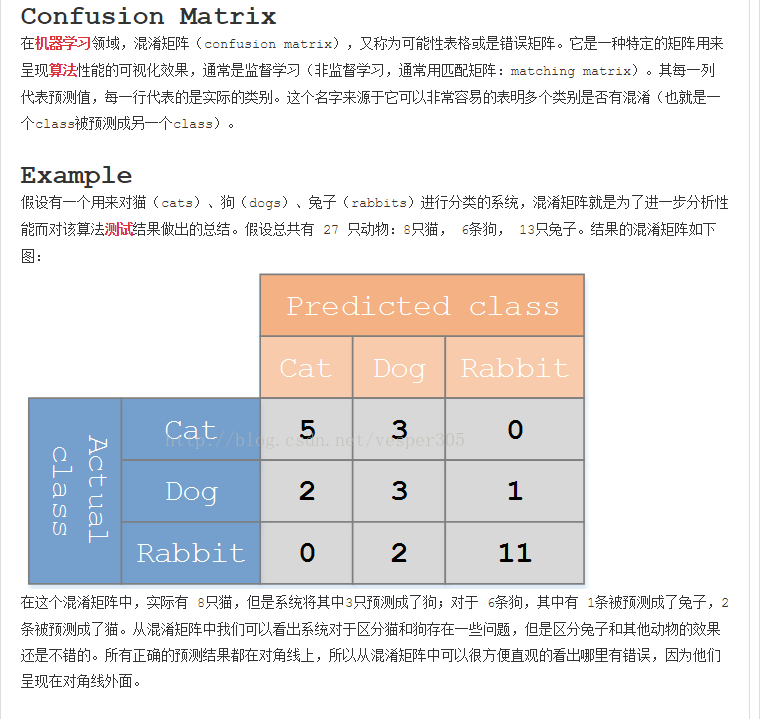
SKLearn中预测准确率函数介绍
1、在使用Sklearn进行机器学习算法预测测试数据时,常用到classification_report函数来进行测试的准确率的计算输
#开始预测
y_pred = clf.predict(X_test)
print("done in %0.3fs" % (time() - t0))
#通过该函数,比较预测出的标签和真实标签,并输出准确率
print(classification_report(y_test, y_pred))
#建立一个矩阵,以真实标签和预测标签为元素
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
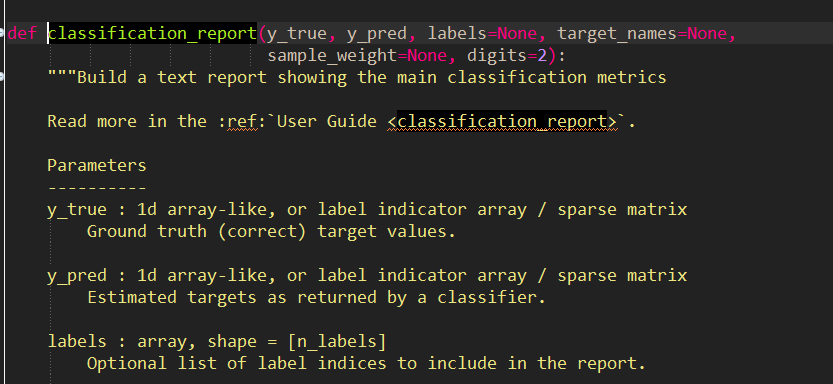
下图为Eclipse下classification_report函数的源代码:
这是一个示例输出:
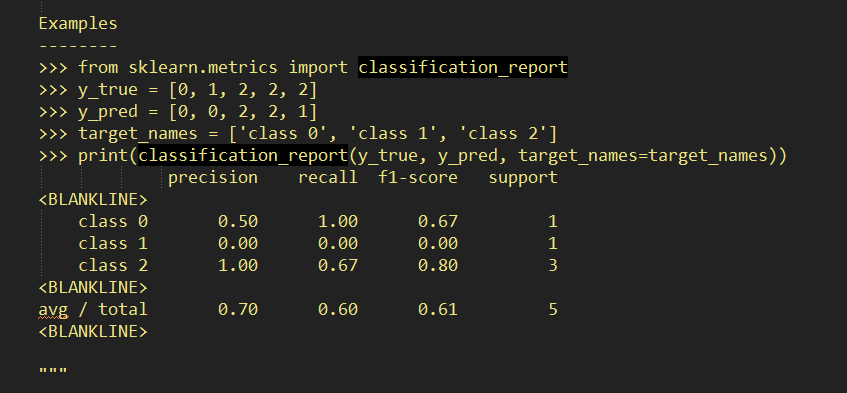
其中在函数中p=precision,r=recall,f1=f1-score,s=support
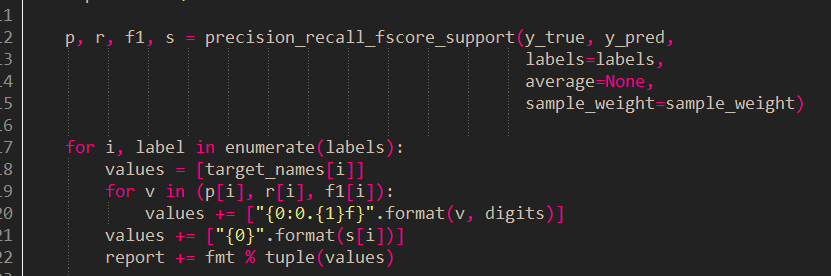
下面,在precision_recall_fscore_support函数的源代码:
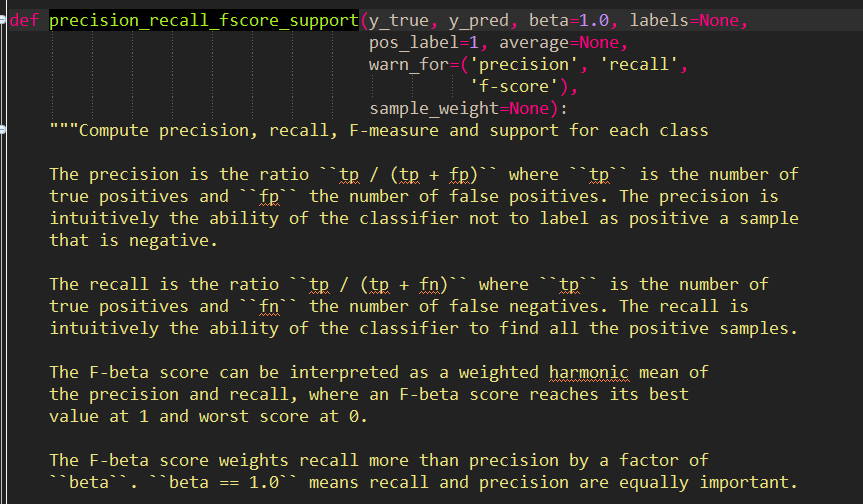
可以看到输出的precision,recall及F-score的具体计算公式,和具体的意义。

下面将一一给出‘tp’,‘fp’,‘fn’的具体含义:
准确率: 所有识别为”1”的数据中,正确的比率是多少。
如识别出来100个结果是“1”, 而只有90个结果正确,有10个实现是非“1”的数据。 所以准确率就为90%
召回率: 所有样本为1的数据中,最后真正识别出1的比率。
如100个样本”1”, 只识别出了93个是“1”, 其它7个是识别成了其它数据。 所以召回率是93%
F1-score: 是准确率与召回率的综合。 可以认为是平均效果。
详细定义如下:
对于数据测试结果有下面4种情况:
TP: 预测为正, 实现为正
FP: 预测为正, 实现为负
FN: 预测为负,实现为正
TN: 预测为负, 实现为负
准确率: TP/ (TP+FP)
召回率: TP(TP + FN)
F1-score: 2*TP/(2*TP + FP + FN)
1、在使用Sklearn进行机器学习算法预测测试数据时,常用到Confusion Matrix函数来进行测试效果直观描述:
下面是其源码中示例: