FCN论文地址:https://arxiv.org/abs/1411.4038
图像语义分割(Semantic Segmentation)是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。

本文提出全卷积网络(Fully Convolutional Networks, FCN)用于图像语义分割。FCN主要思想是将一般的分类网络(如VGG,ResNet等)最后几层的全连接层替换成卷积层。FCN的好处是可以接受任意尺寸的输入图像。
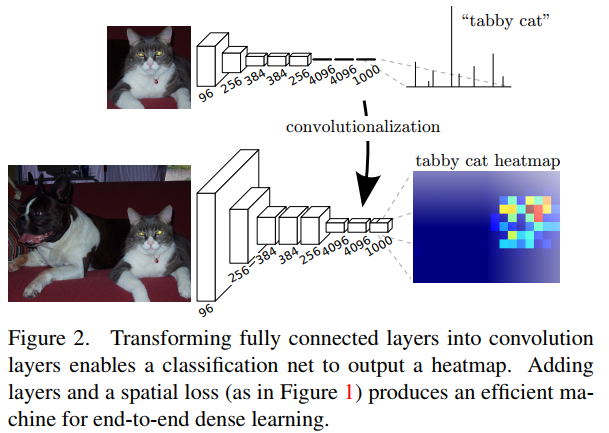
下面主要介绍一下FCN在语义分割上具体做法。
整个FCN网络基本原理如图5(只是原理示意图):
-
image经过多个conv和+一个max pooling变为pool1 feature,宽高变为1/2
-
pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4
-
pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8
-
......
-
直到pool5 feature,宽高变为1/32。
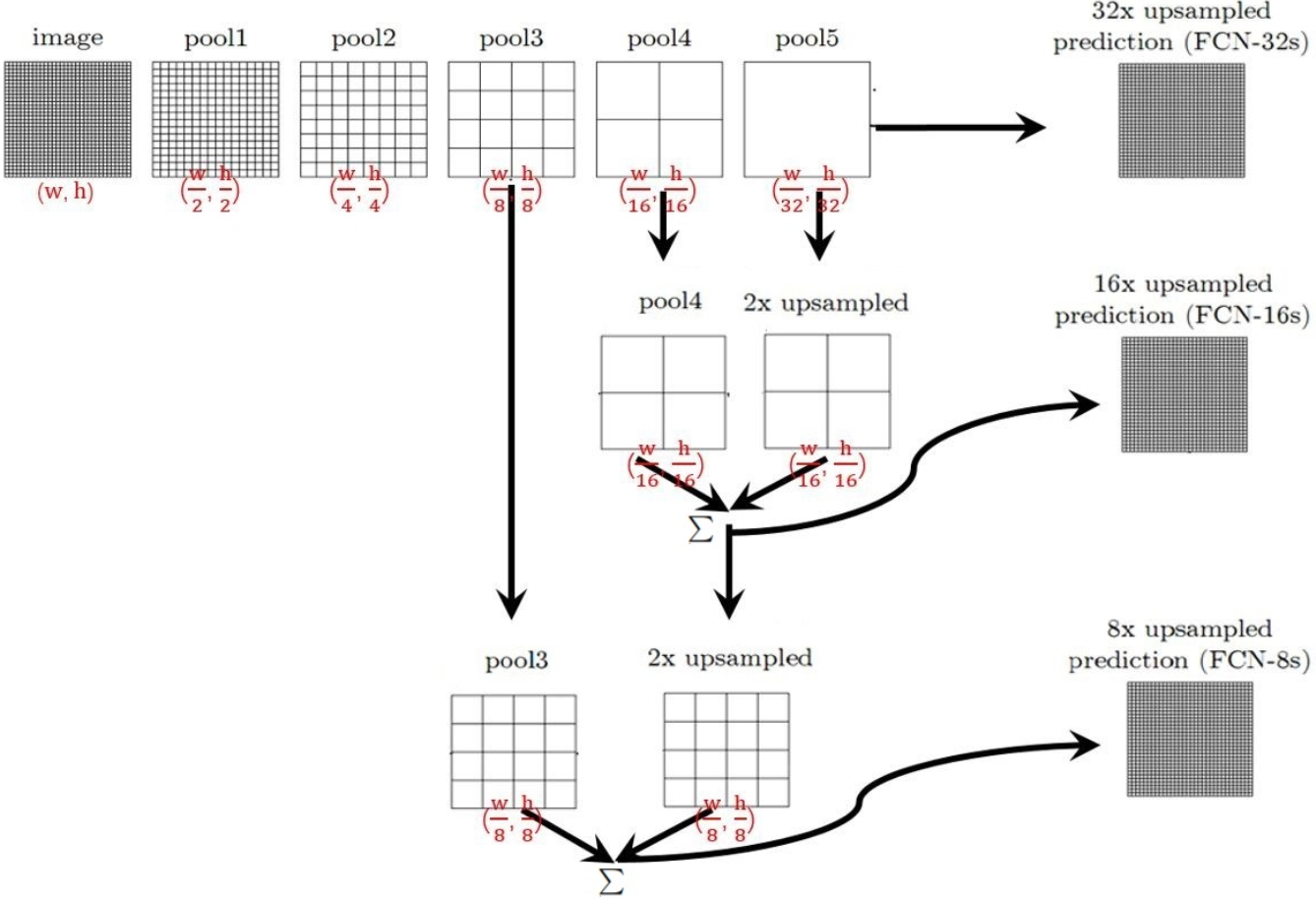
那么:
-
对于FCN-32s,直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
-
对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加(element-wise add),然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
-
对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
利用Pytorch实现FCN-8s的网络结构代码如下:
import torch import torch.nn as nn import torch.nn.init as init import torch.nn.functional as F from torch.utils import model_zoo from torchvision import models class FCN8(nn.Module): def __init__(self, num_classes): super().__init__() feats = list(models.vgg16(pretrained=True).features.children()) self.feats = nn.Sequential(*feats[0:9]) self.feat3 = nn.Sequential(*feats[10:16]) self.feat4 = nn.Sequential(*feats[17:23]) self.feat5 = nn.Sequential(*feats[24:30]) for m in self.modules(): if isinstance(m, nn.Conv2d): m.requires_grad = False self.fconn = nn.Sequential( nn.Conv2d(512, 4096, 7), nn.ReLU(inplace=True), nn.Dropout(), nn.Conv2d(4096, 4096, 1), nn.ReLU(inplace=True), nn.Dropout(), ) self.score_feat3 = nn.Conv2d(256, num_classes, 1) self.score_feat4 = nn.Conv2d(512, num_classes, 1) self.score_fconn = nn.Conv2d(4096, num_classes, 1) def forward(self, x): feats = self.feats(x) feat3 = self.feat3(feats) feat4 = self.feat4(feat3) feat5 = self.feat5(feat4) fconn = self.fconn(feat5) score_feat3 = self.score_feat3(feat3) score_feat4 = self.score_feat4(feat4) score_fconn = self.score_fconn(fconn) score = F.upsample_bilinear(score_fconn, score_feat4.size()[2:]) score += score_feat4 score = F.upsample_bilinear(score, score_feat3.size()[2:]) score += score_feat3 return F.upsample_bilinear(score, x.size()[2:])
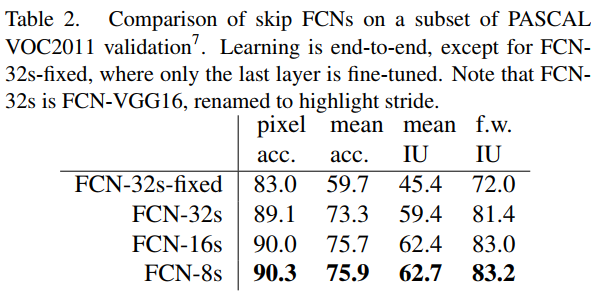
上述3种网络的效果如下, 明显可以看出效果:FCN-32s < FCN-16s < FCN-8s,即使用多层feature融合有利于提高分割准确性。

另外几点说明:
-
最终的输出通道数为21,为PASCAL数据集20类+1类背景。
-
网络最终的输出大小为 输入图像width * 输入图像height * 21,损失函数是对每一个像素点求softmax loss,然后求和。
-
上采样使用反卷积(deconvolution)的方式,使用双线性插值初始化。
-
原网络中会设置第一层卷积层的pad=100,后面在特征融合时引入了crop层。
语义分割的评价指标如下:
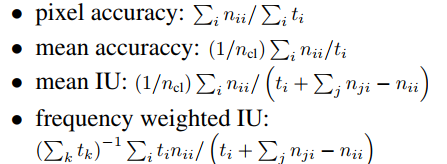
其中, nij表示将本属于第i类的像素预测为属于第j类的像素数量;ncl表示像素的类别总数;ti表示属于第i类的像素总数,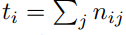
参考:
图像语义分割入门+FCN/U-Net网络解析 https://zhuanlan.zhihu.com/p/31428783