Hadoop部署 Ubuntu14.04
Hadoop有3种部署方式。
单机模式,伪分布模式,完全分布式(集群,3个节点)。
一、单机模式
1 基础环境
1.1创建hadoop用户组
sudo addgroup hadoop
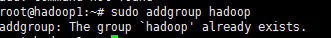
1.2创建hadoop用户
sudo adduser -ingroup hadoop hadoop
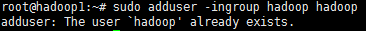
1.3为hadoop用户添加权限
输入:sudo gedit /etc/sudoers
回车,打开sudoers文件
给hadoop用户赋予和root用户同样的权限
1.4用新增加的hadoop用户登录Ubuntu系统
su Hadoop
1.5安装ssh
sudo apt-get install openssh-server
1.6设置免密码登录,生成私钥和公钥
ssh-keygen -t rsa -P ""
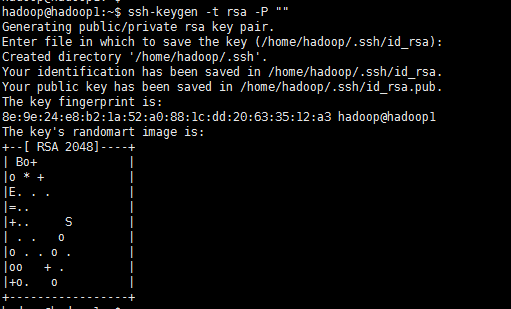
此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容。
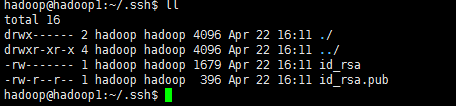
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
1.7验证登录ssh
ssh localhost
2 安装部署
2.1 安装Java环境
先去 Oracle下载Linux下的JDK压缩包,我下载的是jdk-7u79-linux64.gz文件,下好后直接解压
tar –zxvf jdk-7u79-linux64.gz
Step1:
# 将解压好的jdk1.7.0_79文件夹用最高权限复制到/usr/lib/jvm目录里
sudo cp -r ~/jdk1.7.0_79/ /usr/lib/jvm/
Step2:
# 配置环境变量
sudo gedit ~/.profile
在末尾加上:
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79
然后保存关闭,使用source更新下
$ source ~/.profile
使用env命令察看JAVA_HOME的值
$ env
如果JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79,说明配置成功。
Step3:
# 将系统默认的jdk修改过来
$ sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.7.0_79/bin/java 300
输入sun jdk前的数字就好了
$ sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.7.0_79/bin/javac 300
$ sudo update-alternatives --config java
$ sudo update-alternatives --config javac
Step4:
然后再输入java -version,看到如下信息,就说明改成sun的jdk了:
java version "1.7.0_04"
Java(TM) SE Runtime Environment (build 1.7.0_04-b20)
Java HotSpot(TM) Server VM (build 23.0-b21, mixed mode)

2.2 安装hadoop2.6.0
官网下载:
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.0/
安装:
解压
sudo tar xzf hadoop-2.6.0.tar.gz
假如我们要把hadoop安装到/usr/local下
拷贝到/usr/local/下,文件夹为hadoop
sudo mv hadoop-2.6.0 /usr/local/hadoop
赋予用户对该文件夹的读写权限
sudo chmod 774 /usr/local/hadoop
配置:
1)配置~/.bashrc
配置该文件前需要知道Java的安装路径,用来设置JAVA_HOME环境变量,可以使用下面命令行查看安装路径
update-alternatives - -config java
执行结果如下:

完整的路径为
/usr/lib/jvm/jdk1.7.0_79/jre/bin/java
我们只取前面的部分 /usr/lib/jvm/jdk1.7.0_79
配置.bashrc文件
sudo gedit ~/.bashrc
该命令会打开该文件的编辑窗口,在文件末尾追加下面内容,然后保存,关闭编辑窗口。
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
最终结果如下图:
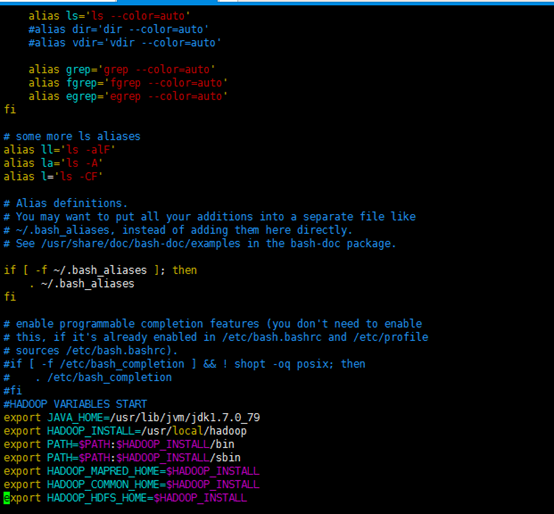
执行下面命,使添加的环境变量生效:
source ~/.bashrc
2)编辑/usr/local/hadoop/etc/hadoop/hadoop-env.sh
执行下面命令,打开该文件的编辑窗口
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到JAVA_HOME变量,修改此变量如下
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79
修改后的hadoop-env.sh文件如下所示:
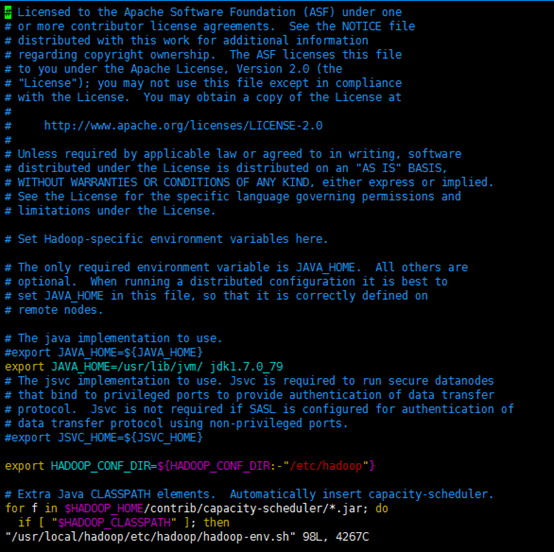
2.3 WordCount测试
单机模式安装完成,下面通过执行hadoop自带实例WordCount验证是否安装成功。
/usr/local/hadoop路径下创建input文件夹
mkdir input
拷贝README.txt到input
cp README.txt input
执行WordCount
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-sources.jar org.apache.hadoop.examples.WordCount input output
执行结果:
root@hadoop1:/usr/local/hadoop# bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-sources.jar org.apache.hadoop.examples.WordCount input output
/usr/local/hadoop/etc/hadoop/hadoop-env.sh: line 26: export: `jdk1.7.0_79': not a valid identifier
15/04/22 17:46:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/04/22 17:46:20 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
15/04/22 17:46:20 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
15/04/22 17:46:20 INFO input.FileInputFormat: Total input paths to process : 1
15/04/22 17:46:20 INFO mapreduce.JobSubmitter: number of splits:1
15/04/22 17:46:21 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local513316183_0001
15/04/22 17:46:21 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
15/04/22 17:46:21 INFO mapreduce.Job: Running job: job_local513316183_0001
15/04/22 17:46:21 INFO mapred.LocalJobRunner: OutputCommitter set in config null
15/04/22 17:46:21 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
15/04/22 17:46:21 INFO mapred.LocalJobRunner: Waiting for map tasks
15/04/22 17:46:21 INFO mapred.LocalJobRunner: Starting task: attempt_local513316183_0001_m_000000_0
15/04/22 17:46:21 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/04/22 17:46:21 INFO mapred.MapTask: Processing split: file:/usr/local/hadoop/input/README.txt:0+1366
15/04/22 17:46:21 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
15/04/22 17:46:21 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
15/04/22 17:46:21 INFO mapred.MapTask: soft limit at 83886080
15/04/22 17:46:21 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
15/04/22 17:46:21 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
15/04/22 17:46:21 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
15/04/22 17:46:21 INFO mapred.LocalJobRunner:
15/04/22 17:46:21 INFO mapred.MapTask: Starting flush of map output
15/04/22 17:46:21 INFO mapred.MapTask: Spilling map output
15/04/22 17:46:21 INFO mapred.MapTask: bufstart = 0; bufend = 2055; bufvoid = 104857600
15/04/22 17:46:21 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26213684(104854736); length = 713/6553600
15/04/22 17:46:21 INFO mapred.MapTask: Finished spill 0
15/04/22 17:46:21 INFO mapred.Task: Task:attempt_local513316183_0001_m_000000_0 is done. And is in the process of committing
15/04/22 17:46:21 INFO mapred.LocalJobRunner: map
15/04/22 17:46:21 INFO mapred.Task: Task 'attempt_local513316183_0001_m_000000_0' done.
