计算逻辑
先计算WOE值,再计算IV值。
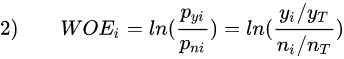
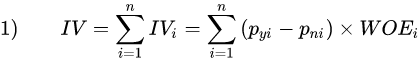
其中Y或N分别是YES,NO,反应在因变量中,就是1和0。
- Yi是第i组中1的个数,YT是所有(Total)为1的个数。
- Ni是第i组中0的个数,NT是所有(Total)为0的个数。
举例
数据如下,x分别取1-9,y对应是1和0。
x,y
1,1
2,1
3,0
4,1
5,1
6,0
7,0
8,0
9,1
如果对于x这9行数据分成三组:
- 第0组:x=1,2,3
- 第1组:x=4,5,6
- 第2组:x=7,8,9
则第0组的WEO值计算过程如下。
- Y0=2,因为
分组内当x=1,2的时候y是1,共两个1,则是2. - YT=5,因为y这一列总共有5个1。
- N0=1,因为
分组内当x=3的时候y是0,共1个1,则是1. - NT=4,因为y这一列共有4个0.
WOE_0
=ln((2/5)/(1/4))
=ln(0.4/0.25)
=ln(1.6)
=0.47
有了WOE,开始计算IV:
IV_0
=(2/5-1/4)*WOE_0
=0.15*0.47
=0.0705
于是可计算出IV_0=0.0705。 同理可计算出IV_1= 0.070501, IV_2=0.274887。 则该X的iv即 iv=iv_0+iv_2+iv_3=0.415888
Python代码
import pandas as pd
import numpy as np
def iv_woe(data:pd.DataFrame, target:str, bins:int = 10) -> (pd.DataFrame, pd.DataFrame):
"""计算woe和IV值
参数:
- data: dataframe数据
- target: y列的名称
- bins: 分箱数(默认是10)
"""
newDF,woeDF = pd.DataFrame(), pd.DataFrame()
cols = data.columns
for ivars in cols[~cols.isin([target])]:
# 数据类型在bifc中、且数据>10则分箱
if (data[ivars].dtype.kind in 'bifc') and (len(np.unique(data[ivars]))>10):
binned_x = pd.qcut(data[ivars], bins, duplicates='drop')
d0 = pd.DataFrame({'x': binned_x, 'y': data[target]})
else:
d0 = pd.DataFrame({'x': data[ivars], 'y': data[target]})
d = d0.groupby("x", as_index=False).agg({"y": ["count", "sum"]})
d.columns = ['Cutoff', 'N', 'Events']
d['% of Events'] = np.maximum(d['Events'], 0.5) / d['Events'].sum()
d['Non-Events'] = d['N'] - d['Events']
d['% of Non-Events'] = np.maximum(d['Non-Events'], 0.5) / d['Non-Events'].sum()
d['WoE'] = np.log(d['% of Events']/d['% of Non-Events'])
d['IV'] = d['WoE'] * (d['% of Events'] - d['% of Non-Events'])
d.insert(loc=0, column='Variable', value=ivars)
print("Information value of " + ivars + " is " + str(round(d['IV'].sum(),6)))
temp =pd.DataFrame({"Variable" : [ivars], "IV" : [d['IV'].sum()]}, columns = ["Variable", "IV"])
newDF=pd.concat([newDF,temp], axis=0)
woeDF=pd.concat([woeDF,d], axis=0)
return newDF, woeDF
调用
mydata = pd.read_csv("./data.csv",encoding='utf8')
newDF,woeDF=iv_woe(mydata,'y')
即可得到。注意,此处默认10组,上例中的x值是0-10,不足以分10组,则每个值为一组。注意其中的if判断语句