面试主要分为两块: -块是考查工程师对基础知识(包括了技术广度、深度、对技术的热情度等)的掌握程度,因为基础知识决定了一个技术人员发展的上限;另一块是考察工程师的工程能,力,比如:做过哪些项目?遇到最难的问题怎样解决的?说说最有成就感的一项任务?工程能力考察工程师当下能为公司带来的利益。
其它考核方面:抗压性、合作能..暂且不说。
Java只是一-门语言,即使是Java工程师也不能局限于Java,要从面向对象语言本身,甚至从整个计算机体系,从工程实际出发看Java。
很多知识在一般公司的开发中是用不到的,常有人戏称:“面试造火箭, 工作拧螺丝”,但这只是通常情况下公司对程序员的标准一迅速产出,完成任务。
个人观点:工程师为了自己职业的发
展不能局限于公司对自己的要求,不能停留在应用层面,要能够很好地掌握基础知识,要多看源码,自己多实践,学成记得产出,比如多为开源社区贡献代码,帮助初学者指路等。
有没有发现一个有意思的事情:“面试造火箭, 工作拧螺丝”的背后其实是考察者内心深处普遍都认可基础知识的重要性(这-点仅为个人观点, 不展开讲哈)。
下面为拼多多、饿了么、蚂蚁金服、哈哕出行、携程、饿了么、2345、 百度等公司给我留下较深印象的一些java面试题
1. private修饰的方法可以通过反射访问,那么private的意 义是什么
2. Java类初始化顺序
3.对方法区和永久区的理解以及它们之间的关系
4.一个java文件有3个类,编译后有几个class文件
5.局部变量使用前需要显式地赋值,否则编译通过不了 ,为什么这么设计
6. ReadWriteLock读写之间互斥吗
7. Semaphore拿到执行权的线程之间是否互斥
8.写一个你认为最好的单例模式
9. B树和B +树是解决什么样的问题的,怎样演化过来,之间区别
10.写一个生产者消费者模式
11.写一个死锁
12. cpu 100%怎样定位
13. Stringa = "ab"; Stringb= "a" + "b";a == b是否相等,为什么
14. inta= 1;是原子性操作吗
15.可以用for循环直接删除ArrayList的特定元素吗?可能会出现什么问题?怎样解决
16.新的任务提交到线程池,线程池是怎样处理
17. AQS和CAS原理
18. synchronized底层实现原理
19. volatile作用,指令重排相关
20. AOP和IOC原理
21. Spring怎样解决循环依赖的问题
22. dispatchServlet怎样分发任务的
23. mysq|给离散度低的字段建立索引会出现什么问题,具体说下原因
2. Java类初始化顺序
3.对方法区和永久区的理解以及它们之间的关系
4.一个java文件有3个类,编译后有几个class文件
5.局部变量使用前需要显式地赋值,否则编译通过不了 ,为什么这么设计
6. ReadWriteLock读写之间互斥吗
7. Semaphore拿到执行权的线程之间是否互斥
8.写一个你认为最好的单例模式
9. B树和B +树是解决什么样的问题的,怎样演化过来,之间区别
10.写一个生产者消费者模式
11.写一个死锁
12. cpu 100%怎样定位
13. Stringa = "ab"; Stringb= "a" + "b";a == b是否相等,为什么
14. inta= 1;是原子性操作吗
15.可以用for循环直接删除ArrayList的特定元素吗?可能会出现什么问题?怎样解决
16.新的任务提交到线程池,线程池是怎样处理
17. AQS和CAS原理
18. synchronized底层实现原理
19. volatile作用,指令重排相关
20. AOP和IOC原理
21. Spring怎样解决循环依赖的问题
22. dispatchServlet怎样分发任务的
23. mysq|给离散度低的字段建立索引会出现什么问题,具体说下原因
其它经常问的HashMap底层实现原理,常规的多线程问题考的太多了,没什么新意就不写了
平时不能光抱着应用Java的目的去学习,要深入了解每个知识点背后底层实现原理,为什么这么设计,比如问烂的HashMap既然有hash进行排位还需要equals0作用是什么?就这个问题照样能问倒一些人,所以一定要抠细节,真的把每个知识点搞懂
以下为解答大纲,部分作了扩展
1.这题是一道思想题目,天天会碰到private,有没有想过这个问题?谈谈对java设计的认识程度,主要抓住两点:
1.java的private修饰符并不是为 了绝对安全性设计的,更多是对用户常规使用java的一种约束; 2.从外部对对象进行常规调用时,能够看到清晰的类结构。
2.先说结论:基类静态代码块, 基类静态成员字段(并列优先级,按照代码中出现的先后顺序执行,且职有第一次加载时执行) 一> 派生类静态代码块,派生类静态成员字段(并列优先级,按照代码中出现的先后顺序执行,且职有第一次加载时执行)一>基类普通代码块, 基类普通成员字段(并列优点级,按代码中出现先后顺序执行)一->基类构造函数一-> 派生 类普通代码块,派生类普通成员字段(并列优点级,按代码中出现先后顺序执行)一> 派生类构造函数
代码验证:


控制台结果输出:

3.方法区是jvm规范里要求的,永久区是Hotspot虚拟机对方法区的具体实现,前者是规范,储实现方式。jdk1.8作 了改变。本题看看对方在思想层面对jvm的理解程度,很基础的一个题目。
4.文件中有几个类编译后就有几个class文件。
5.成员变量是可以不经初始化的,在类加载过程的准备阶段即可给它赋予默认值,但局部变量使用前需要显式赋予初始值,javac不是推断不出不可以这样做,而是没有这样做,对于成员变量而言,其赋值和取值访问的先后顺序具有不确定性,对于成员变量可以在一个方法调用前赋值,也可以在方法调用后进行,这是运行时发生的,编译器确定不了,交给jvm去做比较合适。而对于局部变量而言,其赋值和取值访问顺序是确定的。这样设计是-种约束, 尽最大程度减少使用者犯错的可能
(假使局部变量可以使用默认值,可能总会无意间忘记赋值,进而导致不可预期的情况出现)
6. ReadWriteRock读写锁,使用场景可分为读/读、读/写、写/写,除了读和读之间是共享的,其它都是互斥的,接着会讨论下怎样实现互斥锁和同步锁的,想了解对方对AQS, CAS的掌握程度,技术学习的深度。
7. Semaphore拿到执行权的线程之间是否互斥,Semaphore、 CountDownL atch、CyclicBarrier、Exchanger 为java并发编程的4个辅助类,面试中常问的CountDownLatchCyclicBarrier之间的区别,面试者肯定是经常碰到的,所以问起来意 义不大,Semaphore问的相对少一些,有些知识点如果没有使用过还是会忽略,Semaphore可有 多把锁,可允许多个线程同时拥有执行权,这些有执行权的线程如并发访问同-对象,会产生线程安全问题。
8.写一个你认为最好的单例模式,这题面试者都可能遇到过, 也算是工作中最常遇到的设计模式之一,想考察面试者对经常碰到的题目的理解深度,单例一共有几种实现方式:饿汉、懒汉、静态内部类、枚举、双检锁,要是写了简单的懒汉式可能就会问:要是多线程情况下怎样保证线程安全呢,面试者可能说双检锁,那么聊聊为什么要两次校验,接着会问光是双检锁还会有什么问题,这时候基础好的面试者就会说了:对象在定义的时候加上volatile关键字,接下来会继续引申讨论下原子性和可见性、java内存模型、类的加载过程。
其实没有最好,枚举方式、静态内部类、双检锁都是可以的,就想听下对不同的单例写法认识程度,写个双检锁的方式吧:

9. B树和B+树,这题既问mysq|索弓的实现原理,也间数据结构基础,首先从二叉树说起,因为会产生退化现象,提出了平衡二叉树,再提出怎样让每一层放的节点多-些来减少遍历高度,引申出m叉树,m叉搜索树同样会有退化现象,引出m叉平衡树,也就是B树,这时候每个节点既放了key也放了value,怎样使每个节点放尽可能多的key值,以减少遍历高度呢(访问磁盘次数),可以将每个节点只放key值,将value值放在叶子结点,在叶子结点的value值增加指向相邻节点指针,这就是优化后的B +树。然后谈谈数据库
索弓|失效的情况,为什么给离散度低的字段(如性别)建立索引是不可取的,查询数据反而更慢,如果将离散度高的字段和性别建立联合索引会怎样,有什么需要注意的?
10.生产者消费者模式,synchronized锁住一 个LinkedList, -一个生产者,只要队列不满,生产后往里放,一个消费者只要队列不空,向外取,两者通过wait(和notify0进行协调, 写好了会问怎样提高效率,最后会聊一聊消息队列设计精要思想及其使用。
11.写一个死锁,觉得这个问题真的很不错, 经常说的死锁四个条件,背都能背上,那写一个看看,思想为:定义两个ArrayList,将他们都加上锁A,B,线程1,2, 1拿住了锁A,请求锁B, 2拿住了锁B请求锁A,在等待对方释放锁的过程中谁也不让出已获得的锁。


12. cpu 100%怎样定位,这题是一个应用性题目, 网上搜一下即可, 比较常见,说实话,把这题放进来有点后悔。
13. Stringa= "ab"; Stringb= "a"+ "b";a, b是相等的(各位要写代码验证-下,我看到有人写了错误答案)。常规的问法是new-一个对象赋给变量,问:这行表达式创建了几个对象,但这样的题目太常见。
14. inta= 1;是原子性操作。
15. for循环直接删除ArrayList中的特定元素是错的,不同的for循环会发生不同的错误,泛型for会抛出ConcurrentModificationException,普通的for想要删除集合中重复且连续的元素,只能删除第一个。
错误原因:打开JDK的ArrayList源码, 看下ArrayList中的remove方法(注意ArrayList中的remove有两个同名方法,只是入参不同,这里看的是入参为Object的remove方法)是怎么实现的,一般情况下程序的执行路径会走到else路径下最终调用faseRemove方法,会执行System.arraycopy方法,导致删除元素时涉及到数组元素的移动。针对普通for循环的错误写法,在遍历第一个字符串b时因为符合删除条件,所以将该元素从数组中删除,并且将后-个元素移动(也就是第二个字符串b)至当前位置,导致下一次循环遍历时后一个字符串b并没有遍历到,所以无法删除。针对这种情况可以倒序删除的方式来避免
解决方案:用Iterator。

将本问题扩展一下,下面的代码可能会出现什么问题?