15/04/22 17:46:21 INFO mapred.LocalJobRunner: Finishing task: attempt_local513316183_0001_m_000000_0
15/04/22 17:46:21 INFO mapred.LocalJobRunner: map task executor complete.
15/04/22 17:46:21 INFO mapred.LocalJobRunner: Waiting for reduce tasks
15/04/22 17:46:21 INFO mapred.LocalJobRunner: Starting task: attempt_local513316183_0001_r_000000_0
15/04/22 17:46:21 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/04/22 17:46:21 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5535c2c7
15/04/22 17:46:21 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=333971456, maxSingleShuffleLimit=83492864, mergeThreshold=220421168, ioSortFactor=10, memToMemMergeOutputsThreshold=
1015/04/22 17:46:21 INFO reduce.EventFetcher: attempt_local513316183_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
15/04/22 17:46:22 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local513316183_0001_m_000000_0 decomp: 1832 len: 1836 to MEMORY
15/04/22 17:46:22 INFO reduce.InMemoryMapOutput: Read 1832 bytes from map-output for attempt_local513316183_0001_m_000000_0
15/04/22 17:46:22 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 1832, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->1832
15/04/22 17:46:22 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
15/04/22 17:46:22 INFO mapred.LocalJobRunner: 1 / 1 copied.
15/04/22 17:46:22 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
15/04/22 17:46:22 INFO mapred.Merger: Merging 1 sorted segments
15/04/22 17:46:22 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1823 bytes
15/04/22 17:46:22 INFO reduce.MergeManagerImpl: Merged 1 segments, 1832 bytes to disk to satisfy reduce memory limit
15/04/22 17:46:22 INFO reduce.MergeManagerImpl: Merging 1 files, 1836 bytes from disk
15/04/22 17:46:22 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
15/04/22 17:46:22 INFO mapred.Merger: Merging 1 sorted segments
15/04/22 17:46:22 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1823 bytes
15/04/22 17:46:22 INFO mapred.LocalJobRunner: 1 / 1 copied.
15/04/22 17:46:22 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
15/04/22 17:46:22 INFO mapred.Task: Task:attempt_local513316183_0001_r_000000_0 is done. And is in the process of committing
15/04/22 17:46:22 INFO mapred.LocalJobRunner: 1 / 1 copied.
15/04/22 17:46:22 INFO mapred.Task: Task attempt_local513316183_0001_r_000000_0 is allowed to commit now
15/04/22 17:46:22 INFO output.FileOutputCommitter: Saved output of task 'attempt_local513316183_0001_r_000000_0' to file:/usr/local/hadoop/output/_temporary/0/task_local513316183_0001_r_00000
015/04/22 17:46:22 INFO mapred.LocalJobRunner: reduce > reduce
15/04/22 17:46:22 INFO mapred.Task: Task 'attempt_local513316183_0001_r_000000_0' done.
15/04/22 17:46:22 INFO mapred.LocalJobRunner: Finishing task: attempt_local513316183_0001_r_000000_0
15/04/22 17:46:22 INFO mapred.LocalJobRunner: reduce task executor complete.
