SqueezeNet
2017年的文章,和后面的几篇文章一对比思路显得比较老套:大量的1*1的卷积和少量的3*3卷积搭配(小卷积核),同时尽量的减少通道数目,达到控制参数量的目的。SqueezeNet的核心在于Fire module,Fire module 由两层构成,分别是squeeze层+expand层,如下图所示,squeeze层是一个1*1卷积核的卷积层,expand层是1*1 和3*3卷积核的卷积层,expand层中,把1*1 和3*3 得到的feature map 进行concat。整个网络就是将多个Fire module 堆叠而成。其论文中对比实验目标是AlexNet,可见这个工作的确是老了……
具体操作情况如下图所示(略有误,Expand应该有一通路是3*3核心的):
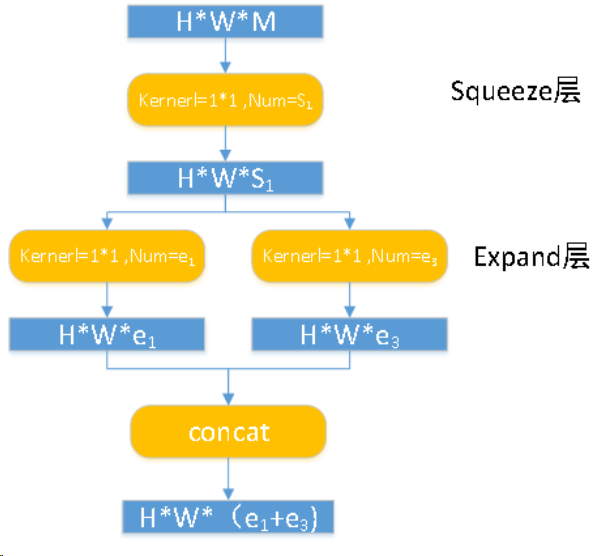
Fire module 输入的 feature map 为 H*W*M 的,输出的 feature map 为 H*M*(e1+e3),可以看到 feature map 的分辨率是不变的,变的仅是维数,也就是通道数,这一点和 VGG 的思想一致。
Xception
『高性能模型』Roofline Model与深度学习模型的性能分析
Xception 基于Inception_v3,X表示Extreme,表示Xception 做了一个加强的假设:卷积可以解耦为空间映射和通道映射。
下图表示标准的v3子模块:

下图表示简化结果:
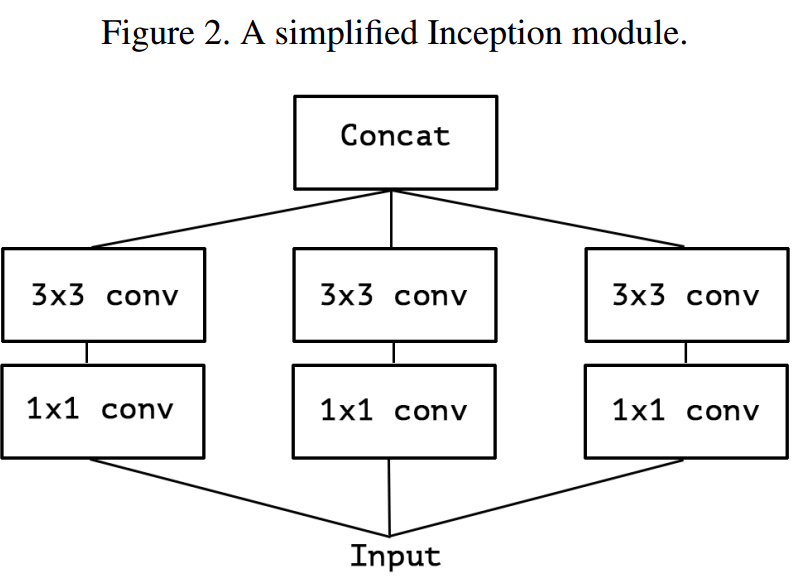
假设出一个简化版 inception module 之后,再进一步3 个 1*1 卷积核统一起来,变成一个 1*1 的,后面的3个3*3的分别负责一部分通道
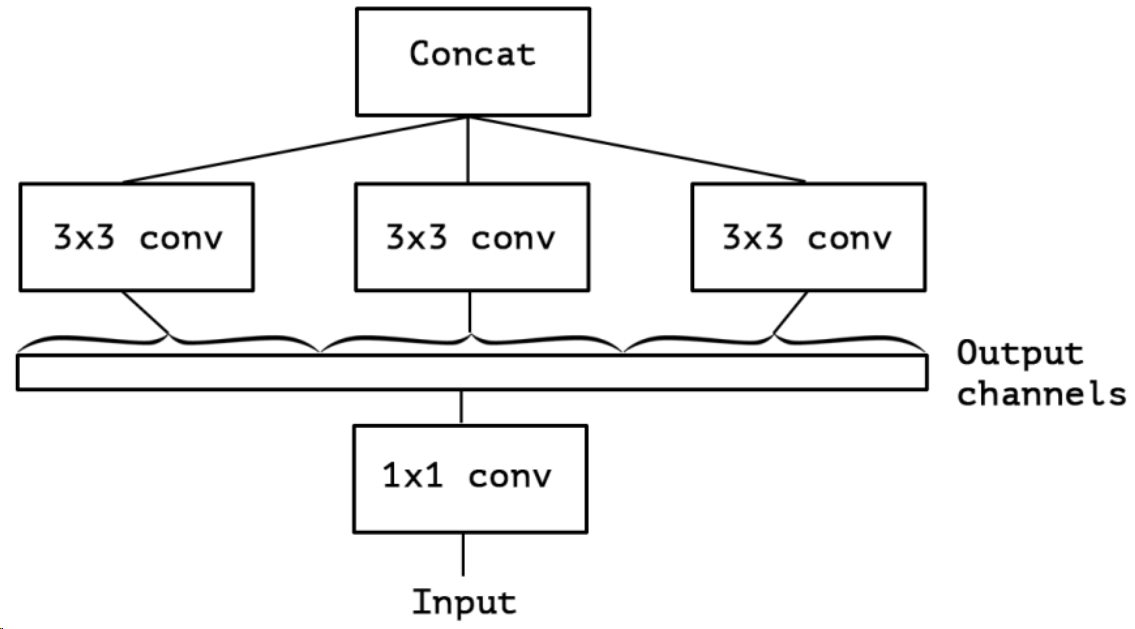
和标准的深度可分离卷积略有不同的是:
原版Depthwise Conv,先逐通道卷积,再1*1卷积; 而Xception是反过来,先1*1卷积,再逐通道卷积
原版Depthwise Conv的两个卷积之间是不带激活函数的,而Xception在经过1*1卷积之后会带上一个Relu的非线性激活函数
MobileNet_v1
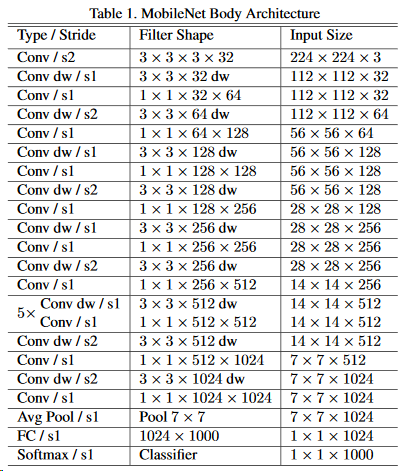
2017年的成果,思想来源于同属Google的Xception,引入了深度可分离卷积降低计算量,本网络比较传统,就是一层dw一层pw的叠加(3x3 Depthwise Conv+BN+ReLU 和 1x1 Pointwise Conv+BN+ReLU),结构如下:
ShuffleNet_v1
2017年的文章,和MobileNet一样使用了pw+dw,但是这里把dw视为极限的群卷积:组数等度输入特征数目,此时的计算瓶颈在于pw,作者提出:同样使用群卷积替代pw,为了解决特征间通信,作者提出channels shuffle的思路,即在群卷积版pw前将特征重新排列组合。另外ShufflwNet也是对ResNet进行修改的产物。
MobileNet_v2
2018年的文章,针对架构直白的MobileNet_v1,这一版本着重讨论了relu在feature 数目少时的数据坍缩,并提出使用ResNet来解决的方案,作者实际对ResBlock的改造也不复杂:
- 将原来的:pw->conv->pw转化为pw->dw->pw,这个很好理解,单纯的降低计算量
- 将上一步中的沙漏型特征层数变化改为梭子型,保证第一个pw后的relu6和dw后的relu6的数据坍缩最小(C-pw->6C-dw->6C-pw->C)
- 将最后一个pw后的relu取消,因为此pw输出feature 数目较小,容易引起坍缩

ShuffleNet_v2
2018年的文章,作者提出了一个新的衡量效率的量:内存访问消耗时间(memory access cost),并根据这个量提出了4点发现,修改v1版本网络,由于链接博客已经给了很详细的说明,这里不再赘述。