16.第一-步: 线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则执行第二步。
第二步:线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里进行等待。如果工作队列满了,则执行第三步。
第三步:线程池判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
17.抽象队列同步器AQS (AbstractQueuedSychronizer) ,如果说java.util.concurrent的基础是CAS的话,那么AQS就是整个Java并发包的核心了,ReentrantLock、 CountDownLatch、Semaphore等都用到了它。AQS实际上以双向队列的形式连接所有的Entry,比方说ReentrantLock,所有等待的线程都被放在-个Entry中并连成双向队列,前面一个线程使用ReentrantLock好了,则双向队列实际上的第一个Entry开始运行。 AQS定 义了对双向队列所有的操作,而只开放了tryLock和tryRelease方法给开发者使用,开发者可以根据自己的实现重写tryLock和tryRelease方法,以实现自己的并发功能。
比较并替换CAS(Compare and Swap),假设有三个操作数:内存值V、旧的预期值A、要修改的值B,当且仅当预期值A和内存值V相同时,才会将内存值修改为B并返回true,否则什么都不做并返回false,整个比较并替换的操作是一个原子操作。 CAS- 定要volatile变 量配合,这样才能保证每次拿到的变量是主内存中最新的相应值,否则旧的预期值A对某条线程来说,永远是一个不会变的值A,只要某次CAS操作失败,下面永远都不可能成功。CAS虽然比较高效的解决了原子操作问题,但仍存在三大问题。
●循环时间长开销很大。, 只能保证-个共享变量的原子操作。
●ABA问题。
18. synchronized (this)原理:涉及两条指令: monitorenter, monitorexit; 再说同步方法,从同步方法反编译的结果来看,方法的同步并没有通过指令monitorenter和monitorexit来实现,相对于普通方法,其常量池中多了'ACC_ SYNCHRONIZED标示符。
JVM就是根据该标示符来实现方法的同步的:当方法被调用时,调用指令将会检查方法的ACC_ SYNCHRONIZED访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。
这个问题会接着追问: java对象头信息,偏向锁,轻量锁,重量级锁及其他们相互间转化。
19.理解volatile关键字的作用的前提是要理解Java内存模型,voltile关键字的作用主 要有两点:多线程主要围绕可见性和原子性两个特性而展开,使用volatile关键字修饰的变量,保证了其在多线程之间的可见性,即每次读取到volatile变量,一定是最新的数据
●代码底层执行不像我们看到的高级语言一Java程序这么简单, 它的执行是Java代码- >字节码->根据字节码执行对应的C/C + +代码- >C/C+ +代码被编译成汇编语言- > 和硬件电路交互,现实中,为了获取更好的性能JVM可能会对指令进行重排序,多线程下可能会出现- -些意想不到的问题。使用volatile则会对禁止语义重排序,当然这也一定程度上降低了代码执行效率
从实践角度而言,volatile的一 个重要作用就是和CAS结合,保证了原子性,详细的可以参见java.util.concurrent.atomic包下的类,比如AtomiclInteger。
20. AOP和I0C是Spring精华部分,AOP可以看 做是对OOP的补充,对代码进行横向的扩展,通过代理模式实现,代理模式有静态代理,动态代理,Spring利用的是动态代理,在程序运行过程中将增强代码织入原代码中。I0C是控制反转,将对象的控制权交给Spring框架,用户需要使用对象无需创建,直接使用即可。AOP和IOC最可贵的是它们的思想。
21.什么是循环依赖,怎样检测出循环依赖,Spring循环依赖有几种方式,使用基于setter属 性的循环依赖为什么不会出现问题,接下来会问: Bean的生命周期。
22.上一张图,从这张图去理解
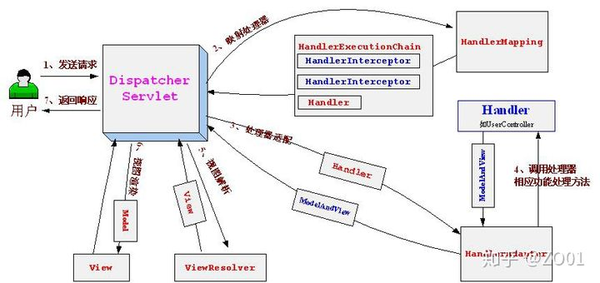
具体流程:
1) .用户发请求--> DispatcherServlet, 前端控制器收到请求后自己不进行处理, 而是委托给其他的解析器进行处理,作为统- -访问点, 进行全局的流程控制。
2) .DispatcherServlet--> HandlerMapping, HandlerMapping将会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器,多个HandlerInterceptor拦截器)。
3) .DispatcherServlet--> HandlerAdapter,HandlerAdapter将会把处理器包装为适配器,从而支持多种类型的处理器。
4) .HandlerAdapter-->处理器功能处理方法的调用,HandlerAdapter将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理,并返回- -个ModelAndView对象(包含模型数据,逻辑视图名)
5) .ModelAndView的逻辑视图名--> ViewResolver, ViewResoler将把逻 辑视图名解析为具体的View。
6) .View-->渲染, View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构
7) .返回控制权给DispatcherServlet, 由DispatcherServlet返回响应给用户。
23.先上结论:重复性较强的字段,不适合添加索引。mysq|给离散度低的字段,比如性别设置索引,再以性别作为条件进行查询反而会更慢。
一个表可能会涉及两个数据结构(文件),一个是表本身,存放表中的数据,另- -个是索引。索引是什么?它就是把一个或几个字段(组合索引)按规律排列起来,再附上该字段所在行数据的物理地址(位于表中)。比如我们有个字段是年龄,如果要选取某个年龄段的所有行,那么一般情况下可能需要进行一次全表扫描。但如果以这个年龄段建个索引,那么索引中会按年龄值根据特定数据结构建一个排列,这样在索引中就能迅速定位,不需要进行全表扫描。为什么性别不适合建索弓|呢?
因为访问索弓l需要付出额外的IO开销,从索弓|中拿到的只是地址,要想真正访问到数据还是要对表进行一次IO。假如你要从表的100万行数据中取几个数据,那么利用索引迅速定位,访问索弓|的这10开销就非常值了。但如果是从100万行数据中取50万行数据,就比如性别字段,那你相对需要访问50万次索引,再访问50万次表,加起来的开销并不会比直接对表进行一次完整打 描小。当然如果把性别字段设为表的聚集索引,那么就肯定能加快大约一半该字段的查询速度了。聚集索引指的是表本身数据按哪个字段的值来进行排序。因此,聚集索引只能有一个,而且使用聚集索引不会付出额外O开销。当然你得能舍得把聚集索弓|这么宝贵资源用到性别字段上。
可以根据业务场景需要,将性别和其它字段建立联合索引,比如时间戳,但是建立索弓|记得把时间戳字段放在性别前面。
有完整的Java初级,高级对应的学习路线和资料!专注于java开发。分享java基础、原理性知识、JavaWeb实战、spring全家桶、设计模式、分布式及面试资料、开源项目,助力开发者成长!
欢迎关注微信公众号:码邦主

作者:ZO01
链接:https://www.zhihu.com/question/60949531/answer/579002882
来源:知乎/侵删