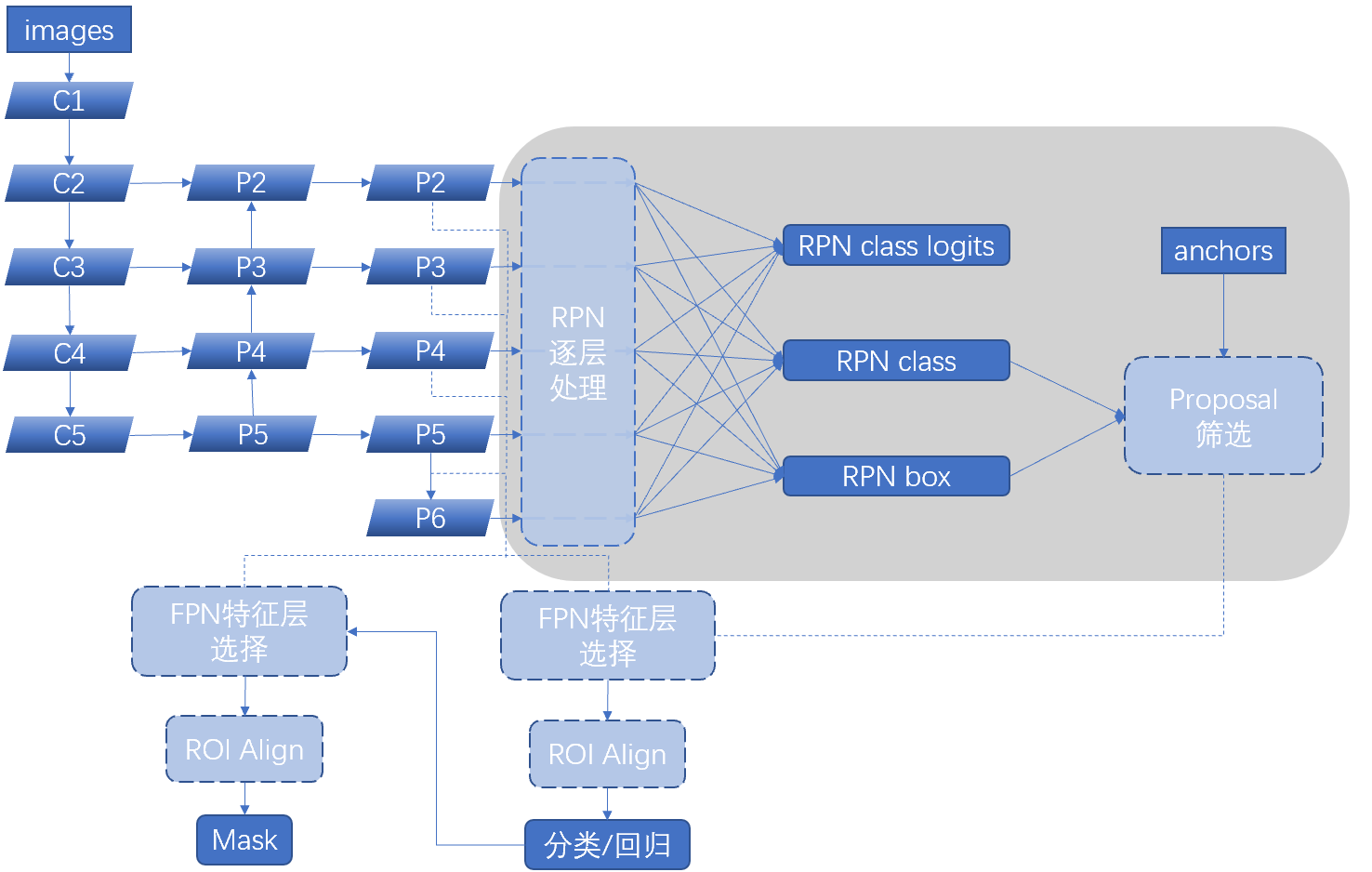
一、RPN锚框信息生成
上文的最后,我们生成了用于计算锚框信息的特征(源代码在inference模式中不进行锚框生成,而是外部生成好feed进网络,training模式下在向前传播时直接生成锚框,不过实际上没什么区别,锚框生成的讲解见『计算机视觉』Mask-RCNN_锚框生成):
rpn_feature_maps = [P2, P3, P4, P5, P6]
接下来,我们基于上述特征首先生成锚框的信息,包含每个锚框的前景/背景得分信息及每个锚框的坐标修正信息。
接前文主函数,我们初始化rpn model class的对象,并应用于各层特征:
# Anchors
if mode == "training":
……
else:
anchors = input_anchors
# RPN Model, 返回的是keras的Module对象, 注意keras中的Module对象是可call的
rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE, # 1 3 256
len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE)
# Loop through pyramid layers
layer_outputs = [] # list of lists
for p in rpn_feature_maps:
layer_outputs.append(rpn([p])) # 保存各pyramid特征经过RPN之后的结果
具体的RPN模块调用函数栈如下,
############################################################
# Region Proposal Network (RPN)
############################################################
def rpn_graph(feature_map, anchors_per_location, anchor_stride):
"""Builds the computation graph of Region Proposal Network.
