语句 step4: fetchall方法获取返回的记录 step5: close方法关闭游标 step6: close方法断开数据库连接 示例:
import MySQLdb
#建立数据库连接
conn = MySQLdb.connect("localhost", "root", "root", "testdb", charset='utf8')
#获取游标
cursor = conn.cursor()
#执行SQL语句
cursor.execute("select * from mytab1;")
#获取返回的记录
results = cursor.fetchall()
#逐行打印
for result in results:
print result
#关闭游标
cursor.close()
#断开数据库连接
conn.close()
结果:
(1L, u'aaa')
(2L, u'bbb')
(3L, u'ccc')
(4L, u'ddd')
(5L, u'eee')
可通过命令pip install MySql-Python安装库MySQLdb。
4.参考与感谢
[1] Python数据分析与数据化运营