这次是通过CNN来处理训练mnist数据集,CNN的结构是根据视频学的最简单的结构,在模型编译后使用model.summary()就可以将模型结构显示出来,如下图。也有另一种方法plot_model(model, to_file = 'model.png',show_shapes = True),这个显示出来的就比上一种好看,这个是直接输出图片,里面是一种有向图,很直接的将模型结构画出来了。
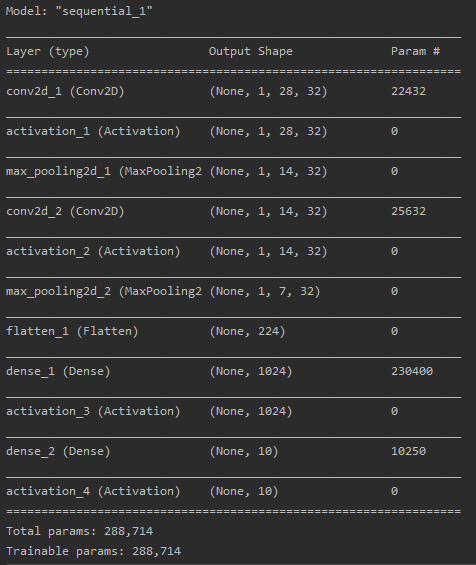
卷积——>池化——>卷积——>池化——>全连接——>全连接,就这么简单,不过在每个卷积和全连接层后有个激活函数层。
这次我想着把mnist里面究竟是什么东西搞清楚,所以就有了下面的代码:
def plot_x_y():
(x_train, y_train), (x_test, y_test) = mnist.load_data() # x:60000*28*28,y:60000
# 可视化x_train
for i in range(10):
img = Image.fromarray(x_train[i]) #这个代码是将数组转成图片格式,理论上只要是数组形式的数据都可以#可视化。
#因为颜色属性是在0-255之间,所以一般数组里面的值在0-255之间才有颜色显示,如果高于255
#可视化的时候就采取255代替,也就是显示白色;反之小于0就是黑色。
plt.imshow(img)
plt.show()
# 可视化一下y,然后我就没事干,想看一下y,但是因为原本的y是一个一维数组,里面有60000个0-9之间的数字,因此这个看起来没啥意思,
#所以需要下面的代码将y处理成独热(one hot)标签。
y_train = np_utils.to_categorical(y_train, num_classes=10)
for i in range(10):
if y_train[0][i] == 1: #啊,这一步,因为one hot里面只有0,1,他两颜色太接近,可视化看不出来,所以将
#1变成255,这样显示就是白色,有明显对比了。
y_train[0][i] = 255
img = Image.fromarray(y_train[0])
plt.imshow(img)
plt.show()
x里面的图片显示出来就是下面这样子,只显示了前10张图片:

y可视出来了是这个样子,其实没啥看的,就是好玩,我把它横过来了,正常是竖着的:
然后就是正规工作了,代码如下:
import numpy as np
import pickle as p
from PIL import Image
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Activation, Convolution2D, MaxPooling2D, Dense, Flatten
from keras.utils import np_utils
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import matplotlib.image as plimg
from keras.utils.vis_utils import plot_model as plt_
(x_train, y_train), (x_test, y_test) = mnist.load_data() #x:60000*28*28,y:60000
x_train = x_train.reshape(-1, 1, 28, 28) #转成n个(1*28*28)的数据,1为高,
x_test = x_test.reshape(-1, 1, 28, 28) #
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
#搭建模型
model = Sequential()
###第一层需要写入输入尺寸,后面的不需要,但是在全连接时要写输出层数,卷积层处理完后要加一个激活函数层
#卷积: 输入:1*28*28 输出:32*28*28
model.add(Convolution2D(filters=32, #卷积核数目,也是输出通道数(高度)
kernel_size=(5, 5), #卷积核为5*5
padding='same', #padding,确保长宽不变
input_shape=(1, 28, 28) #输入
))
model.add(Activation('relu'))
###池化通道数不变,长宽减半,卷积长宽不变,高度增加
#池化: 输入:32*28*28 输出:32*14*14
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='same',
))
#卷积: 输入:32*14*14 输出:64*14*14
model.add(Convolution2D(filters=32,
kernel_size=(5, 5),
padding='same',
))
model.add(Activation('relu'))
#池化: 输入:64*14*14 输出:64*7*7
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='same',
))
#全连接: 输入:64*7*7=3136 输出:1024(自己设置)
model.add(Flatten()) #Flatten将64*7*7变成3136
model.add(Dense(1024))
model.add(Activation('relu'))
#全连接: 输入:1024 输出:10
model.add(Dense(10))
model.add(Activation('softmax'))
#编译模型,
adam = Adam(lr=0.0001) #优化器
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary() #将模型结构输出
#训练
print("-------------------train--------------")
model.fit(x_train, y_train, epochs=2, batch_size=100) #因为总数据有60000个,所以batch_size就写100了。
#epochs设置1/2结果就挺可观了,不需要设置太大了
#测试
print("---------------------test--------------")
loss, accuracy = model.evaluate(x_test, y_test)
print(loss, accuracy)
下面是训练过程:

最后测试集的loss和准确度分别有0.17145和0.94919,结果还是挺高的