RNN实现文本标注:
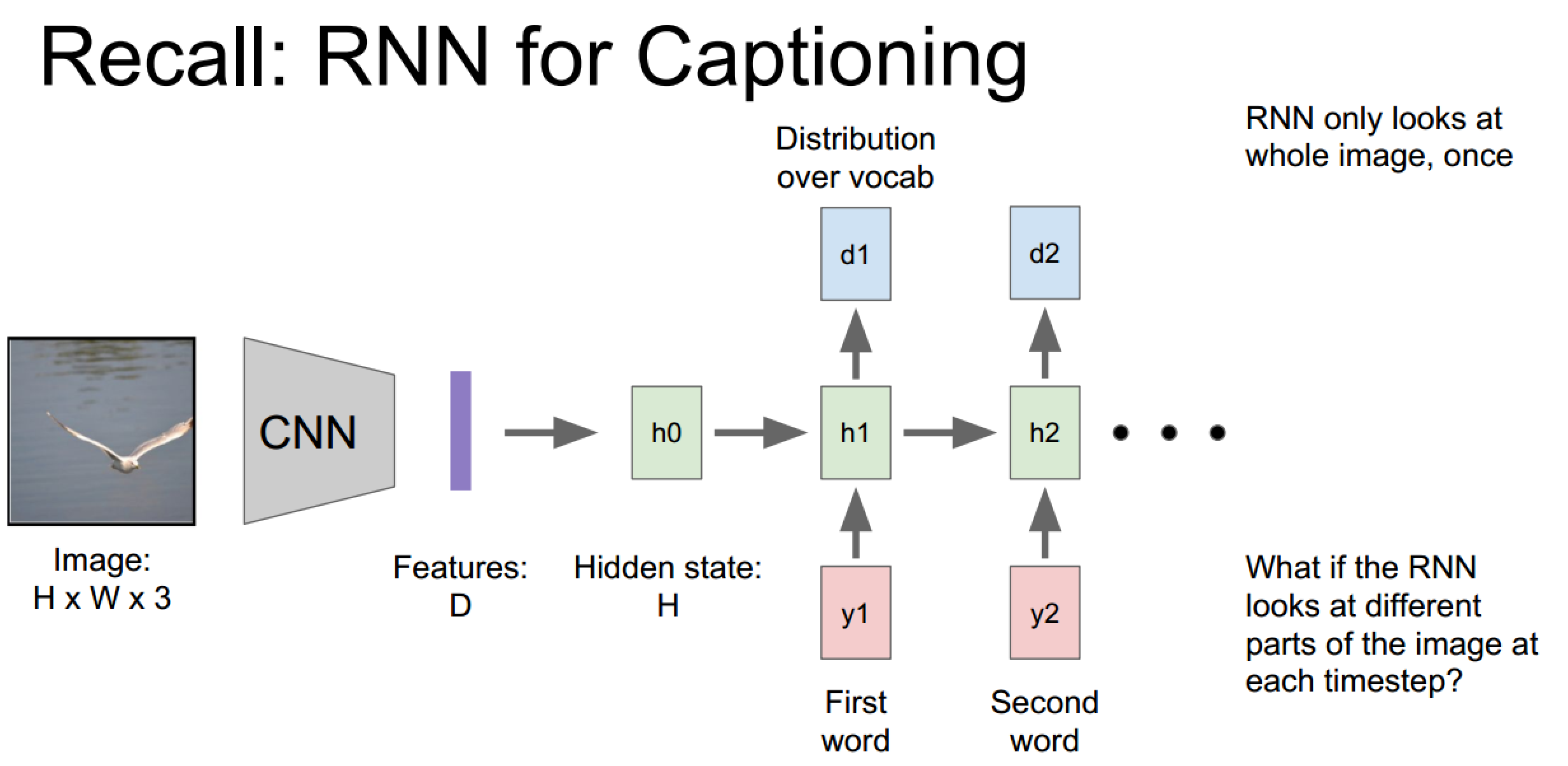
弊端是图像信息只在初始化时有用到
Soft Attention模型:
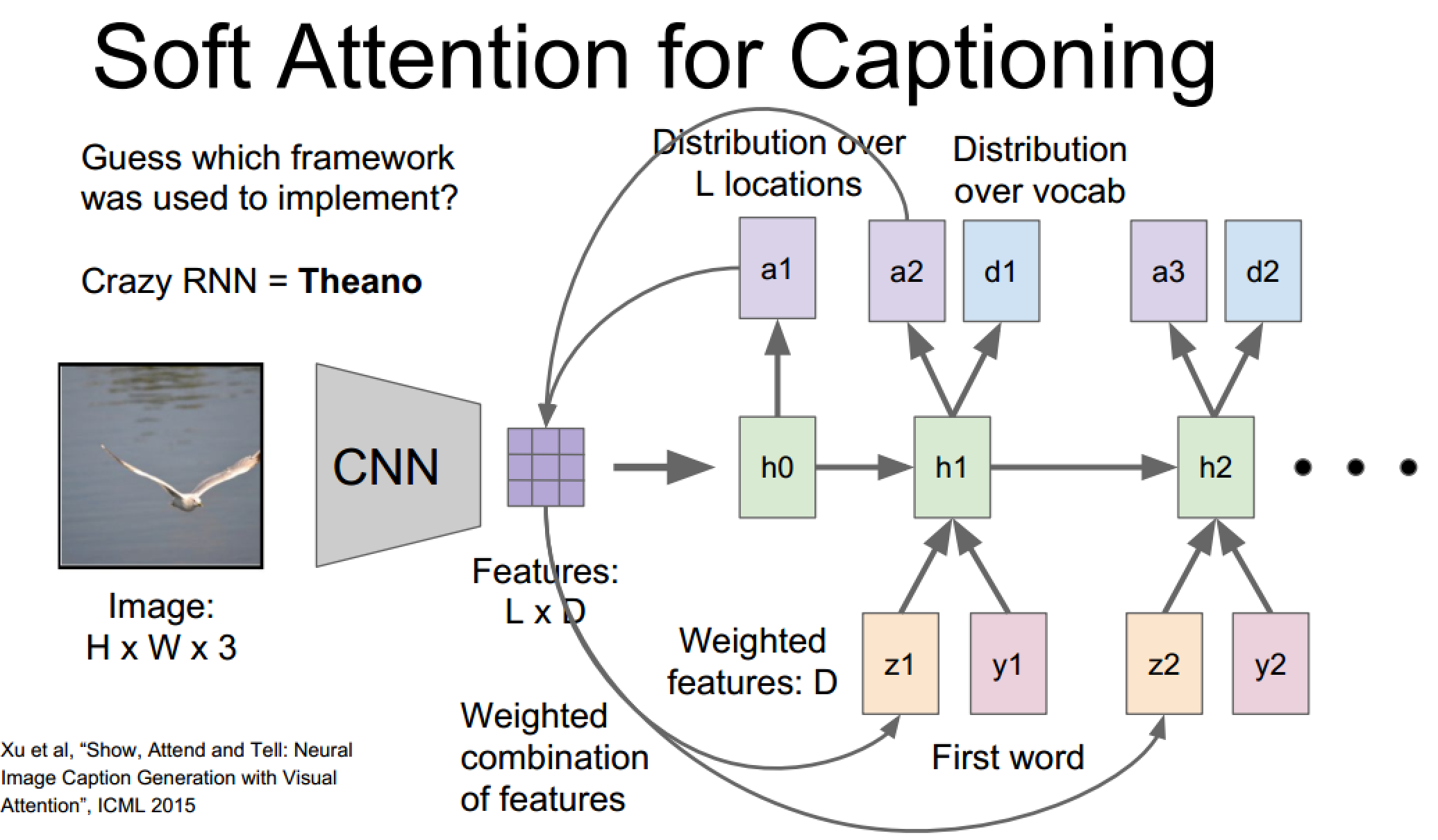
每一层具有三个输入:隐藏状态 + 注意力特征向量 + 词向量
每一层具有两个输出:新的位置分布(指示下一次‘观测’位置) + 词向量概率分布

上图介绍了两种计算注意力特征向量的方式,CNN特征和RNN产生位置分布的结合方式,D维指的应该是feature深度
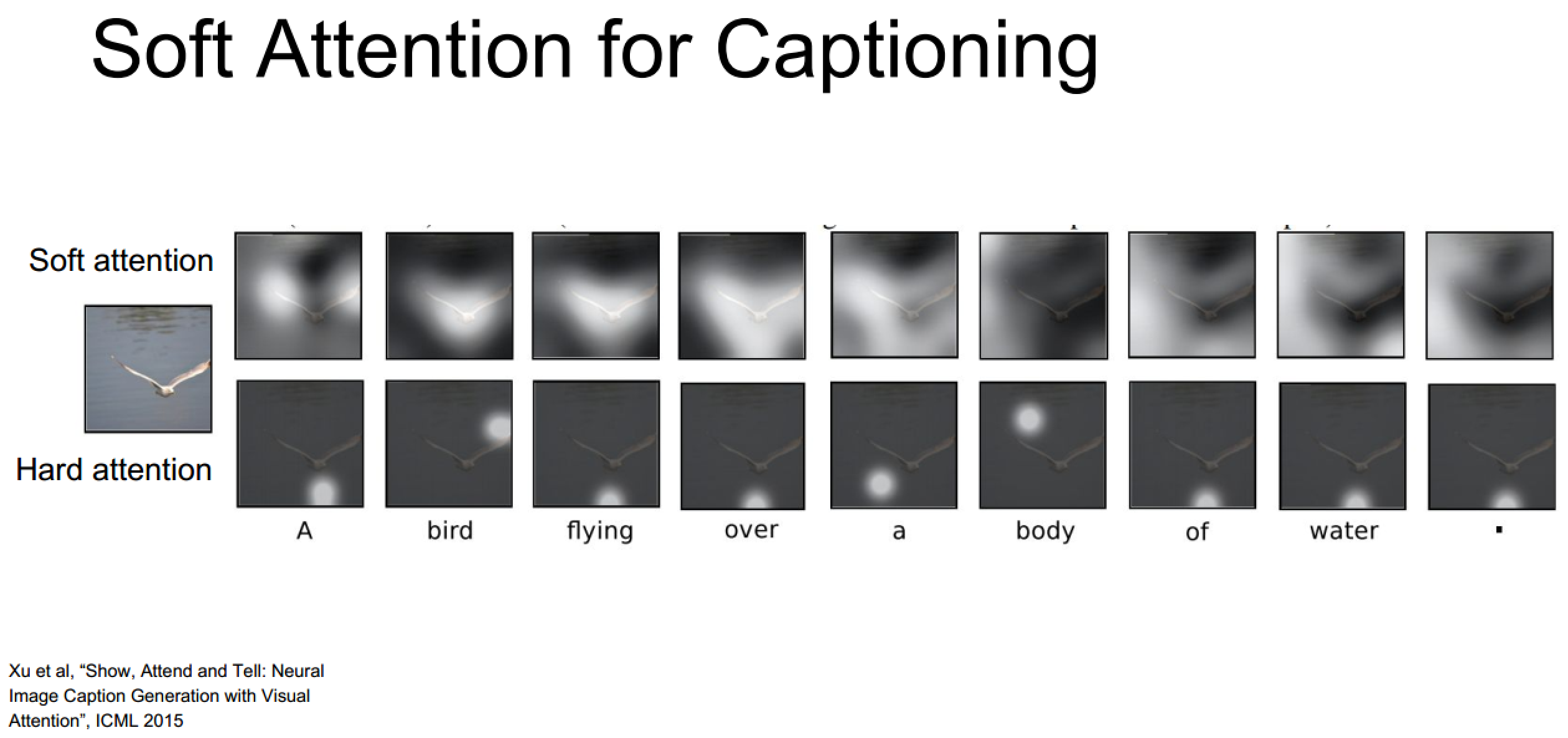
这里展示了两种注意力向量生成方式的异同,可以看到Soft模式更为发散且更为直观,当然比较厉害的是这是无监督学习出来的结果(神经网络么)

其他的Soft模式展示

但是Sotf模式不是随意关注的,它的关注区域大小也是收到感受野大小影响的(废话... ...)
空间转化器:弥补Soft模式关注区受限制的问题
关注位置裁剪可学习化:
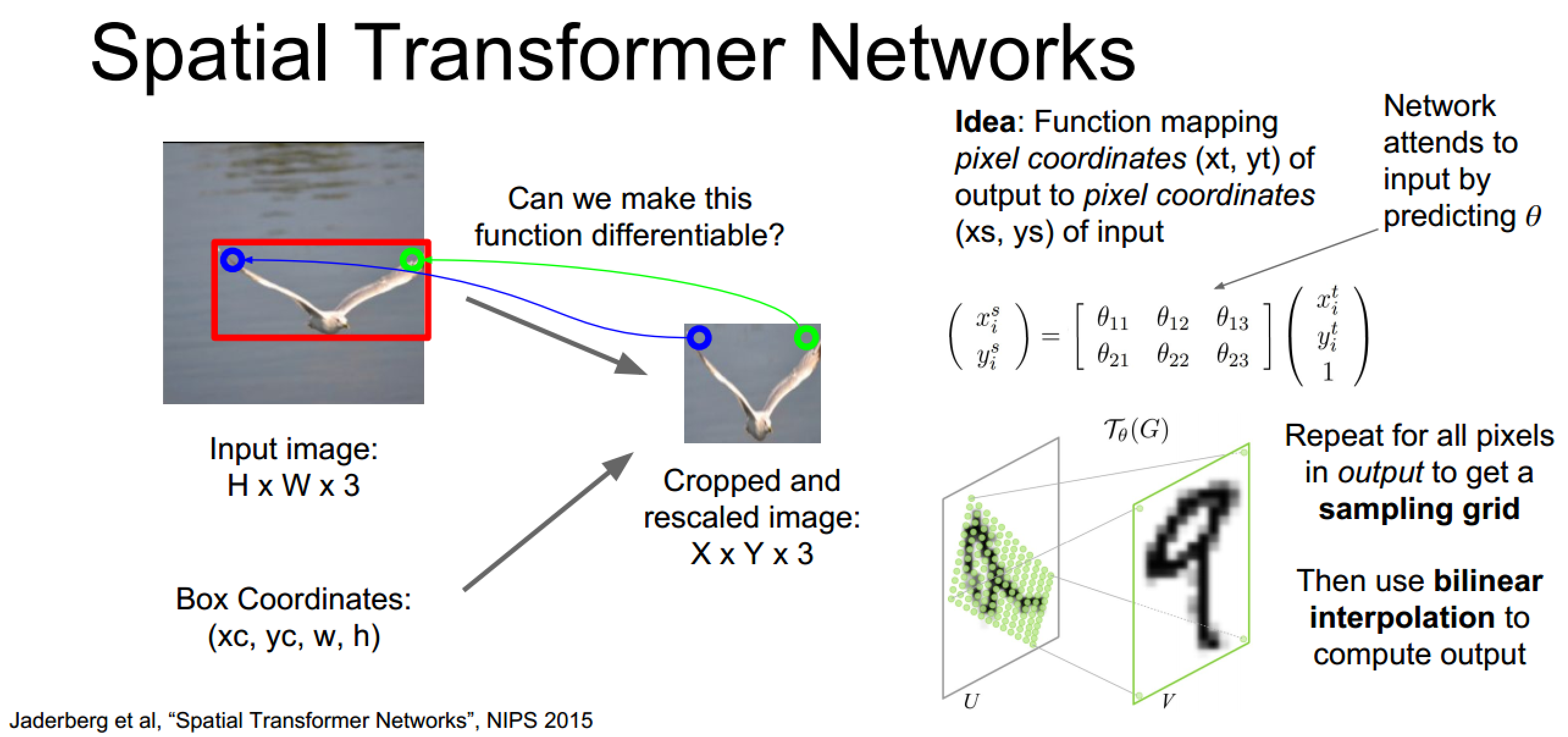
裁剪操作是不可微的,但是可以通过参数使得这一过程连续,即建立坐标映射,这样就可以将关注位置到输入图像这一过程可学习化,整合入网络

- Sotf attention
- 容易实现,且工作的不错
- 由于关注区域是受限制的,所以引入空间转换器
- Hard attention(介绍不多)
- 不容易实现
- 没有梯度
- 需要强化学习