feature_map: backbone features [batch, height, width, depth]
anchors_per_location: number of anchors per pixel in the feature map
anchor_stride: Controls the density of anchors. Typically 1 (anchors for
every pixel in the feature map), or 2 (every other pixel).
Returns:
rpn_class_logits: [batch, H * W * anchors_per_location, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, H * W * anchors_per_location, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H * W * anchors_per_location, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
"""
# TODO: check if stride of 2 causes alignment(校准,对齐) issues if the feature map
# is not even.
# Shared convolutional base of the RPN
shared = KL.Conv2D(512, (3, 3), padding='same', activation='relu',
strides=anchor_stride,
name='rpn_conv_shared')(feature_map)
# Anchor Score. [batch, height, width, anchors per location * 2].
x = KL.Conv2D(2 * anchors_per_location, (1, 1), padding='valid',
activation='linear', name='rpn_class_raw')(shared)
# Reshape to [batch, anchors, 2]
rpn_class_logits = KL.Lambda(
lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 2]))(x)
# Output tensors to a Model must be Keras tensors, 所以下面不行
# rpn_class_logits = tf.reshape(x, [tf.shape(x)[0], -1, 2])
# Softmax on last dimension of BG/FG.
rpn_probs = KL.Activation(
"softmax", name="rpn_class_xxx")(rpn_class_logits)
# Bounding box refinement. [batch, H, W, anchors per location * depth]
# where depth is [x, y, log(w), log(h)]
x = KL.Conv2D(anchors_per_location * 4, (1, 1), padding="valid",
activation='linear', name='rpn_bbox_pred')(shared)
# Reshape to [batch, anchors, 4]
rpn_bbox = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 4]))(x)
return [rpn_class_logits, rpn_probs, rpn_bbox]
def build_rpn_model(anchor_stride, anchors_per_location, depth):
"""Builds a Keras model of the Region Proposal Network.
It wraps the RPN graph so it can be used multiple times with shared
weights.
anchors_per_location: number of anchors per pixel in the feature map
anchor_stride: Controls the density of anchors. Typically 1 (anchors for
every pixel in the feature map), or 2 (every other pixel).
depth: Depth of the backbone feature map.
Returns a Keras Model object. The model outputs, when called, are:
rpn_class_logits: [batch, H * W * anchors_per_location, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, H * W * anchors_per_location, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H * W * anchors_per_location, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
"""
input_feature_map = KL.Input(shape=[None, None, depth],
name="input_rpn_feature_map")
# [rpn_class_logits, rpn_probs, rpn_bbox] input_feature_map 3 1
outputs = rpn_graph(input_feature_map, anchors_per_location, anchor_stride)
return KM.Model([input_feature_map], outputs, name="rpn_model")
接前文主函数,我们将获取的list形式的各层锚框信息进行拼接重组:
# Loop through pyramid layers
layer_outputs = [] # list of lists
for p in rpn_feature_maps:
