QQ、微信斗图总是斗不过,索性直接来爬斗图网,我有整个网站的图,不服来斗。
废话不多说,选取的网站为斗图啦,我们先简单来看一下网站的结构
网页信息

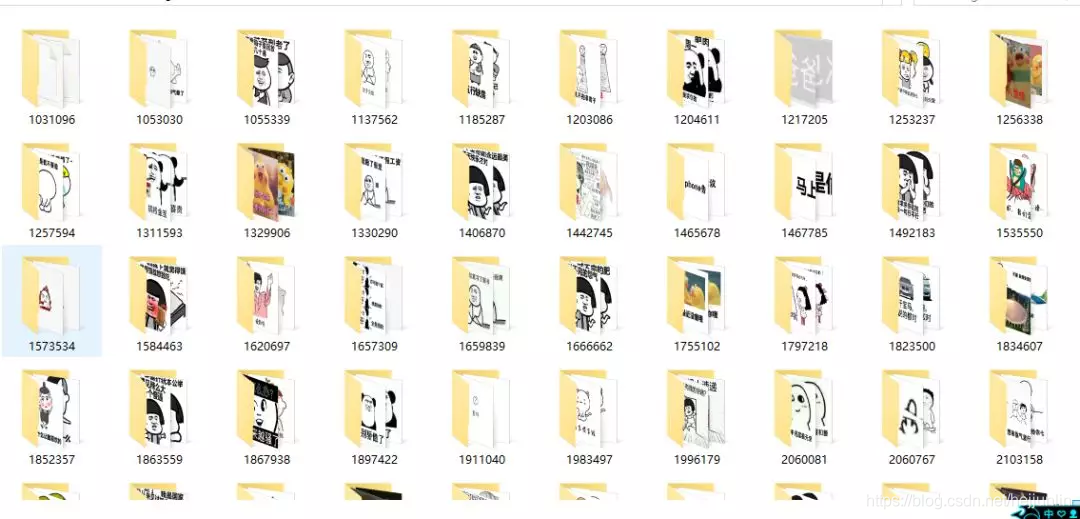
从上面这张图我们可以看出,一页有多套图,这个时候我们就要想怎么把每一套图分开存放(后边具体解释)
通过分析,所有信息在页面中都可以拿到,我们就不考虑异步加载,那么要考虑的就是分页问题了,通过点击不同的页面,很容易看清楚分页规则

很容易明白分页URL的构造,图片链接都在源码中,就不做具体说明了明白了这个之后就可以去写代码抓图片了
存图片的思路
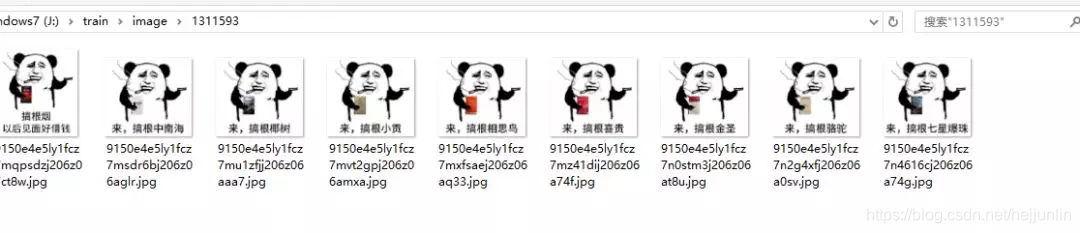
因为要把每一套图存入一个文件夹中(os模块),文件夹的命名我就以每一套图的URL的最后的几位数字命名,然后文件从文件路径分隔出最后一个字段命名,具体看下边的截图。

这些搞明白之后,接下来就是代码了(可以参考我的解析思路,只获取了30页作为测试)全部源码
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import os
class doutuSpider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}
def get_url(self,url):
data = requests.get(url, headers=self.headers)
soup = BeautifulSoup(data.content,'lxml')
totals = soup.findAll("a", {"class": "list-group-item"})
for one in totals:
sub_url = one.get('href')
global path
path = 'J:\train\image'+'\'+sub_url.split('/')[-1]
os.mkdir(path)
try:
self.get_img_url(sub_url)
except:
pass
def get_img_url(self,url):
data = requests.get(url,headers = self.headers)
soup = BeautifulSoup(data.content, 'lxml')
totals = soup.find_all('div',{'class':'artile_des'})
for one in totals:
img = one.find('img')
try:
sub_url = img.get('src')
except:
pass
finally:
urls = 'http:' + sub_url
try:
self.get_img(urls)
except:
pass
def get_img(self,url):
filename = url.split('/')[-1]
global path
img_path = path+'\'+filename
img = requests.get(url,headers=self.headers)
try:
with open(img_path,'wb') as f:
f.write(img.content)
except:
pass
def create(self):
for count in range(1, 31):
url = 'https://www.doutula.com/article/list/?page={}'.format(count)
print '开始下载第{}页'.format(count)
self.get_url(url)
if __name__ == '__main__':
doutu = doutuSpider()
doutu.create()
结果

总结
总的来说,这个网站结构相对来说不是很复杂,大家可以参考一下,爬一些有趣的
原创作者:loading_miracle,原文链接:
https://www.jianshu.com/p/88098728aafd

欢迎关注我的微信公众号「码农突围」,分享Python、Java、大数据、机器学习、人工智能等技术,关注码农技术提升•职场突围•思维跃迁,20万+码农成长充电第一站,陪有梦想的你一起成长。