异常出现:spark读取hive表时,spark.read.table(hive.test)
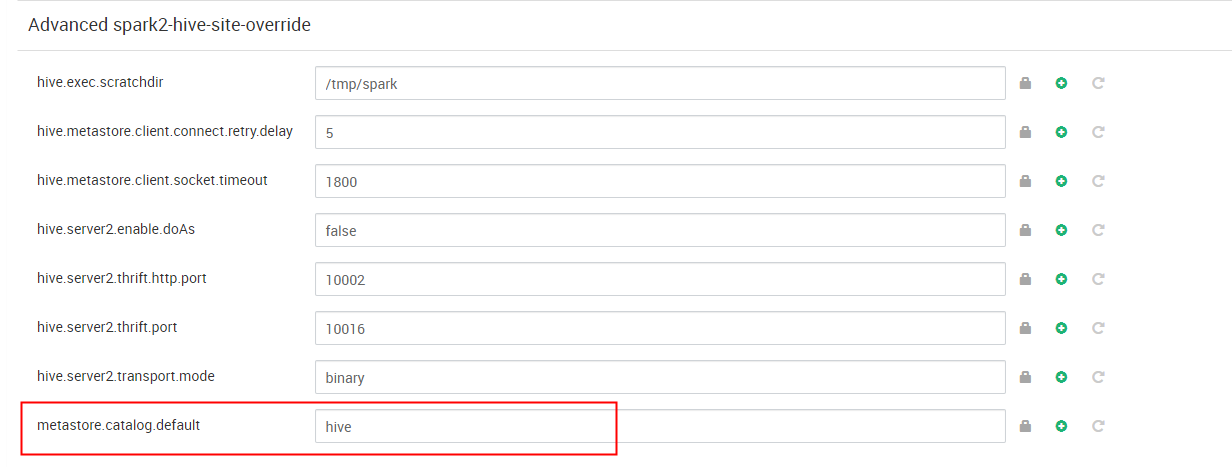
hdp版本的spark默认的catalog是spark,配置项 metastore.catalog.default 默认值是spark,即读取SparkSQL自己的metastore_db。所以才会出现上述相互是查看不到的对方的创建的数据的问题。
org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;;
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:47)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:64)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:42)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:288)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile.apply(rules.scala:42)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile.apply(rules.scala:37)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:124)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:118)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:103)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:628)
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:624)
at org.apache.spark.sql.DataFrameReader.table(DataFrameReader.scala:654)
... 49 elided
Caused by: org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:56)
... 74 more