一、介绍
Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。 Beautiful Soup 已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
二、安装
pip install beautifulsoup4
三、使用
以一个简单例子讲解beautifulsoup使用。按F12或是右键单击选择检查可以打开开发者工具查看页面html,以下是网页
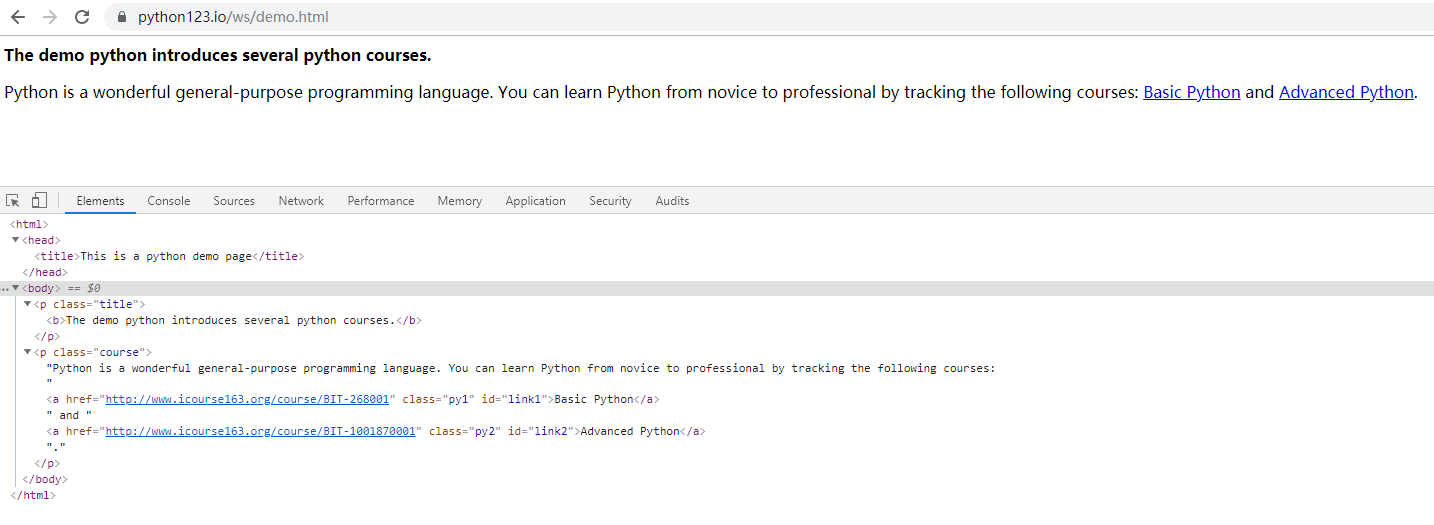
BeautifulSoup的使用
from bs4 import BeautifulSoup import requests url = "https://python123.io/ws/demo.html" r = requests.get(url) text = r.text soup = BeautifulSoup(text, "html.parser") print(soup.prettify()) #打印美化过的html代码 print(soup.title) #打印title标签下的内容 print(soup.body) #打印body标签下的内容 print(soup.p) #只打印了第一个p标签下的内容 print(soup.find_all("p")) #打印所有p标签,返回一个列表 print(soup.find("p")) #默认打印第一个p标签 print(soup.find("p",class_ = "course")) #根据属性找到第二个p标签,因为class是pyhon关键字,所以需要加上_区分 print(soup.find("a",id = "link2")) #找到id=“link2”的a标签
四、四大对象
Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
1.Tag对象
1)soup加上标签可以找到该标签的内容,但只能获取所有内容的第一个符合的标签
title = soup.title print(title) p = soup.p print(p) #2个p标签只打印了第一个
print(type(p)) #返回的类型

2)Tag的两个重属性,是 name 和 attrs
print(soup.name) #[document] print(soup.title.name) #打印标签名称,返回一个str print(soup.p.name) # print(type(soup.p.name)) #<class 'str'> print(soup.title.attrs) #打印标签属性,返回一个字典 print(soup.p.attrs) #<class 'dict'> # print(type(soup.p.attrs))

3)获取属性值
#2种方法获取属性值,返回一个列表 print(soup.p["class"]) print(soup.p.get("class")) print(type(soup.p.get("class")))

4)修改属性内容或删除
soup.p["class"] = "newtitle" #修改属性值 print(soup.p) soup.p.string = "newstring" #修改标签的内容;b标签也没有了 print(soup.p) del soup.p["class"] #删除属性 print(soup.p) # del soup.p.text #报错AttributeError: can't delete attribute;del soup.p.string一样

2.NavigableString 标签内文本内容
# string和text都可以获取标签的文本内容,但是类型不一样 print(soup.p.string) # print(type(soup.p.string)) #<class 'bs4.element.NavigableString'> print(soup.p.text) # print(type(soup.p.text)) #<class 'str'>

跨级获取文本内容
#head下面有一个title标签,获取title标签的文本 print(soup.head.string) print(soup.head.text) #第二个p标签下面有文本,还有2个a标签 p2 = soup.find("p", class_ = "course") print(p2.string) #None print("--------") print(p2.text) #p标签下的所有文本

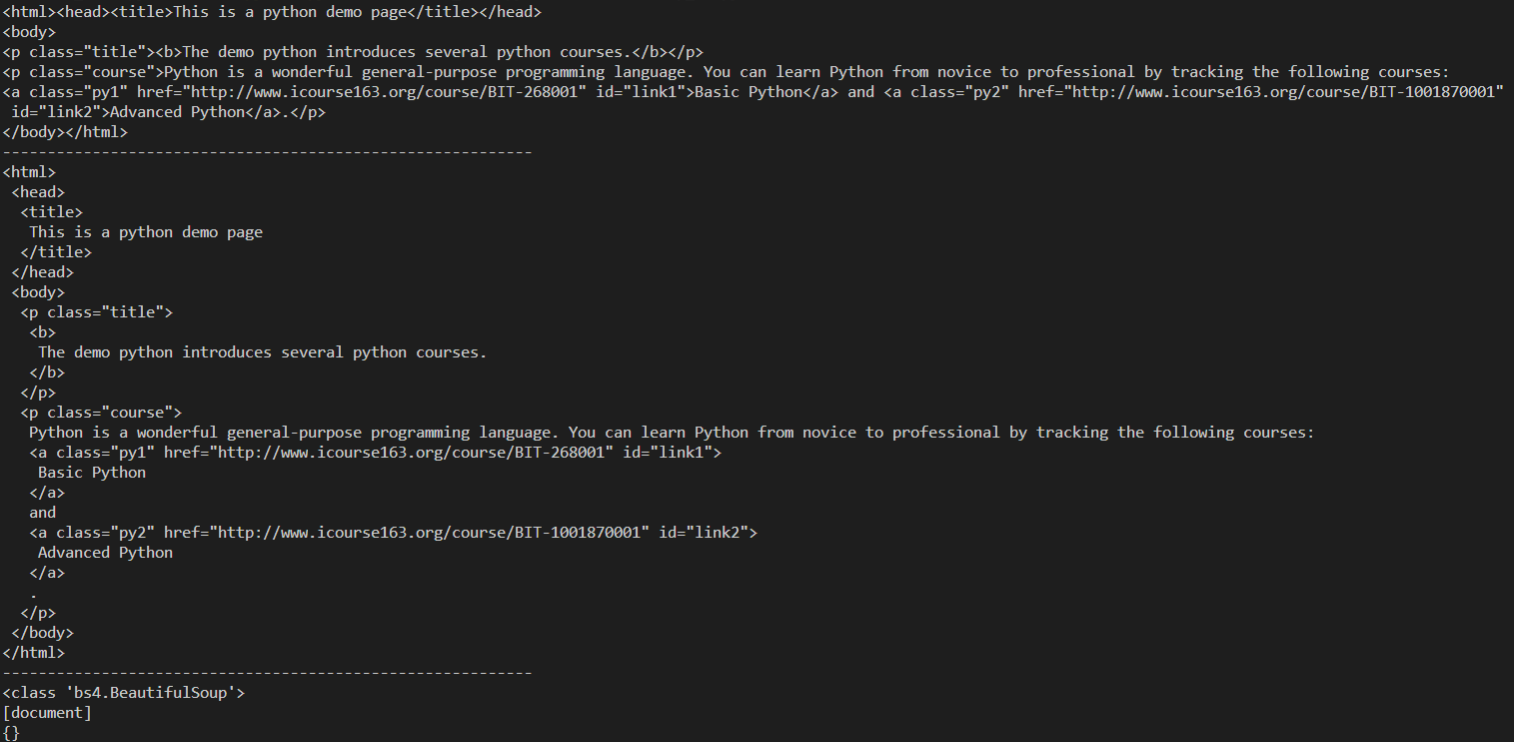
3.BeautifulSoup
BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以获取它的类型,名称,以及属性
print(soup) print("-----------------------------------------------------------") print(soup.prettify()) print("-----------------------------------------------------------") print(type(soup)) print(soup.name) print(soup.attrs)
4.Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号
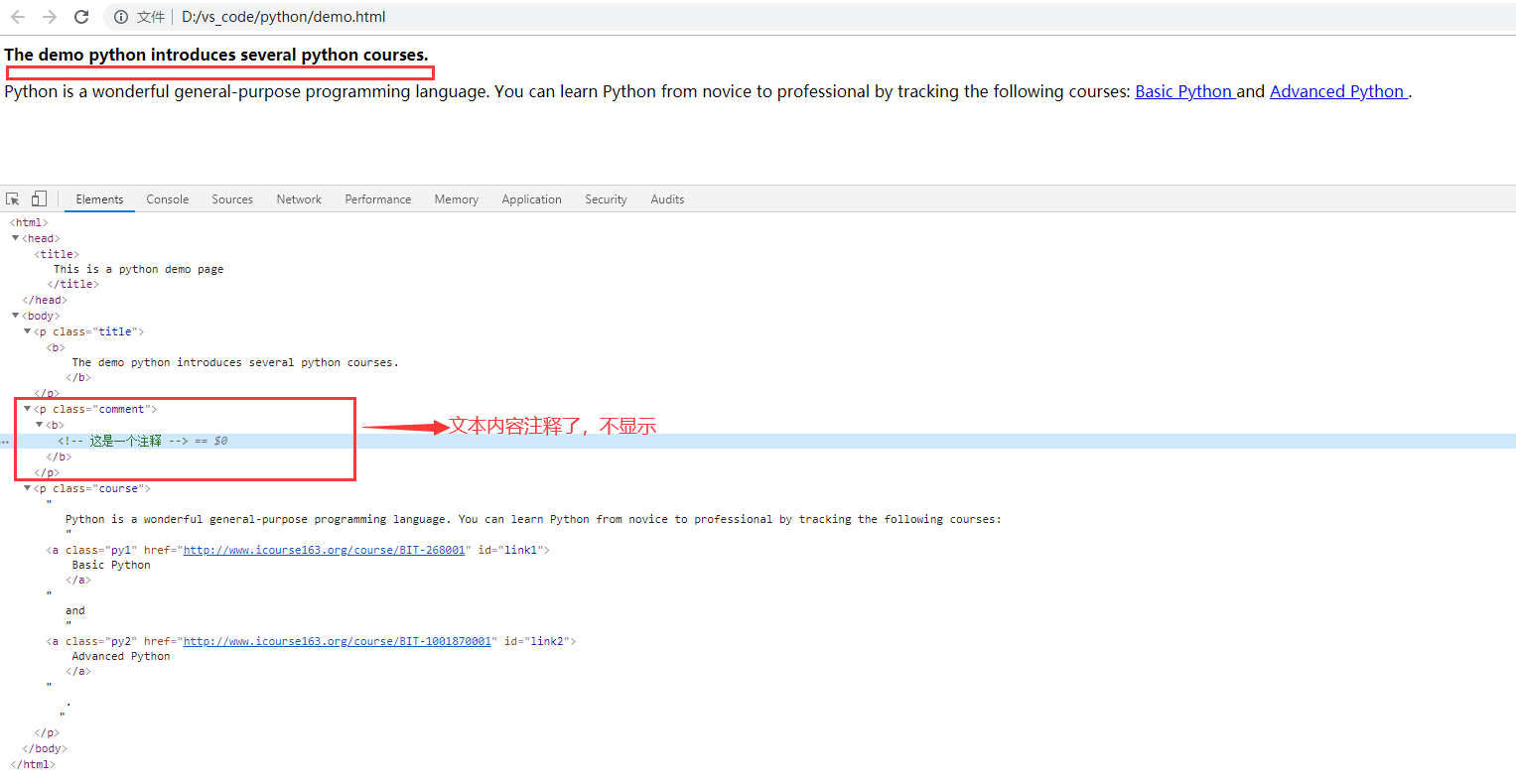
f = open("demo.html", "r", encoding = "UTF-8") #不加encoding报错 UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 250: illegal multibyte sequence text = f.read() f.close() soup = BeautifulSoup(text, "html.parser") print(soup) print("---------------------------------------------") p2 = soup.find("p", class_ = "comment") print(p2.attrs) print("---------------------------------------------") print(p2.string) #这个P标签的内注释要直接跟在p标签后,如果换行后再写注释,会返回None print(type(p2.string)) print("---------------------------------------------") print(p2.text) #打印空行
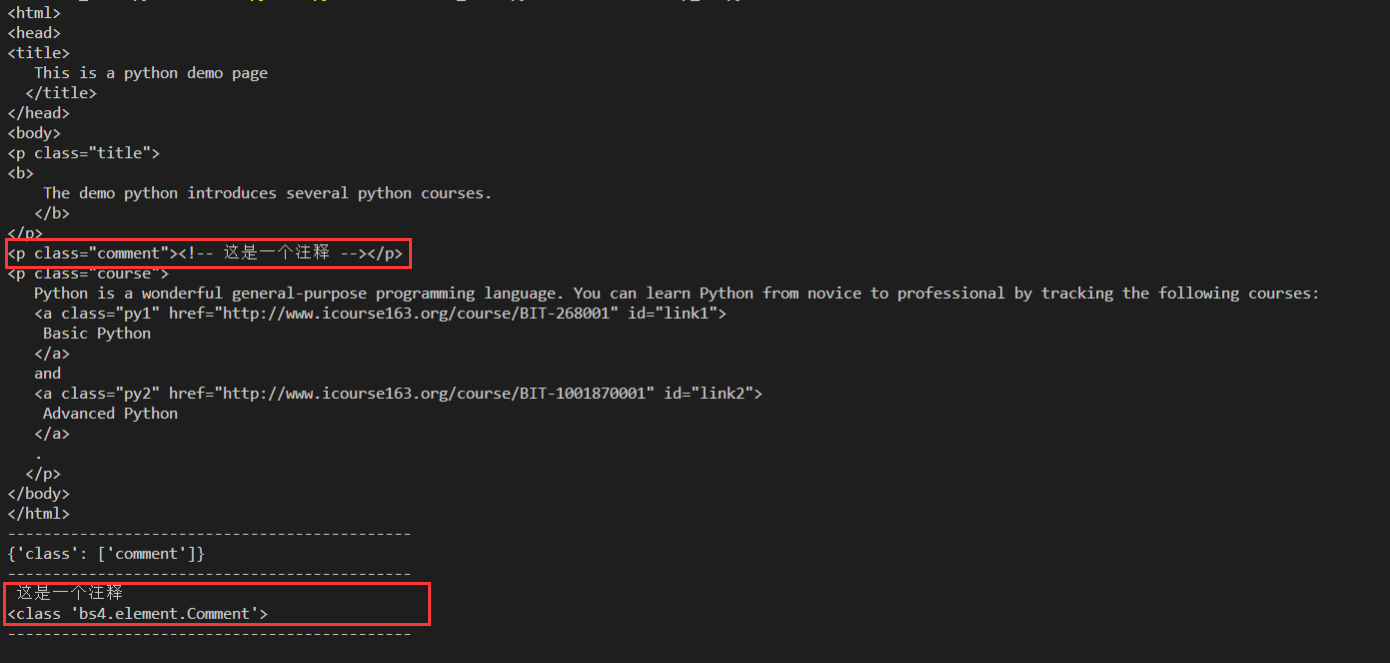
p标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。 另外我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断
import bs4 if type(p2.string) == bs4.element.Comment: print(p2.string) # 这是一个注释
五、遍历文档树
1.直接子节点
- contents #返回一个列表
- children #返回一个列表迭代器
print(soup.body.contents) #返回一个列表 返回的列表中每个p标签前后都有一个 ? print(soup.body.children) #返回一个列表迭代器 for i in soup.body.children: #返回的列表中每个p标签前后都有一个 ?
print(i)
2.所有子孙节点
- .descendants 可以对所有 tag 的子孙节点进行递归循环,返回一个生成器对象,我们需要遍历获取其中的内容
print(soup.body.descendants) #<generator object descendants at 0x0000020755C44C50> for tag in soup.body.descendants: print(tag)
3.多个内容
- strings #获取标签下的所有文本内容,返回一个生成器
- stripped_strings #获取标签下的所有文本内容,返回一个生成器,strings方法获取的文本内容可能会有空行和空格,stripped_strings会删除所有的空白内容
print(soup.body.string) #None body下面有多个标签 print(soup.body.strings) #返回一个生成器 for s in soup.body.strings: print(s) print("________________________________________________") print(soup.body.stripped_strings) #返回一个生成器 for s in soup.body.stripped_strings: print(s)
4.父节点
- parent #直接父节点,返回一个Tag对象,可以获取其.name,.attrs等值
- parents #返回所有的父节点(父节点的父节点直至整个soup对象),返回一个生成器对象
print(soup.a.parent) print(type(soup.a.parent)) print(soup.a.parent.name) print(soup.a.parent.attrs) print("________________________________________________") print(soup.a.parents) print(type(soup.a.parents)) for i in soup.a.parents: print(i) print(i.name)
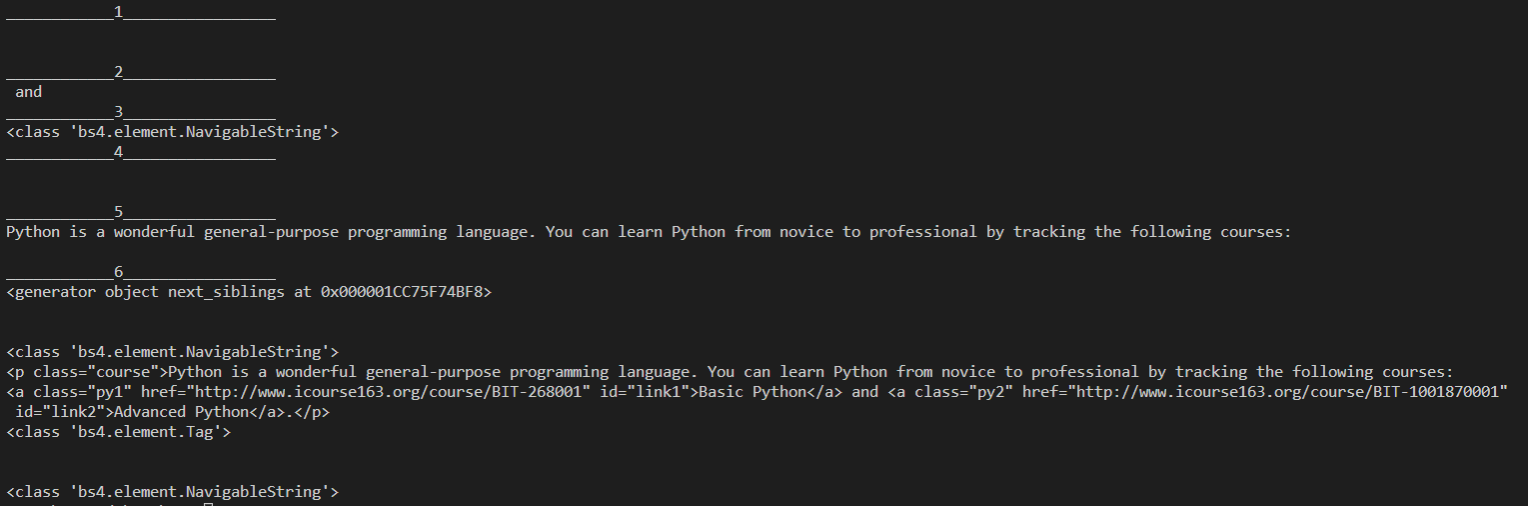
5.兄弟节点
兄弟节点可以理解为与本节点处在同一级的节点,.next_sibling 属性获取了该节点的下一个兄弟节点,.previous_sibling 则与之相反,如果节点不存在,则返回 None。 注意:实际文档中的 tag 的 .next_sibling 和 .previous_sibling 属性通常是字符串或空白,因为空白或者换行也可以被视作一个节点,所以得到的结果可能是空白或者换行
- next_siblilng #后一个兄弟节点,返回Tag对象或是NavigableString对象
- previous_sibling #前一个兄弟节点,返回Tag对象或是NavigableString对象
- next_siblings #后面的所有兄弟节点,返回一个生成器
- previuos_sibilings #前面的所有兄弟节点,返回一个生成器
print("____________1_________________") print(soup.p.next_sibling) print("____________2_________________") print(soup.a.next_sibling) print("____________3_________________") print(type(soup.a.next_sibling)) print("____________4_________________") print(soup.p.previous_sibling) print("____________5_________________") print(soup.a.previous_sibling) print("____________6_________________") print(soup.p.next_siblings) #后面的所有兄弟节点 for i in soup.p.next_siblings: #打印了2个空行和第二个p print(i) print(type(i))
6.前后节点
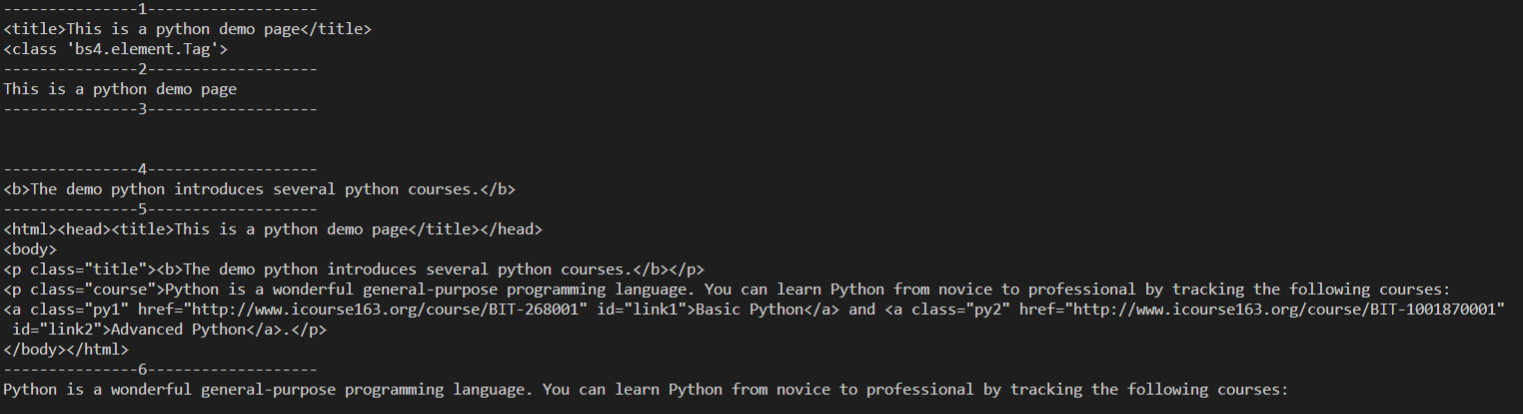
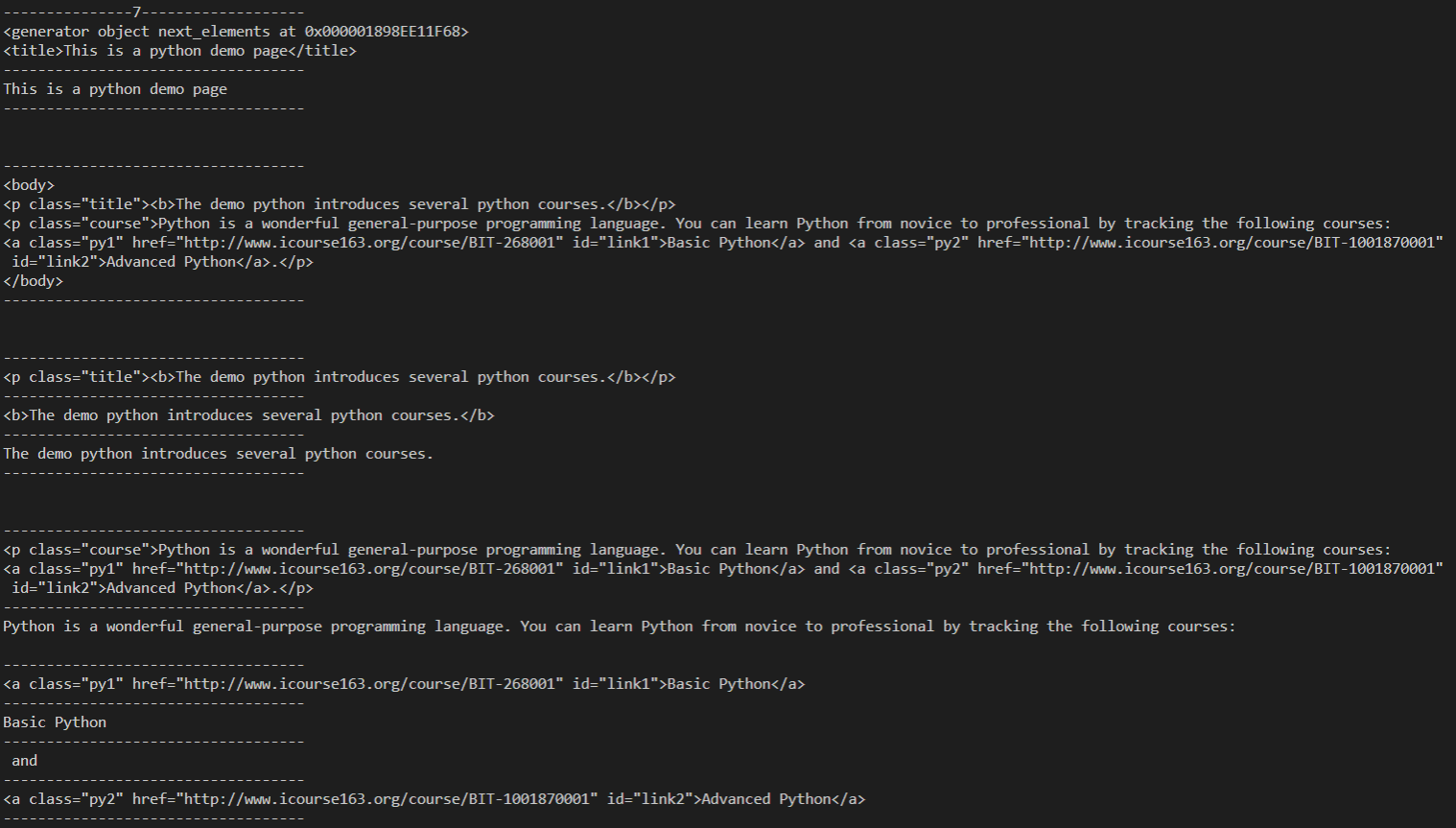
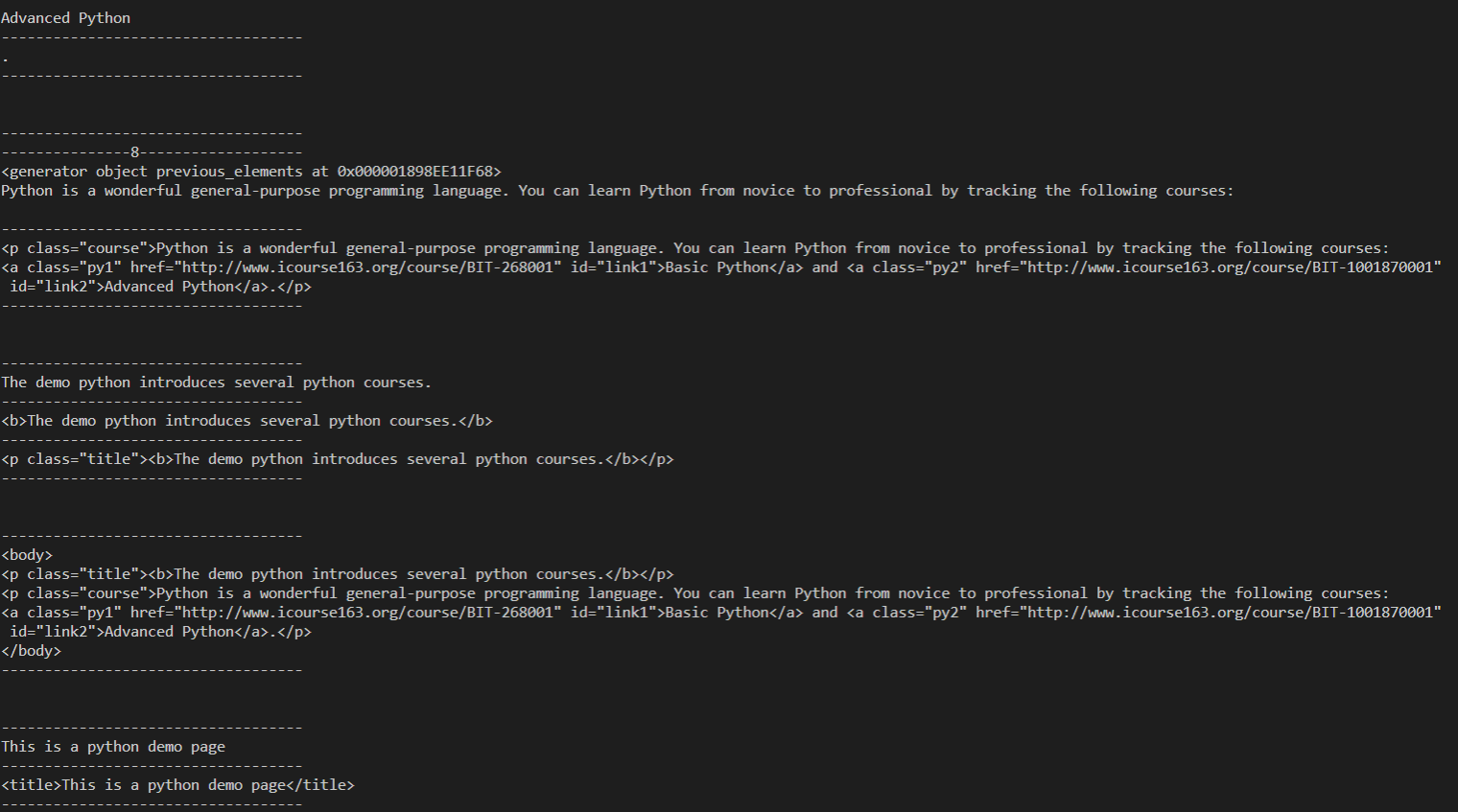
- next_element #后一个节点
- previous_element #前一个节点
- next_elements #后面的所有节点
- previous_elements #前面的所有节点
print("---------------1-------------------") print(soup.head.next_element) print(type(soup.head.next_element)) print("---------------2-------------------") print(soup.title.next_element) print("---------------3-------------------") print(soup.title.string.next_element) print("---------------4-------------------") print(soup.p.next_element) print("---------------5-------------------") print(soup.head.previous_element) print("---------------6-------------------") print(soup.a.previous_element) print("---------------7-------------------") print(soup.head.next_elements) for i in soup.head.next_elements: print(i) print("---------------8-------------------") print(soup.a.previous_elements) for i in soup.a.previous_elements: print(i)

7.关于 和空行问题
soup = BeautifulSoup(open("demo2.html",encoding = "UTF-8"), "html.parser") print(soup)

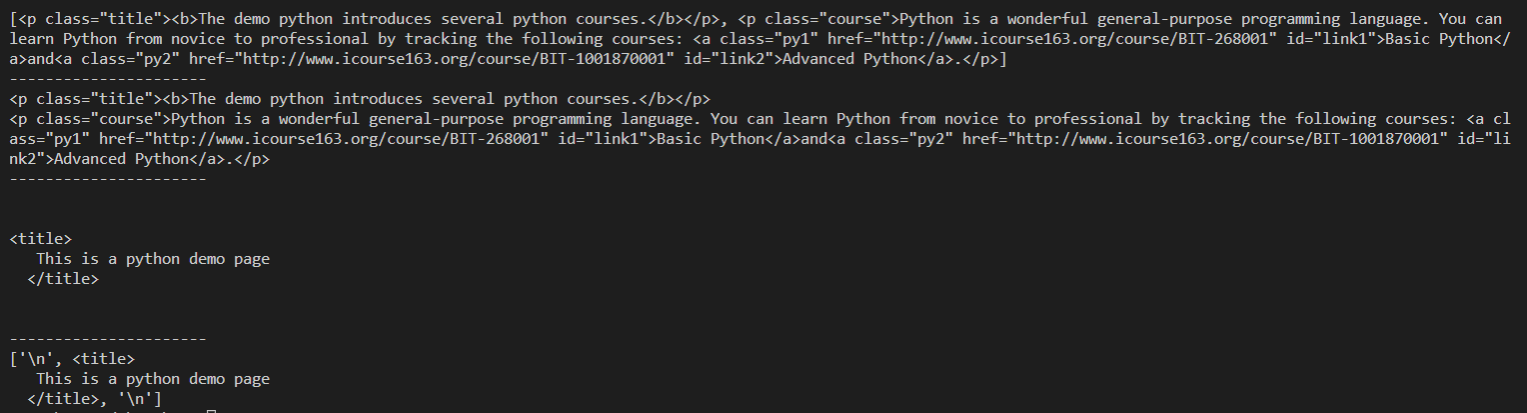
#没有空行的 print(soup.body.contents) print("----------------------") for child in soup.body.children: print(child) print("----------------------") #有空行 for child in soup.head.children: print(child) print("----------------------") print(soup.head.contents)
六、搜索文档树
1.方法
- find_all() #搜索当前 tag 的所有 tag 子节点,并判断是否符合过滤器的条件 ;返回所有符合条件的tag节点,返回一个列表
- fjind() #搜索当前tag的所有tag子节点,返回符合当前过滤条件的第一个tag
- find_parent() #搜索当前Tag的所有父节点,并判断是否符合过滤器的条件;返回符合当前过滤条件的第一个tag
- find_parents() #搜索当前Tag的所有父节点,并判断是否符合过滤器的条件 ;返回所有符合条件的tag节点,返回一个列表
- find_next_sibling() #搜索当前节点的后面所有兄弟节点,并判断是否符合过滤条件;返回符合当前过滤条件的第一个tag
- find_next_siblings() #搜索当前节点的后面所有兄弟节点,并判断是否符合过滤条件;返回所有符合条件的tag节点,返回一个列表
- find_previous_sibling() #搜索当前节点的后面所有兄弟节点,并判断是否符合过滤条件;返回符合当前过滤条件的第一个tag
- find_previous_siblings() #搜索当前节点的后面所有兄弟节点,并判断是否符合过滤条件;返回所有符合条件的tag节点,返回一个列表
- find_next() # .next_elements 属性对当前 tag 的之后的 tag 和字符串进行迭代;返回符合条件的点击一个节点
- find_all_next() #.next_elements 属性对当前 tag 的之后的 tag 和字符串进行迭代;返回所有符合条件的tag节点,返回一个列表
- find_previous() #.previous_elements 属性对当前节点前面的 tag 和字符串进行迭代;返回符合条件的点击一个节点
- find_all_previous() #.previous_elements 属性对当前节点前面的 tag 和字符串进行迭代;;返回所有符合条件的tag节点,返回一个列表
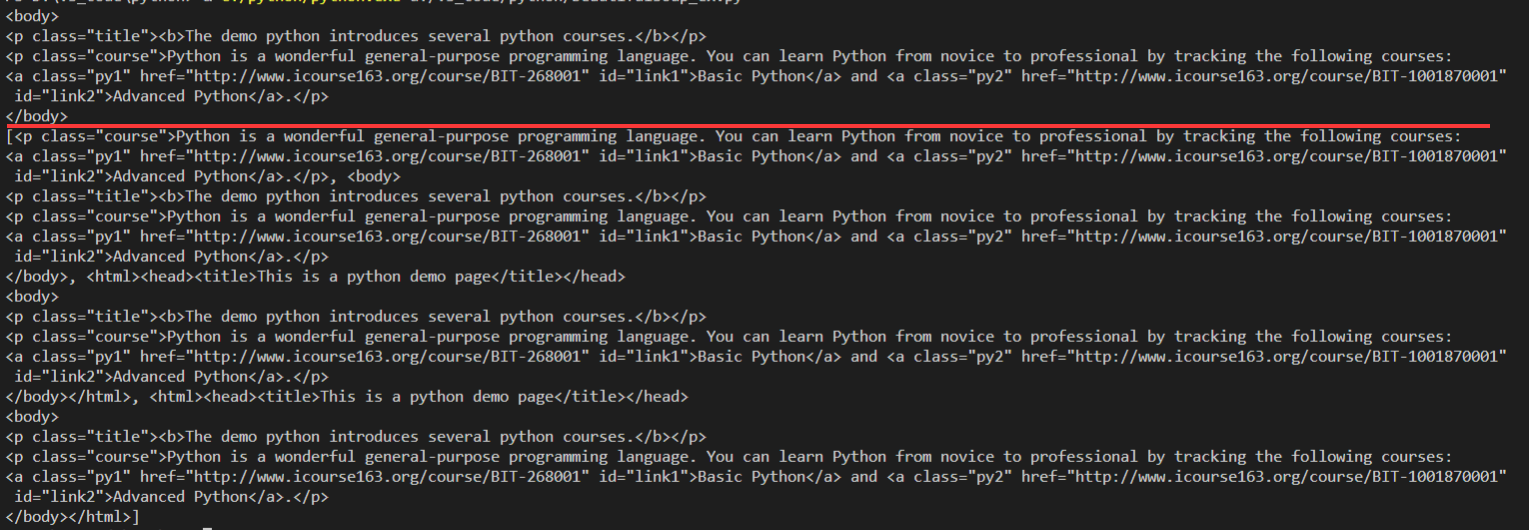
print(soup.a.find_parent("body")) #a节点的所有父节点中找body节点 print(soup.a.find_parents()) #a节点的所有父节点(
2.参数
以上方法都可以用相同的参数,以find_all()为例
find_all(name, attrs, recurssive, text, **kwargs)
1)name参数, name 参数匹配tag.name, 字符串对象会被自动忽略掉
- 传字符串,Beautiful Soup 会查找与字符串完整匹配的标签名称
- 传正则表达式, 如果传入正则表达式作为参数,Beautiful Soup 会通过正则表达式的 match () 来匹配内容。下面例子中找出所有以 b 开头的标签
- 传列表 ,如果传入列表参数,Beautiful Soup 会将与列表中任一元素匹配的内容返回
- 传 True, True 可以匹配任何值,下面代码查找到所有的 tag, 但是不会返回字符串节点
- 传方法,如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数 , 如果这个方法返回 True 表示当前元素匹配并且被找到
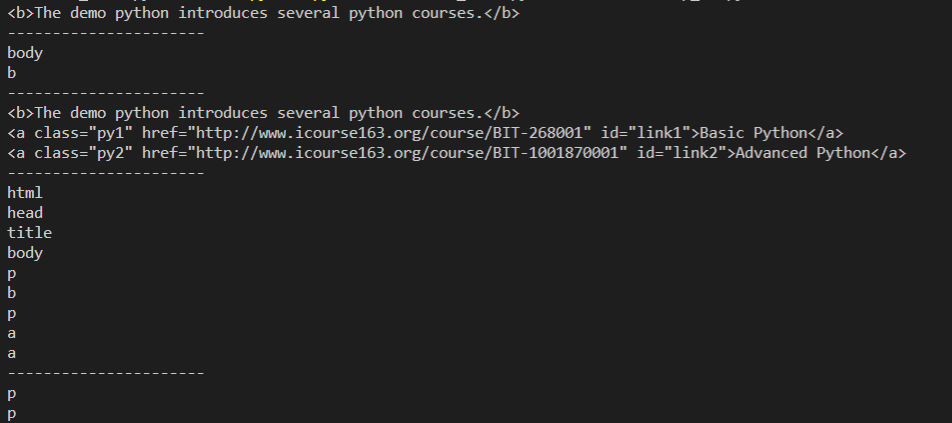
for tag in soup.find_all("b"): #字符串参数 print(tag) print("----------------------") for tag in soup.find_all(re.compile("b")): #正则表达式参数 print(tag.name) #打印标签名称 print("----------------------") for tag in soup.find_all(["a","b"]): #列表参数 print(tag) print("----------------------") for tag in soup.find_all(True): #True参数 print(tag.name) print("----------------------") def f(tag): return tag.has_attr("class") and not tag.has_attr("id") #tag有class属性但是没有id属性 for tag in soup.find_all(f): #自定义方法参数 print(tag.name)
2)attrs参数,attrs参数匹配tag.attrs
for i in soup.find_all(class_ = "title"): #根据class属性搜索 print(i) print("----------------------") for i in soup.find_all(id = "link2"): #根据id属性搜索 print(i) print("----------------------") for i in soup.find_all(href = "http://www.icourse163.org/course/BIT-1001870001"): #根据href属性搜索 print(i) print("----------------------") soup = BeautifulSoup('<p test = "111">测试</p>',"html.parser") print(soup.find_all(attrs = {"test":"111"})) #用于一些不能直接搜索的属性

3)text 参数, 通过 text 参数可以搜搜文档中的字符串内容。与 name 参数的可选值一样,text 参数接受 字符串,正则表达式,列表,True;列表中的元素为NavigableString对象
print(soup.find_all(text = "The demo")) #需要完全匹配 print("----------------------") s = soup.find_all(text = "The demo python introduces several python courses.") print(s) for i in s: print(i.parent) print(type(i))

4)limit参数,如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量。当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果
print(soup.find_all("p",limit = 1))

5)recursive 参数, 调用 tag 的 find_all () 方法时,Beautiful Soup 会检索当前 tag 的所有子孙节点,如果只想搜索 tag 的直接子节点,可以使用参数 recursive=False
print(soup.body.find_all("a")) print(soup.body.find_all("a",recursive = False))

七、CSS选择器
soup.select(),返回类型是 list;根据属性查找时,类名前加点,id 名前加 #
soup.select_one(),返回符合筛选条件的第一个;返回一个tag对象
1.根据标签名查找
print(soup.select("p")) print("----------------------") print(soup.select_one("p"))

2.根据属性查找
print(soup.select(".title")) #通过class属性查找 print(soup.select("#link2")) #通过id属性查找 print(soup.select('[class = "title"]')) #通过class属性查找

3.组合查找
print(soup.select("p .title")) #只能匹配到p的子标签的属性,不能匹配到p标签自己的属性 print(soup.select("p #link2")) print("----------------------") print(soup.select('p[class="title"]')) #只能匹配到p标签自己的属性,不能匹配到子标签的属性 print(soup.select('p[id="link2"]')) print("----------------------") print(soup.select('p>a')) #2个标签必须是父子关系,不能是爷孙关系 print(soup.select('body>a')) print("----------------------") print(soup.select('p a[id="link2"]')) #组合使用