layer_outputs.append(rpn([p])) # 保存各pyramid特征经过RPN之后的结果
# Concatenate layer outputs
# Convert from list of lists of level outputs to list of lists
# of outputs across levels.
# e.g. [[a1, b1, c1], [a2, b2, c2]] => [[a1, a2], [b1, b2], [c1, c2]]
output_names = ["rpn_class_logits", "rpn_class", "rpn_bbox"]
outputs = list(zip(*layer_outputs)) # [[logits2,……6], [class2,……6], [bbox2,……6]]
outputs = [KL.Concatenate(axis=1, name=n)(list(o))
for o, n in zip(outputs, output_names)]
# [batch, num_anchors, 2/4]
# 其中num_anchors指的是全部特征层上的anchors总数
rpn_class_logits, rpn_class, rpn_bbox = outputs
目的很简单,原来的返回值为[(logits2, class2, bbox2), (logits3, class3, bbox3), ……],首先将之转换为[[logits2,……6], [class2,……6], [bbox2,……6]],然后将每个小list中的tensor按照第一维度(即anchors维度)拼接,得到三个tensor,每个tensor表明batch中图片对应5个特征层的全部anchors的分类回归信息,即:[batch, anchors, 2分类结果 or (dy, dx, log(dh), log(dw))]。
二、Proposal建议区生成
上一步我们获取了全部锚框的信息,这里我们的目的是从中挑选指定个数的更可能包含obj的锚框作为建议区域,即我们希望获取在上一步的二分类中前景得分更高的框,同时,由于锚框生成算法的设计,其数量巨大且重叠严重,我们在得分高低的基础上,进一步的希望能够去重(非极大值抑制),这就是proposal生成的目的。
接前文主函数,我们用下面的代码进入候选区生成过程,
# Generate proposals
# Proposals are [batch, N, (y1, x1, y2, x2)] in normalized coordinates
# and zero padded.
# POST_NMS_ROIS_INFERENCE = 1000
# POST_NMS_ROIS_TRAINING = 2000
proposal_count = config.POST_NMS_ROIS_TRAINING if mode == "training"
else config.POST_NMS_ROIS_INFERENCE
# [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)]
# IMAGES_PER_GPU取代了batch,之后说的batch都是IMAGES_PER_GPU
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD, # 0.7
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
proposal_count是一个整数,用于指定生成proposal数目,不足时会生成坐标为[0,0,0,0]的空值进行补全。
1、初始化ProposalLayer class
下面我们来看看ProposalLayer的过程,在初始部分我们获取[rpn_class, rpn_bbox, anchors]三个张量作为参数,
class ProposalLayer(KE.Layer):
"""Receives anchor scores and selects a subset to pass as proposals
to the second stage. Filtering is done based on anchor scores and
non-max suppression to remove overlaps. It also applies bounding
box refinement deltas to anchors.
Inputs:
rpn_probs: [batch, num_anchors, (bg prob, fg prob)]
rpn_bbox: [batch, num_anchors, (dy, dx, log(dh), log(dw))]
anchors: [batch, num_anchors, (y1, x1, y2, x2)] anchors in normalized coordinates
Returns:
Proposals in normalized coordinates [batch, rois, (y1, x1, y2, x2)]
"""
def __init__(self, proposal_count, nms_threshold, config=None, **kwargs):
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
self.proposal_count = proposal_count
self.nms_threshold = nms_threshold
def call(self, inputs):
# [rpn_class, rpn_bbox, anchors]
# Box Scores. Use the foreground class confidence. [batch, num_rois, 2]->[batch, num_rois]
scores = inputs[0][:, :, 1]
# Box deltas. 记录坐标修正信息:(dy, dx, log(dh), log(dw)). [batch, num_rois, 4]
deltas = inputs[1]
deltas = deltas * np.reshape(self.config.RPN_BBOX_STD_DEV, [1, 1, 4]) # [ 0.1 0.1 0.2 0.2]
# Anchors. 记录坐标信息:(y1, x1, y2, x2). [batch, num_rois, 4]
anchors = inputs[2]
