hadoop由3个核心组件构成:
(1)HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode/SecondaryNameNode。
(2)YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(3)MapReduce:它其实是一个应用程序开发包。
HDFS(分布式文件系统):
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息
namenode如何保存元数据:

fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
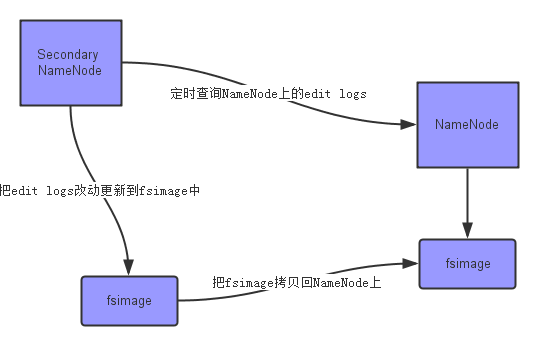
namenode正常运行时的元数据的改动会写进edit logs文件中,当服务重启时,namenode从fsimage读取并与edit logs合并,变成最新的fsimage并正常运行,之后再生出新的edit logs继续把改动写进。
Secondary NameNode:合并NameNode的edit logs到fsimage文件。
SNN作用:只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照,由于edit logs时间长后会有很大,因此 NameNode重启的时间往往很久。因此Secondary NameNode的出现能及时把NameNode的edit logs到fsimage文件,获取最新的fsimage,因此,NameNode重启是不在需要大量合并edit logs,减少了重启时间。
合并流程如图:
datanode:用来存储数据。
yarn(集群资源管理器):
Resource Manager:资源调度器,处理客户端请求。
Node Manager:负责自己本身节点资源管理和使用,定时向RM汇报本节点的资源使用情况,接收并处理来自RM的各种命令:启动Container
Application Manager:应用程序管理器,每运行一个作业,会生成一个AM,由AM进行管理,并向RM申请资源生成一个或多个container运行任务,并监控container的健康状况。
container:资源容器,作业在资源容器里面运行,namespace+cgroup
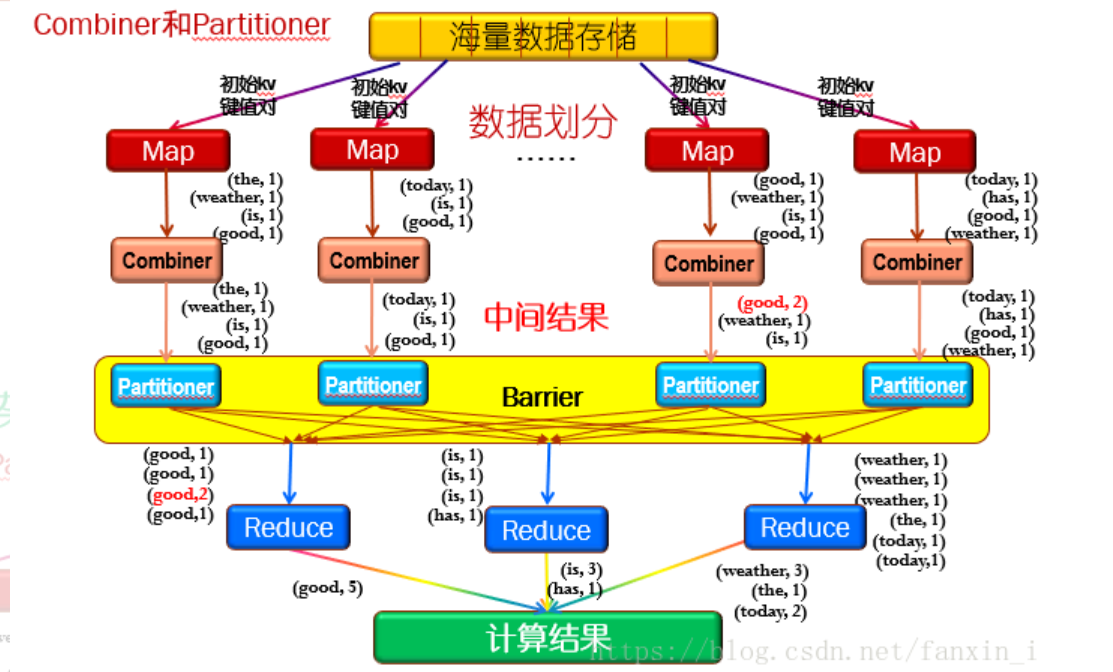
MapReduce:
mapper:把每个单词拆分成键值对,比如word:1,word:1,this:1
combiner:把mapper拆分的单词,相同的word键值相加,比如word:5,this:3
partitioner:把相同的单词发送给同一个reduce
shuffle && sort: 般将排序以及Map的输出传输到Reduce的过程称为混洗
reduce:把发过来的相同的单词相加在一起,比如mapper1发送word:5,mapper2发送word:4,在reduce上进行合并成word:9
原理附图如下: