一、问题需求:
近期需要做一个商品集合的相关性计算,需要将所有商品进行两两组合笛卡尔积,但spark自带的笛卡尔积会造成过多重复,而且增加join量
假如商品集合里面有:
aa aa
bb bb
cc cc
两两进行组合会出现九种情况
aa,aa
aa,bb
aa,cc
cc,aa
bb,aa
bb,cc
cc,aa
cc,bb
cc,cc
其实 aa,aa 还有aa,bb与bb,aa是一样的
我们其实只要其中3种:
排列组合:
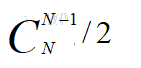
aa,bb
bb, cc
aa, cc
二、实现:增加一列自增列
//形成rdd
val rdd = sc.parallelize(Array("bb", "aa", "cc", "dd"))
//添加一列自增值
val withIndexDf: DataFrame = rdd.zipWithIndex()
.toDF("key", "index")
withIndexDf.show(false)
+---+-----+
|key|index|
+---+-----+
|bb |0 |
|aa |1 |
|cc |2 |
|dd |3 |
+---+-----+
//重命名一张表
val df2 = withIndexDf.select(col("key").as("key2"), col("index").as("index2"))
//只关联表二比表一大的
val crossRdd = withIndexDf.join(df2, df2("index2") > withIndexDf("index"), "inner")
crossRdd.show(false)
+---+-----+----+------+
|key|index|key2|index2|
+---+-----+----+------+
|bb |0 |aa |1 |
|bb |0 |cc |2 |
|bb |0 |dd |3 |
|aa |1 |cc |2 |
|aa |1 |dd |3 |
|cc |2 |dd |3 |
+---+-----+----+------+
得出 key与key2两列就是不重复的数据