15/04/22 17:46:22 INFO mapreduce.Job: Job job_local513316183_0001 running in uber mode : false
15/04/22 17:46:22 INFO mapreduce.Job: map 100% reduce 100%
15/04/22 17:46:22 INFO mapreduce.Job: Job job_local513316183_0001 completed successfully
15/04/22 17:46:22 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=547400
FILE: Number of bytes written=1048794
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=31
Map output records=179
Map output bytes=2055
Map output materialized bytes=1836
Input split bytes=104
Combine input records=179
Combine output records=131
Reduce input groups=131
Reduce shuffle bytes=1836
Reduce input records=131
Reduce output records=131
Spilled Records=262
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=60
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=404750336
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1366
File Output Format Counters
Bytes Written=1326
执行 cat output/*,查看字符统计结果
root@hadoop1:/usr/local/hadoop# cat output/*
(BIS), 1
(ECCN) 1
(TSU) 1
(see 1
5D002.C.1, 1
740.13) 1
<http://www.wassenaar.org/> 1
Administration 1
Apache 1
BEFORE 1
BIS 1
Bureau 1
Commerce, 1
Commodity 1
Control 1
Core 1
Department 1
ENC 1
Exception 1
Export 2
For 1
Foundation 1
Government 1
Hadoop 1
Hadoop, 1
Industry 1
Jetty 1
License 1
Number 1
Regulations, 1
SSL 1
Section 1
Security 1
See 1
Software 2
Technology 1
The 4
This 1
U.S. 1
Unrestricted 1
about 1
algorithms. 1
and 6
and/or 1
another 1
any 1
as 1
asymmetric 1
at: 2
both 1
by 1
check 1
classified 1
code 1
code. 1
concerning 1
country 1
country's 1
country, 1
cryptographic 3
currently 1
details 1
distribution 2
eligible 1
encryption 3
exception 1
export 1
following 1
for 3
form 1
from 1
functions 1
has 1
have 1
http://hadoop.apache.org/core/ 1
http://wiki.apache.org/hadoop/ 1
if 1
import, 2
in 1
included 1
includes 2
information 2
information. 1
is 1
it 1
latest 1
laws, 1
libraries 1
makes 1
manner 1
may 1
more 2
mortbay.org. 1
object 1
of 5
on 2
or 2
our 2
performing 1
permitted. 1
please 2
policies 1
possession, 2
project 1
provides 1
re-export 2
regulations 1
reside 1
restrictions 1
security 1
see 1
software 2
software, 2
software. 2
software: 1
source 1
the 8
this 3
to 2
under 1
use, 2
uses 1
using 2
visit 1
website 1
which 2
wiki, 1
with 1
written 1
you 1
your 1
二、伪分布模式(单节点集群)
在单机模式的基础上进行伪分布模式的部署。
1、配置core-site.xml
/usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。
编辑器中打开此文件
sudo vi /usr/local/hadoop/etc/hadoop/core-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
保存、关闭编辑窗口。
最终修改后的文件内容如下:
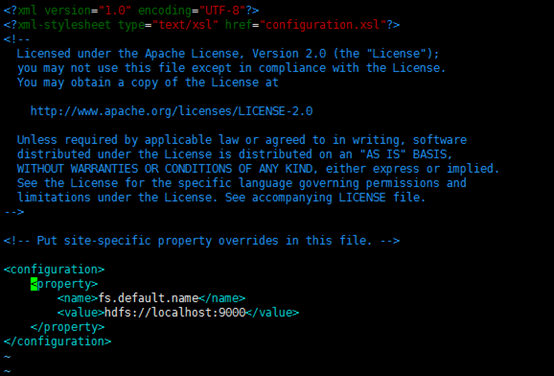
2、配置yarn-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml包含了MapReduce启动时的配置信息。
编辑器中打开此文件
sudo vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
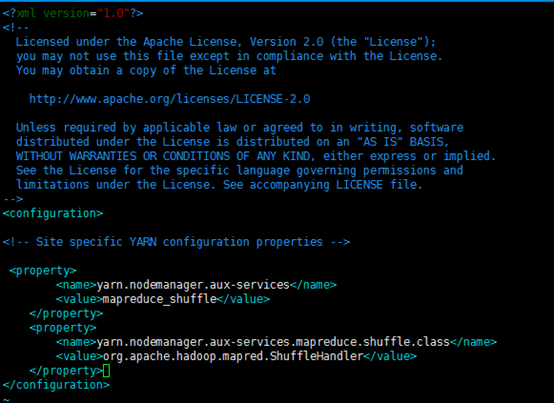
3、创建和配置mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
复制并重命名
cd /usr/local/hadoop/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
sudo vi mapred-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
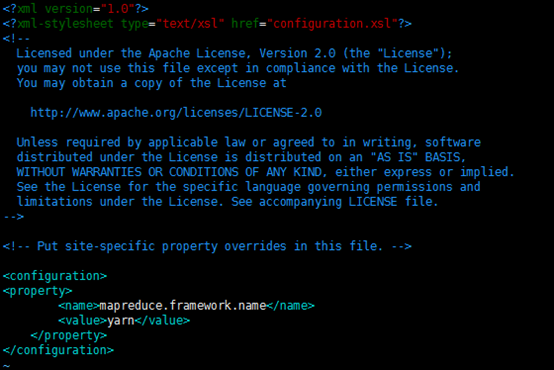
4、配置hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。
创建文件夹
cd /usr/local/hadoop
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data
cd hdfs
ls
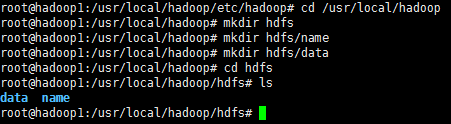
你也可以在别的路径下创建上图的文件夹,名称也可以与上图不同,但是需要和hdfs-site.xml中的配置一致。
sudo vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
编辑器打开hdfs-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下:
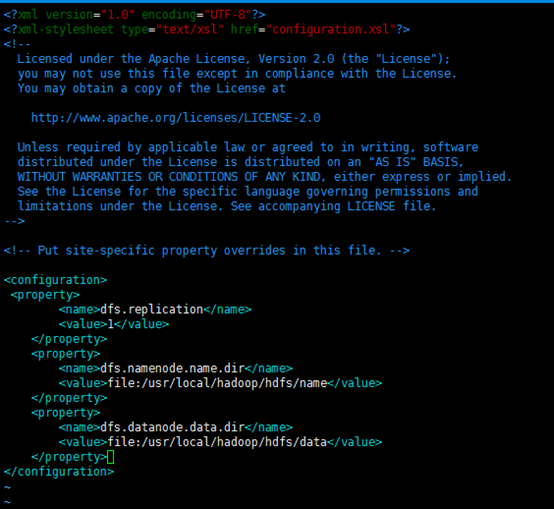
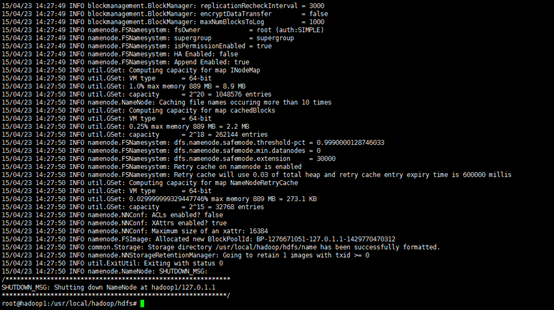
5、格式化hdfs
hdfs namenode -format
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
6、启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群
执行启动命令:
sbin/start-dfs.sh
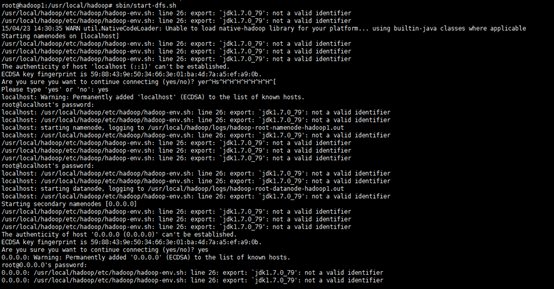

出现错误:
root@hadoop1:/usr/local/hadoop# sbin/start-dfs.sh
15/04/23 14:34:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
root@localhost's password:
localhost: namenode running as process 2296. Stop it first.
root@localhost's password:
localhost: datanode running as process 2449. Stop it first.
Starting secondary namenodes [0.0.0.0]
root@0.0.0.0's password:
0.0.0.0: secondarynamenode running as process 2634. Stop it first.
15/04/23 14:34:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
root@hadoop1:/usr/local/hadoop#
执行该命令时,如果有yes /no提示,输入yes,回车即可。
接下来,执行:
sbin/start-yarn.sh

执行完这两个命令后,Hadoop会启动并运行
执行 jps命令,会看到Hadoop相关的进程:
出现错误:
root@hadoop1:/usr/local/hadoop# jps
The program 'jps' can be found in the following packages:
* openjdk-7-jdk
* openjdk-6-jdk
Try: apt-get install <selected package>
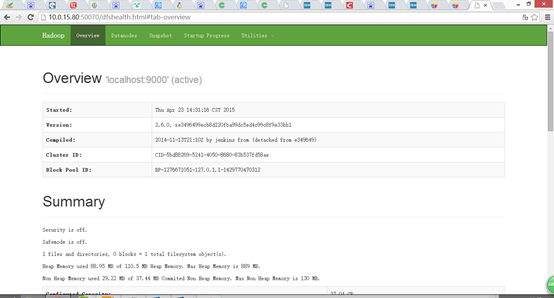
浏览器打开 http://10.0.15.80:50070/,会看到hdfs管理页面
浏览器打开http://10.0.15.80:8088,会看到hadoop进程管理页面
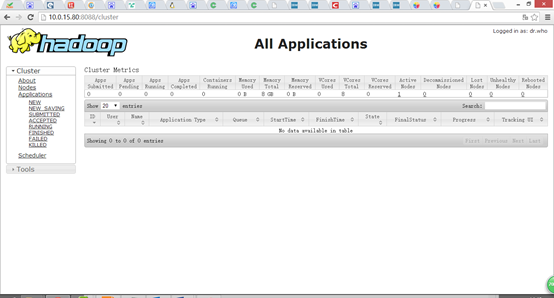
7、WordCount验证
dfs上创建input目录
bin/hadoop fs -mkdir -p input

把hadoop目录下的README.txt拷贝到dfs新建的input里
hadoop fs -copyFromLocal README.txt input

运行WordCount
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-sources.jar org.apache.hadoop.examples.WordCount input output
可以看到执行过程
root@hadoop1:/usr/local/hadoop# hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-sources.jar org.apache.hadoop.examples.WordCount input output
15/04/23 14:53:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/04/23 14:53:08 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/04/23 14:53:09 INFO input.FileInputFormat: Total input paths to process : 1
15/04/23 14:53:10 INFO mapreduce.JobSubmitter: number of splits:1
15/04/23 14:53:10 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1429770996011_0001
15/04/23 14:53:10 INFO impl.YarnClientImpl: Submitted application application_1429770996011_0001
15/04/23 14:53:10 INFO mapreduce.Job: The url to track the job: http://hadoop1:8088/proxy/application_1429770996011_0001/
15/04/23 14:53:10 INFO mapreduce.Job: Running job: job_1429770996011_0001
15/04/23 14:53:21 INFO mapreduce.Job: Job job_1429770996011_0001 running in uber mode : false
15/04/23 14:53:21 INFO mapreduce.Job: map 0% reduce 0%
15/04/23 14:53:28 INFO mapreduce.Job: map 100% reduce 0%
15/04/23 14:53:37 INFO mapreduce.Job: map 100% reduce 100%
15/04/23 14:53:38 INFO mapreduce.Job: Job job_1429770996011_0001 completed successfully
15/04/23 14:53:38 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1836
FILE: Number of bytes written=215161
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1479
HDFS: Number of bytes written=1306
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4895
Total time spent by all reduces in occupied slots (ms)=6804
Total time spent by all map tasks (ms)=4895
Total time spent by all reduce tasks (ms)=6804
Total vcore-seconds taken by all map tasks=4895
Total vcore-seconds taken by all reduce tasks=6804
Total megabyte-seconds taken by all map tasks=5012480