这里的变量scores = inputs[0][:, :, 1],即我们只需要全部候选框的前景得分。
2、top k锚框筛选
然后我们获取前景得分最大的n个候选框,
# Improve performance by trimming to top anchors by score
# and doing the rest on the smaller subset.
pre_nms_limit = tf.minimum(self.config.PRE_NMS_LIMIT, tf.shape(anchors)[1])
# 输入矩阵时输出每一行的top k. [batch, top_k]
ix = tf.nn.top_k(scores, pre_nms_limit, sorted=True,
name="top_anchors").indices
提取top k锚框,我们同时对三个输入进行了提取
# batch_slice函数:
# # 将batch特征拆分为单张
# # 然后提取指定的张数
# # 使用单张特征处理函数处理,并合并(此时返回的第一维不是输入时的batch,而是上步指定的张数)
scores = utils.batch_slice([scores, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
deltas = utils.batch_slice([deltas, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
pre_nms_anchors = utils.batch_slice([anchors, ix], lambda a, x: tf.gather(a, x),
self.config.IMAGES_PER_GPU,
names=["pre_nms_anchors"])
附录.辅助函数batch_slice
其中使用了一个后面也会大量使用的函数:batch_slice,我尝试使用tf的while_loop进行了改写。
这个函数将只支持batch为1的函数进行了扩展(实际就是不能有batch维度的函数),tf.gather函数只能进行一维数组的切片,而scares为2维[batch, num_rois],相对的ix也是二维[batch, top_k],所以我们需要将两者切片应用函数后将结果拼接。
【注】本函数位于util.py而非model.py
# ## Batch Slicing
# Some custom layers support a batch size of 1 only, and require a lot of work
# to support batches greater than 1. This function slices an input tensor
# across the batch dimension and feeds batches of size 1. Effectively,
# an easy way to support batches > 1 quickly with little code modification.
# In the long run, it's more efficient to modify the code to support large
# batches and getting rid of this function. Consider this a temporary solution
def batch_slice(inputs, graph_fn, batch_size, names=None):
"""Splits inputs into slices and feeds each slice to a copy of the given
computation graph and then combines the results. It allows you to run a
graph on a batch of inputs even if the graph is written to support one
instance only.
inputs: list of tensors. All must have the same first dimension length
graph_fn: A function that returns a TF tensor that's part of a graph.
batch_size: number of slices to divide the data into.
names: If provided, assigns names to the resulting tensors.
"""
if not isinstance(inputs, list):
inputs = [inputs]
outputs = []
for i in range(batch_size):
inputs_slice = [x[i] for x in inputs]
output_slice = graph_fn(*inputs_slice)
if not isinstance(output_slice, (tuple, list)):
output_slice = [output_slice]
outputs.append(output_slice)
# 使用tf.while_loop实现循环体代码如下:
# import tensorflow as tf
# i = 0
# outputs = []
#
# def cond(index):
# return index < batch_size # 返回bool值
#
# def body(index):
# index += 1
# inputs_slice = [x[i] for x in inputs]
# output_slice = graph_fn(*inputs_slice)
# if not isinstance(output_slice, (tuple, list)):
# output_slice = [output_slice]
# outputs.append(output_slice)
# return index # 返回cond需要的判断参数进行下一次判断
#
# tf.while_loop(cond, body, [i])
# Change outputs from a list of slices where each is
# a list of outputs to a list of outputs and each has
# a list of slices
# 下面示意中假设每次graph_fn返回两个tensor
# [[tensor11, tensor12], [tensor21, tensor22], ……]
# ——> [(tensor11, tensor21, ……), (tensor12, tensor22, ……)] zip返回的是多个tuple
outputs = list(zip(*outputs))
if names is None:
names = [None] * len(outputs)
# 一般来讲就是batch维度合并回去(上面的for循环实际是将batch拆分了)
result = [tf.stack(o, axis=0, name=n)
for o, n in zip(outputs, names)]
if len(result) == 1:
result = result[0]
return result
3、锚框坐标初调
我们在RPN中获取了全部锚框的坐标回归结果,rpn_bbox:[batch, anchors, (dy, dx, log(dh), log(dw))],2小节中我们将top k锚框的坐标信息以及top k的回归信息提取了出来,现在我们将之合并(使用RPN回归的结果取修正top k锚框的坐标),
# Apply deltas to anchors to get refined anchors.
# [IMAGES_PER_GPU, top_k, (y1, x1, y2, x2)]
boxes = utils.batch_slice([pre_nms_anchors, deltas],
lambda x, y: apply_box_deltas_graph(x, y),
self.config.IMAGES_PER_GPU,
names=["refined_anchors"])
函数如下,
def apply_box_deltas_graph(boxes, deltas):
"""Applies the given deltas to the given boxes.
