一、基础知识
1、C++编译流程
以Unix系统编译中间文件为说明:
.cpp—(编译预处理)—>.ii—(编译)—>.s—(汇编)—>.o—(ld,连接)—>.out
2、#include
作用于编译预处理阶段,将被include文件抄送在include所在位置,并会在相应位置写出调用栈,生成中间文件.ii,该中间文件可读
include文件加引号表示先从当前目录寻找索引,加尖括号表示从编译器指定根目录索引,Unix默认为"~//usr/include"目录
3、定义、声明、头文件
.h头文件中只应存放三种代码:
函数声明:没有大括号,形如void fun()
变量声明:extern 变量名
class、结构体定义
extern表示声明一个全局变量
声明只是提示编译器,存在这个东西,并没有定义出实体,不定义直接调用会报错。
4、标准头文件结构
#ifndef HEADER_FLAG
#define HEADER_FLAG
/*头文件*/
#endif
这是为了防止多次include同一个头文件时,每次都抄送到预编译文件中,造成文件过大、循环导入或者结构体定义重复以致报错(声明重复问题不大)。
5、默认参数
在声明中写默认参数,不在定义中给默认参数。
6、调用函数过程
本地变量进入堆栈(未必初始化)
函数参数进入堆栈
返回地址计入堆栈
返回值进入寄存器(运行函数)
pop掉参数
返回值进入堆栈(返回地址,所以要pop掉参数,堆栈先进后出)
7、内联函数
在编译阶段优化,省略上一小结中复杂的堆栈操作,效果如下,

汇编(伪)优化如下,

注意,inline 函数名实际是一个声明,而非定义所以不需要额外声明。实际上以空间换时间(编译会将函数插入调用位置),编译器如果发现函数递归或者过于巨大,可能会拒绝inline操作,函数较小可能被自动inline,建议就是小函数inline(2-3行),超过20行的就不要inline了。
相比于宏,inline可以做类型检查,给出debug提示,下图中C++会提示double的f(a)和%d不匹配,C会直接给出一个奇怪的值,

8、const
初始化之后不可修改,值得注意的是下图这种,指针和const,到底是地址(指针)还是地址中的内容(对象)是const

重点在于const和*的位置顺序,下述代码中2、3两句等价,

且const变量不能传给其他非const的指针(因为这样有可能造成修改),

函数和const
函数虚参加const表示函数内部不可修改该变量,对输入无要求
return const 对接收函数返回的类型无要求
class和const
const 对象,此时我们不能保证class方法是否修改成员变量,又不能限制函数不能使用(class就没有意义了)
const 对象 or 成员变量是const,要求成员变量必须有初始值,因为事后无法赋值
main文件(编译时可以感知类声明文件),类声明文件,类定义文件:声明、定义(两个位置都需要添加)函数时后面添加const关键字如,int fun() const。
下图运行结果为"f() const",

实际构成了重载,
void f(A* this)
void f(const A* this)
9、字符串
char *s = "Hello World"; // 将代码段的字符串地址直接付给指针,所以后面尝试修改会报错(代码段不可修改),
// 应该在开头改写为const char *s
char s[] = "Hello World"; // 数组被写入堆栈,将代码段的字符串拷贝到堆栈
10、引用
char& r = c; // 引用可以做左值
相当于给c取了一个别名,此时c、r绑定到同一实体。
int x;int y;
int& a = x;
int& b = y;
a = b; // 等价x=y
注意,引用无法取地址,即 int&* r 的写法是错误的,不过相对的,int*& p 是没问题的,指针可以被引用。
class的成员变量是引用时
此时只能使用initializer list的方式初始化引用对应的变量,如果在{}中使用m_y=a则表示将a复制给m_y对应的变量。

函数返回引用时
return一个全局变量,


这个引用表示变量,不表示值,所以最后一句表示赋值。
11、中间结果
相当于Python中的“_”,i*3这样的结果会作为const int类型临时保存。
二、class入门
1、变量
Field,成员变量,作用域为class的对象,类的函数中可以直接使用;class本身不能拥有变量,理解为声明一个变量(函数和变量不同,函数属于class而不是对象);
parameters,函数参数;
local variables,本地变量,作用域为本函数;
后两者完全相同,本地存储,出来作用域则不存在该变量。
关键字 this:一个指针,为当前对象的指针(指该次调用成员函数的对象的指针),
经由指针this区分调用成员函数的不同实例,其原理如下:使用'实例对象.成员函数'来调用等价于直接调用该函数并将对象指针作为首个参数输入,即:成员函数(this),原理和python一致,成员函数实际上有一个默认存在的参数输入,接收实例指针

2、构造和析构
在C++中,class实例化时成员变量不会初始化,仅仅寻找到一块足够大的地址(java会清空地址内数据)。VS会在debug时为未初始化空间填充0xcd,用于排查(0xcd0xcd在国标码中为‘烫’)。
constructor:构造函数,初始化对象时自动执行(相当于python中的__init__)
函数名和class名相同
没有返回类型
destructor:析构函数,退出对象所在scope时自动执行
函数名为'~'加构造函数名
没有返回类型
不可以有参数
有关‘{}’,表示scope,如下代码中,进入‘{’后会执行Tree的构造函数,退出‘}’前,本scope内资源回收,会自动执行析构函数
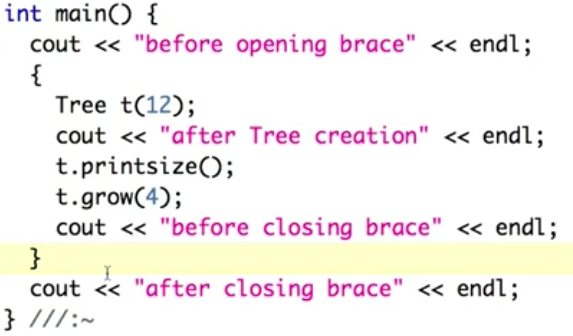
数组、结构体、使用构建函数的class初始化方式对比:

Y经由构建函数Y()间接将f、i赋值,顺便一提,数组b后面未指定元素会被初始化为0
default constructor:无参数构建函数,见下右的第二行会报错,因为构建y2有两个元素,而第二个元素会调用default constructor,但实际上constructor需要参数,所以会报错:
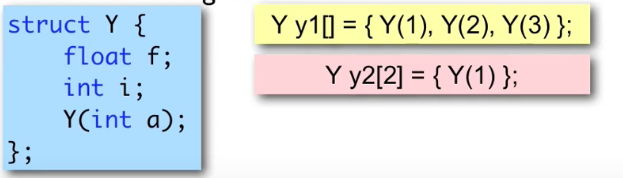 :
:
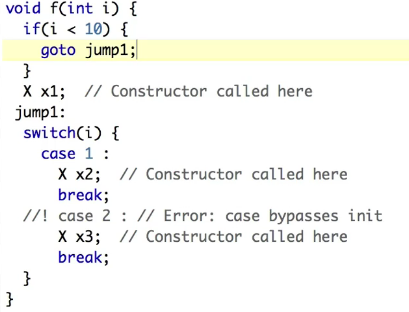
3、scope和存储空间
编译器在‘{}’开始的位置会分配好空间,而在运行到相关定义时才会真正的运行构造函数。
如下图,某些情况下编译会出错,因为一旦goto成功,则x1不会被构建,相应的退出‘{}’时,析构函数执行会失败。
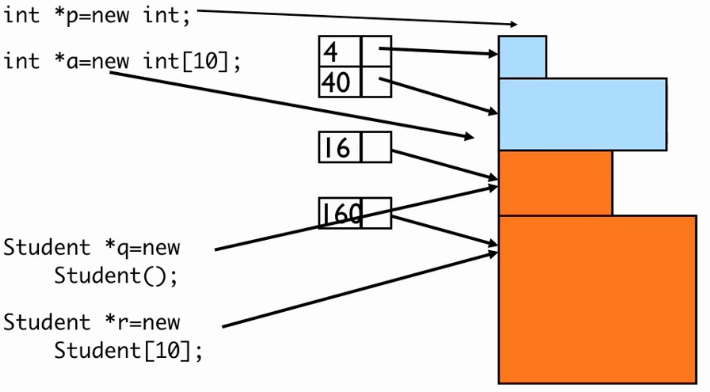
4、动态分配空间
new:制造对象,类似malloc;分配空间、调用构造函数(对于class),返回地址
使用一张表,记录下每次申请的内存大小和对应的地址:
delete:收回空间,类似free;析构对象(对于class)、回收空间;它有两种用法,如下:
delete p :普通用法
delete[] p :一般来说new p[]时,需要使用这个,会将所有对象的析构函数分别调用,否则回收内存正常,但只调用指针直接指向的对象的析构
5、访问控制
public:任何人可以访问
private:成员函数可以访问 ,注意对class来讲,同一个class不同对象可以互相访问私有变量,如下代码,p[0]是可以访问b的私有变量的

friends:声名一个函数/class等,使之可以访问自己(本class的任何实例)的私有变量
下面代码涉及两个知识点:1、friends声明在class内部;2、结构体可以前向声明(开头的X),用于在结构体Y定义中占位。
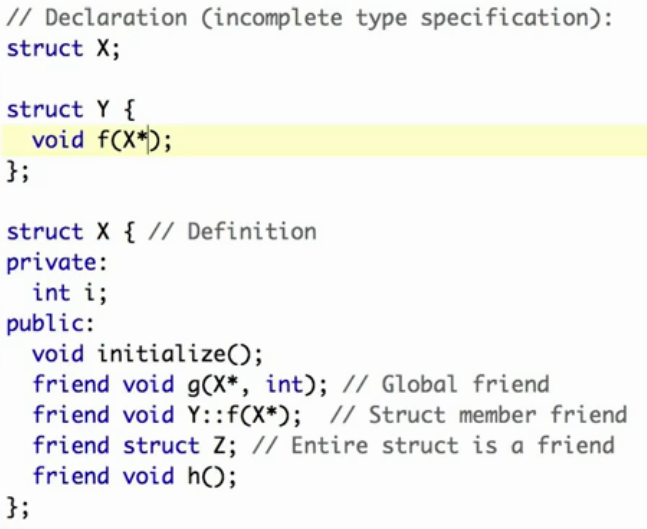

protected:自己及子类可以访问
6、struct vs class
未指定访问控制属性的变量、函数,class默认为private,struct默认public
7、初始化list

初始化后才执行构造函数(大括号中语句)
在大括号中赋值的话会先默认初始化变量,然后赋值;初始化list的方式直接用目标值初始化变量
8、成员函数和inline
在class内部给出了body的成员函数,视为内联函数。
三、父类子类
1、组合和继承
组合:已有类作为新的类的成员
继承:改造类,class B: public A {},意为B类为A类子类
父类的private,在子类中存在,但是不能直接访问(需要使用父类的public方法),需要使用protected声明。
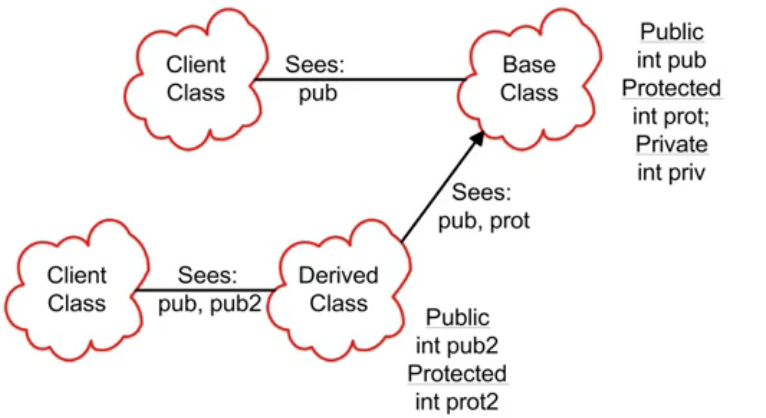
另一点值得注意的是,由于构造函数不可以直接调用, 调用父类的构造函数方式需要使用初始化list方法,而且必须最先构造父类(如果父类构造函数有参数),构造先父后子,析构先子后父:
2、覆盖(override)、重载(overload)、隐藏
overload
在同一作用域中,函数名相同,参数列表不同,返回值可同可不同的函数,编译器会根据传入参数决定调用哪个函数,注意仅返回值不同不能构成overload关系。
override
又叫覆盖,是指不在同一个作用域中(分别在父类和子类中),函数名,参数个数,参数类型,返回值类型都相同,并且父类函数必须有virtual关键字的函数,就构成了重写(协变除外)。协变:协变也是一种重写,只是父类和子类中的函数的返回值不同,父类的函数返回父类的指针或者引用,子类函数返回子类的指针或者引用。
virtual:子类的同名同参函数之间有联系(继承树中某一个函数是virtual的,子类的该方法都是virtual的)。
重定义
又叫隐藏,是指在不同的作用域中(分别在父类和子类中),函数名相同,不能构成重写的都是重定义(重定义的不光是函数,还可以是成员变量),隐藏和覆盖不同,被隐藏的父类成员可以通过子类.父类::成员的方式调用。
3、向上造型upcasting
子类对象可以被传给父类对象指针,如下图所示,
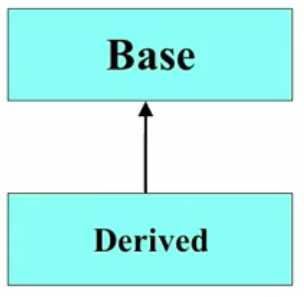
这是由于C++的class类似于C的结构体,实际上是一个指针指向一块有特定内容排列顺序的内存,子类只会在父类的内存规划上向后扩充,不会更改父类已经规划好的部分。如果有子类方法隐藏了父类方法,向上造型后会隐藏失效,此时的对象指针仅能识别父类原有的模块。
类似地,也有向下造型,不过可能会出错。

Employee是Manager的父类
4、多态
本小节摘抄自文章:C++ 多态的实现及原理
想要理解多态,需要区分函数和虚函数的区别(内存上的位置差异),并要理解向上造型的概念,了解了前面两点,就了解了动态绑定、静态绑定的区别,对于多态产生的种种现象就能够从机理上给出自己的解释。
virtual虚函数内存机制
上面提到过,virtual是让子类与父类之间的同名函数有联系,这就是多态性,实现动态绑定。
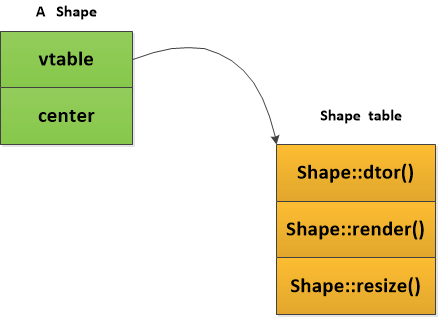
任何类若是有虚函数就会比正常类大一点,所有有virtual的类的对象里面最头上会自动加上一个隐藏的,不让我知道的指针,它指向一张表,注意,该表对于同一个class的不同对象是同一个,不同class(指父类子类)的表不同。这张表叫做vtable(虚表),vtable里是所有virtual函数的地址,对于下面代码,
class Shape {
public:
Shape();
virtual ~Shape();
virtual void render();
void move(const pos&);
virtual void resize();
protected:
pos center;
};
其内存分布如下:
我们看一下其子类的内存分布:
class Ellipse : public Shape{
public:
Ellipse (float majr, float minr);
virtual void render();
protected:
float major_axis;
float minor_axis;
};
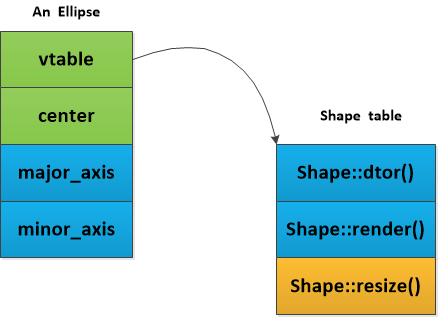
这里的resize沿用了shape的成员函数。
多态实现逻辑
看如下代码,
#include "stdafx.h"
#include <iostream>
#include <stdlib.h>
using namespace std;
class Father
{
public:
void Face()
{
cout << "Father's face" << endl;
}
void Say()
{
cout << "Father say hello" << endl;
}
};
class Son:public Father
{
public:
void Say()
{
cout << "Son say hello" << endl;
}
};
void main()
{
Son son;
Father *pFather=&son; // 隐式类型转换
pFather->Say();
}
输出的结果为:
我们在main()函数中首先定义了一个Son类的对象son,接着定义了一个指向Father类的指针变量pFather,然后利用该变量调用pFather->Say().估计很多人往往将这种情况和c++的多态性搞混淆,认为son实际上是Son类的对象,应该是调用Son类的Say,输出"Son say hello",然而结果却不是.
从编译的角度来看:
c++编译器在编译的时候,要确定每个对象调用的函数(非虚函数)的地址,这称为早期绑定,当我们将Son类的对象son的地址赋给pFather时,c++编译器进行了类型转换,此时c++编译器认为变量pFather保存的就是Father对象的地址,当在main函数中执行pFather->Say(),调用的当然就是Father对象的Say函数
从内存角度看:

Son类对象的内存模型如上图
我们构造Son类的对象时,首先要调用Father类的构造函数去构造Father类的对象,然后才调用Son类的构造函数完成自身部分的构造,从而拼接出一个完整的Son类对象。当我们将Son类对象转换为Father类型时,该对象就被认为是原对象整个内存模型的上半部分,也就是上图中“Father的对象所占内存”,那么当我们利用类型转换后的对象指针去调用它的方法时,当然也就是调用它所在的内存中的方法,因此,输出“Father Say hello”,也就顺理成章了。
正如很多人那么认为,在上面的代码中,我们知道pFather实际上指向的是Son类的对象,我们希望输出的结果是son类的Say方法,那么想到达到这种结果,就要用到虚函数了。
前面输出的结果是因为编译器在编译的时候,就已经确定了对象调用的函数的地址,要解决这个问题就要使用晚绑定,当编译器使用晚绑定时候,就会在运行时再去确定对象的类型以及正确的调用函数,而要让编译器采用晚绑定,就要在基类中声明函数时使用virtual关键字,这样的函数我们就称之为虚函数,一旦某个函数在基类中声明为virtual,那么在所有的派生类中该函数都是virtual,而不需要再显式地声明为virtual。
代码稍微改动一下,看一下运行结果
#include "stdafx.h"
#include <iostream>
#include <stdlib.h>
using namespace std;
class Father
{
public:
void Face()
{
cout << "Father's face" << endl;
}
virtual void Say()
{
cout << "Father say hello" << endl;
}
};
class Son:public Father
{
public:
void Say()
{
cout << "Son say hello" << endl;
}
};
void main()
{
Son son;
Father *pFather=&son; // 隐式类型转换
pFather->Say();
}

我们发现结果是"Son say hello"也就是根据对象的类型调用了正确的函数,那么当我们将Say()声明为virtual时,背后发生了什么。
编译器在编译的时候,发现Father类中有虚函数,此时编译器会为每个包含虚函数的类创建一个虚表(即 vtable),该表是一个一维数组,在这个数组中存放每个虚函数的地址,

那么如何定位虚表呢?编译器另外还为每个对象提供了一个虚表指针(即vptr),这个指针指向了对象所属类的虚表,在程序运行时,根据对象的类型去初始化vptr,从而让vptr正确的指向了所属类的虚表,从而在调用虚函数的时候,能够找到正确的函数,对于第二段代码程序,由于pFather实际指向的对象类型是Son,因此vptr指向的Son类的vtable,当调用pFather->Son()时,根据虚表中的函数地址找到的就是Son类的Say()函数.
正是由于每个对象调用的虚函数都是通过虚表指针来索引的,也就决定了虚表指针的正确初始化是非常重要的,换句话说,在虚表指针没有正确初始化之前,我们不能够去调用虚函数,那么虚表指针是在什么时候,或者什么地方初始化呢?
答案是在构造函数中进行虚表的创建和虚表指针的初始化,在构造子类对象时,要先调用父类的构造函数,此时编译器只“看到了”父类,并不知道后面是否还有继承者,它初始化父类对象的虚表指针,该虚表指针指向父类的虚表,当执行子类的构造函数时,子类对象的虚表指针被初始化,指向自身的虚表。