Total megabyte-seconds taken by all reduce tasks=6967296
Map-Reduce Framework
Map input records=31
Map output records=179
Map output bytes=2055
Map output materialized bytes=1836
Input split bytes=113
Combine input records=179
Combine output records=131
Reduce input groups=131
Reduce shuffle bytes=1836
Reduce input records=131
Reduce output records=131
Spilled Records=262
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=108
CPU time spent (ms)=1830
Physical memory (bytes) snapshot=424964096
Virtual memory (bytes) snapshot=1383133184
Total committed heap usage (bytes)=276824064
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1366
File Output Format Counters
Bytes Written=1306
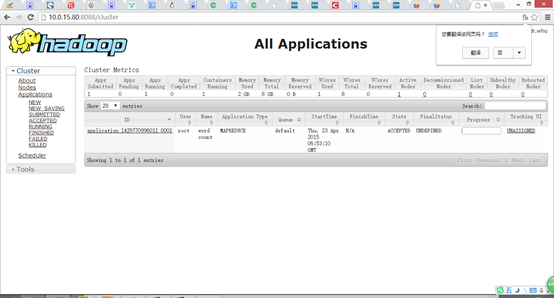
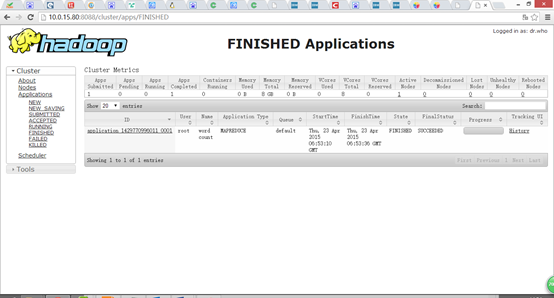
运行完毕后,查看单词统计结果
hadoop fs -cat output/*
执行结果:
root@hadoop1:/usr/local/hadoop# hadoop fs -cat output/*
15/04/23 14:54:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(BIS), 1
(ECCN) 1
(TSU) 1
(see 1
5D002.C.1, 1
740.13) 1
<http://www.wassenaar.org/> 1
Administration 1
Apache 1
BEFORE 1
BIS 1
Bureau 1
Commerce, 1
Commodity 1
Control 1
Core 1
Department 1
ENC 1
Exception 1
Export 2
For 1
Foundation 1
Government 1
Hadoop 1
Hadoop, 1
Industry 1
Jetty 1
License 1
Number 1
Regulations, 1
SSL 1
Section 1
Security 1
See 1
Software 2
Technology 1
The 4
This 1
U.S. 1
Unrestricted 1
about 1
algorithms. 1
and 6
and/or 1
another 1
any 1
as 1
asymmetric 1
at: 2
both 1
by 1
check 1
classified 1
code 1
code. 1
concerning 1
country 1
country's 1
country, 1
cryptographic 3
currently 1
details 1
distribution 2
eligible 1
encryption 3
exception 1
export 1
following 1
for 3
form 1
from 1
functions 1
has 1
have 1
http://hadoop.apache.org/core/ 1
http://wiki.apache.org/hadoop/ 1
if 1
import, 2
in 1
included 1
includes 2
information 2
information. 1
is 1
it 1
latest 1
laws, 1
libraries 1
makes 1
manner 1
may 1
more 2
mortbay.org. 1
object 1
of 5
on 2
or 2
our 2
performing 1
permitted. 1
please 2
policies 1
possession, 2
project 1
provides 1
re-export 2
regulations 1
reside 1
restrictions 1
security 1
see 1
software 2
software, 2
software. 2
software: 1
source 1
the 8
this 3
to 2
under 1
use, 2
uses 1
using 2
visit 1
website 1
which 2
wiki, 1
with 1
written 1
you 1
your 1
三、完全分布式(3个节点集群)
集群,必须3个节点。
|
主机 |
角色 |
备注 |
|
Hadoop-Master |
NameNode,JobTracker |
|
|
Hadoop-Node1 |
DataNode,TaskTracker |
|
|
Hadoop-Node2 |
DataNode,TaskTracker |
参考:
http://jingyan.baidu.com/article/27fa73269c02fe46f9271f45.html
http://www.cnblogs.com/yhason/archive/2013/05/30/3108908.html
http://www.linuxidc.com/Linux/2015-01/112029.htm