八、例子
1.爬取论语,并保存为TXT文件
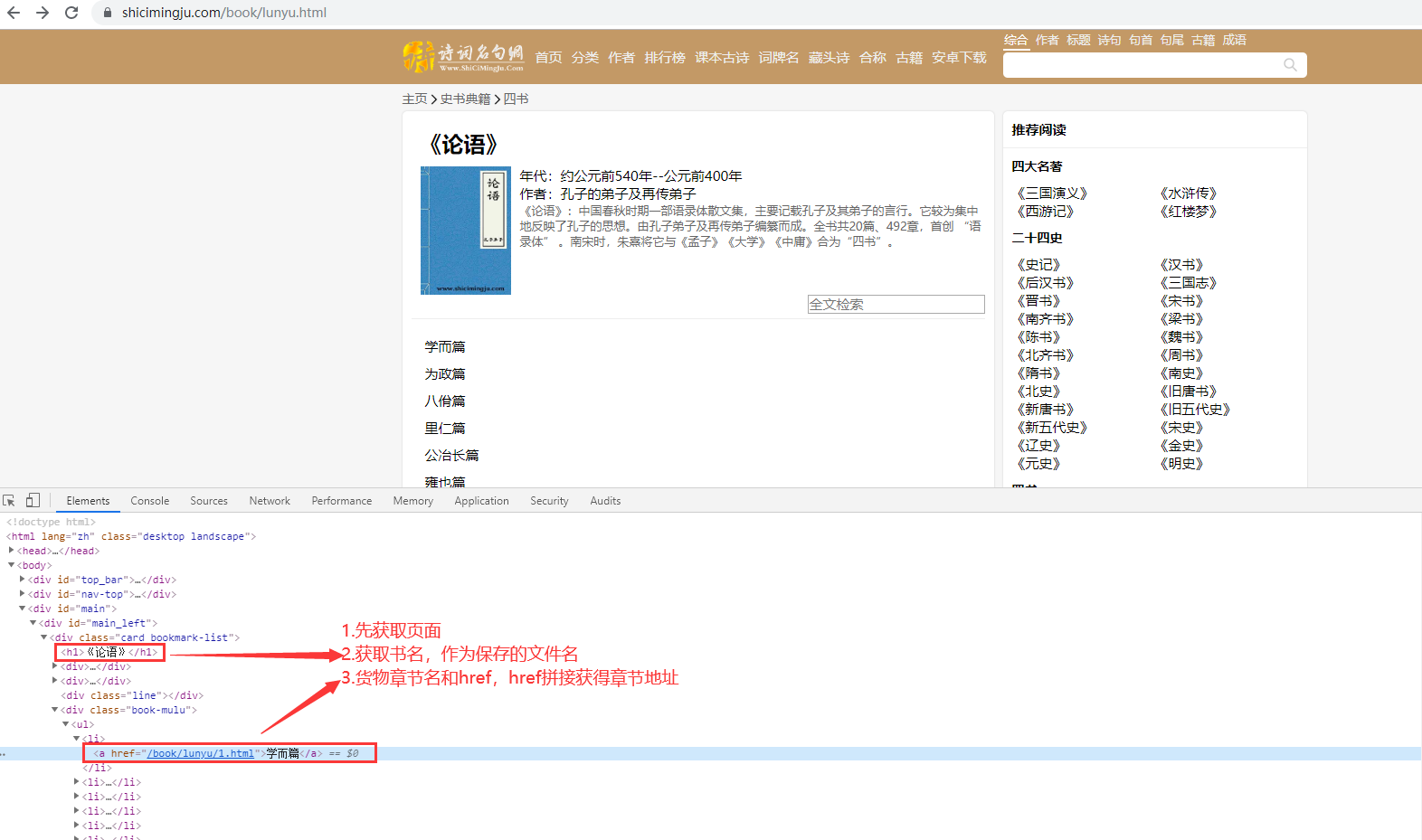
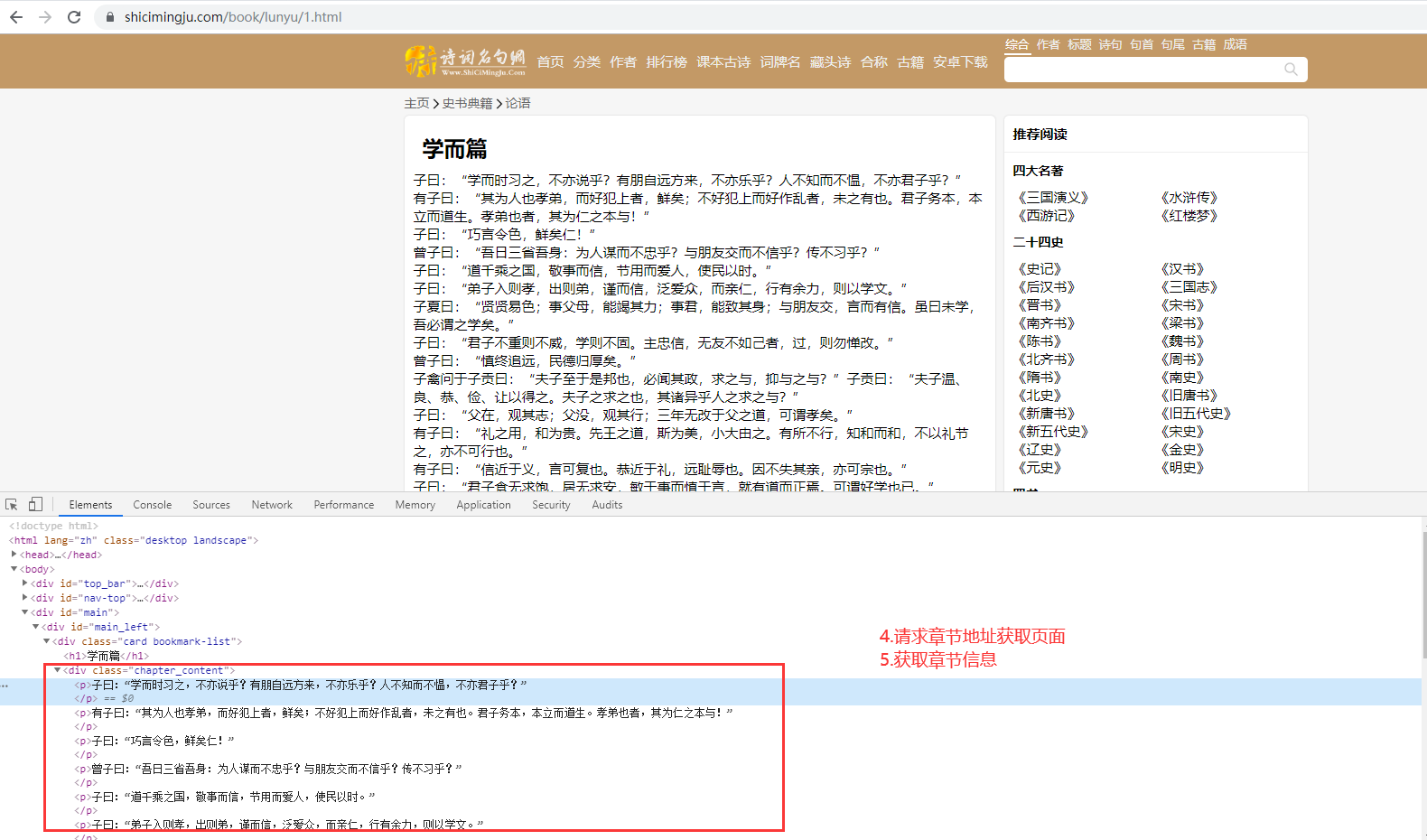
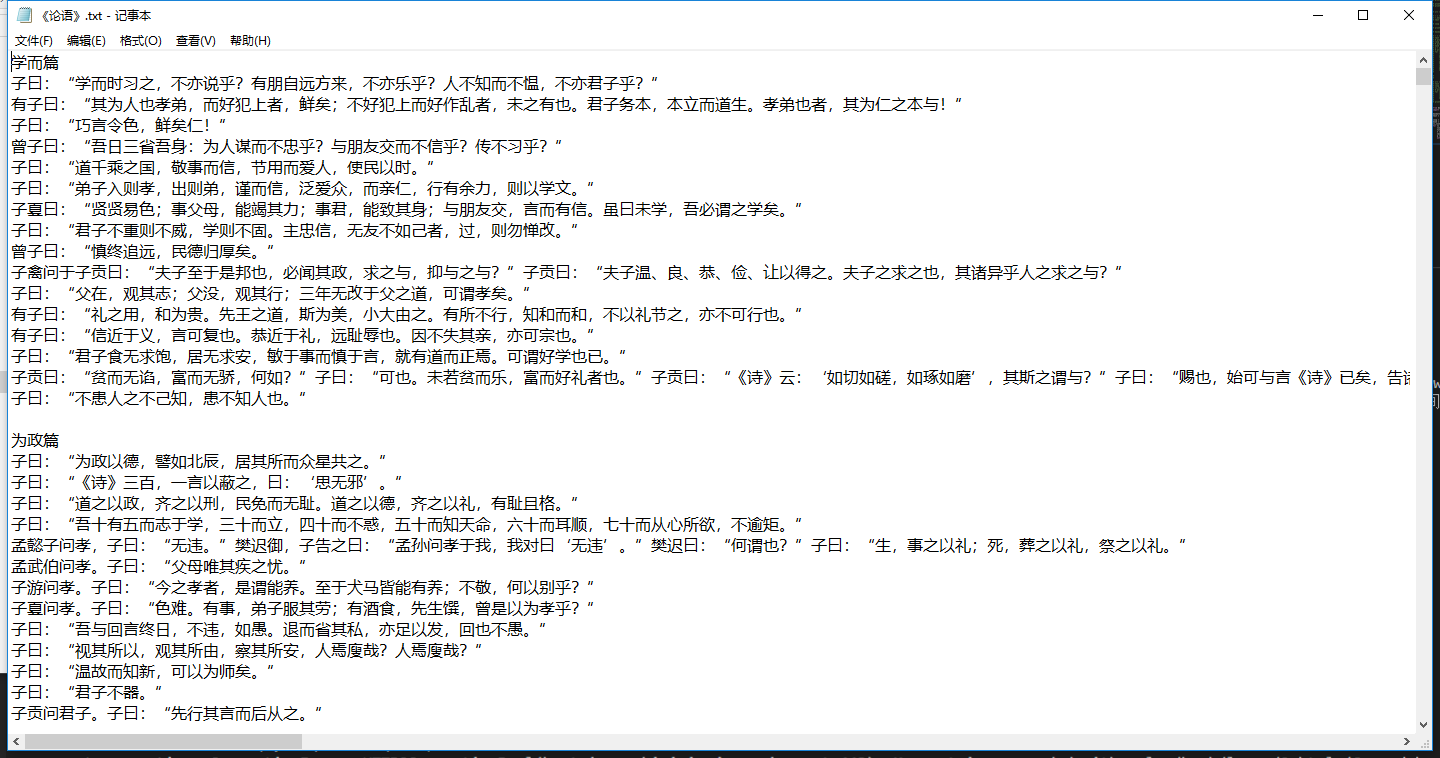
from bs4 import BeautifulSoup import requests baseurl = "https://www.shicimingju.com" text = requests.get(baseurl+"/book/lunyu.html").text soup = BeautifulSoup(text, "html.parser") book = soup.h1.text #获取书名 li_list = soup.find("div",class_ = "book-mulu").ul.find_all("li") #目录所在的所有li标签 for li in li_list: link = li.a.get("href") #获取章节地址 title = li.a.text #获取章节名 t = requests.get(baseurl+link).text soup2 = BeautifulSoup(t,"html.parser") p = soup2.find("div", class_ = "chapter_content").text with open ("E:\"+book+".txt", "a",encoding = "UTF-8") as f: #如果不加encoding,会报错UnicodeEncodeError: 'gbk' codec can't encode character 'xXX' in position XX: illegal multibyte sequence f.write(title) #章节名 f.write(p) #写入章节内容 f.write(" ") #一章空一行
2.图片之家下载图片
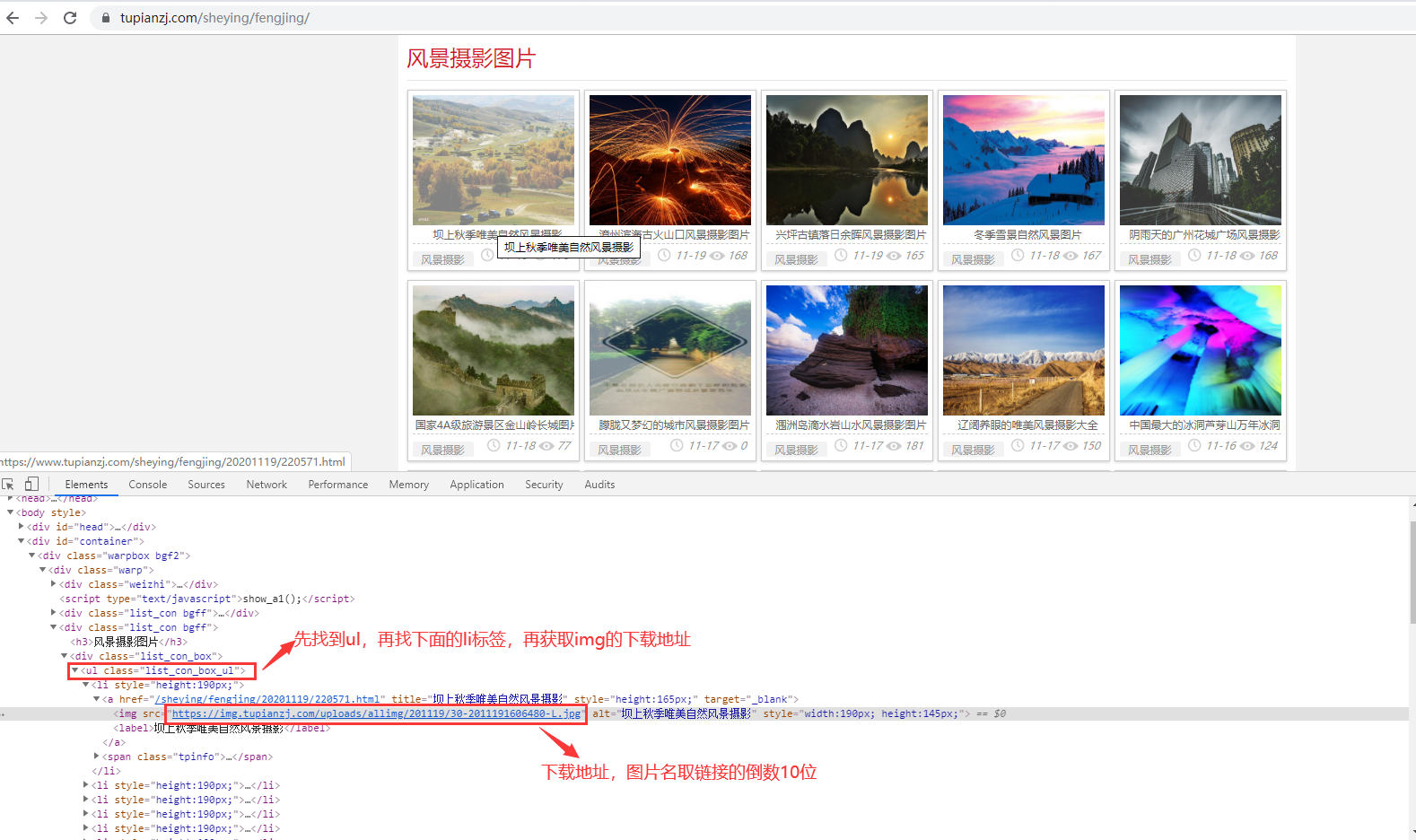
from bs4 import BeautifulSoup import requests url = "https://www.tupianzj.com/sheying/fengjing/" text = requests.get(url).text soup = BeautifulSoup(text, "html.parser") li_list = soup.find("ul", class_ = "list_con_box_ul").children #先根据class属性找到ul标签,再找儿子标签li print(list(li_list)) #打印出来的列表首尾有“ ” for i in list(li_list)[1:-1]: #去掉首尾的" " img_url = i.a.img.get("src") #获取图片地址 c = requests.get(img_url).content #图片是字节码形式解析 with open("E:\图片\"+img_url[-11:], "wb") as f: f.write(c) print("第一页图片下载完成")