boxes: [N, (y1, x1, y2, x2)] boxes to update
deltas: [N, (dy, dx, log(dh), log(dw))] refinements to apply
"""
# dy = (y_n - y_o)/h_o
# dx = (x_n - x_o)/w_o
# dh = h_n/h_o
# dw = w_n/w_o
# Convert to y, x, h, w
height = boxes[:, 2] - boxes[:, 0]
width = boxes[:, 3] - boxes[:, 1]
center_y = boxes[:, 0] + 0.5 * height
center_x = boxes[:, 1] + 0.5 * width
# Apply deltas
center_y += deltas[:, 0] * height
center_x += deltas[:, 1] * width
height *= tf.exp(deltas[:, 2])
width *= tf.exp(deltas[:, 3])
# Convert back to y1, x1, y2, x2
y1 = center_y - 0.5 * height
x1 = center_x - 0.5 * width
y2 = y1 + height
x2 = x1 + width
result = tf.stack([y1, x1, y2, x2], axis=1, name="apply_box_deltas_out")
return result
自此我们在代码层面认识到了回归结果4个坐标值的真正含义:
dy = (y_n - y_o)/h_o
dx = (x_n - x_o)/w_o
dh = h_n/h_o #
dw = w_n/w_o
注意,我们的锚框坐标实际上是位于一个归一化了的图上(SSD也是如此且有过介绍,见『TensorFlow』SSD源码学习_其三:锚框生成,即所有锚框位于一个长宽为1的虚拟画布上),上一步的修正进行之后不再能够保证这一点,所以我们需要切除锚框越界的的部分(即只保留锚框和[0,0,1,1]画布的交集)。
# Clip to image boundaries. Since we're in normalized coordinates,
# clip to 0..1 range. [IMAGES_PER_GPU, top_k, (y1, x1, y2, x2)]
window = np.array([0, 0, 1, 1], dtype=np.float32)
boxes = utils.batch_slice(boxes, # boxes来源自anchors, 修正deltas的影响
lambda x: clip_boxes_graph(x, window),
self.config.IMAGES_PER_GPU,
names=["refined_anchors_clipped"])
保留交集函数如下,
def clip_boxes_graph(boxes, window):
"""
boxes: [N, (y1, x1, y2, x2)]
window: [4] in the form y1, x1, y2, x2
"""
# Split
wy1, wx1, wy2, wx2 = tf.split(window, 4)
y1, x1, y2, x2 = tf.split(boxes, 4, axis=1)
# Clip
y1 = tf.maximum(tf.minimum(y1, wy2), wy1)
x1 = tf.maximum(tf.minimum(x1, wx2), wx1)
y2 = tf.maximum(tf.minimum(y2, wy2), wy1)
x2 = tf.maximum(tf.minimum(x2, wx2), wx1)
clipped = tf.concat([y1, x1, y2, x2], axis=1, name="clipped_boxes")
clipped.set_shape((clipped.shape[0], 4))
return clipped
4、非极大值抑制
最后进行非极大值抑制,确保不会出现过于重复的推荐区域,
# Filter out small boxes
# According to Xinlei Chen's paper, this reduces detection accuracy
# for small objects, so we're skipping it.
# Non-max suppression
def nms(boxes, scores):
"""
非极大值抑制子函数
:param boxes: [top_k, (y1, x1, y2, x2)]
:param scores: [top_k]
:return:
"""
indices = tf.image.non_max_suppression(
boxes, scores, self.proposal_count, # 参数三为最大返回数目
self.nms_threshold, name="rpn_non_max_suppression")
proposals = tf.gather(boxes, indices)
# Pad if needed, 一旦返回数目不足, 填充(0,0,0,0)直到数目达标
padding = tf.maximum(self.proposal_count - tf.shape(proposals)[0], 0)
# 在后面添加全0行
proposals = tf.pad(proposals, [(0, padding), (0, 0)])
return proposals
proposals = utils.batch_slice([boxes, scores], nms,
self.config.IMAGES_PER_GPU)
return proposals # [IMAGES_PER_GPU, proposal_count, (y1, x1, y2, x2)]
没错,TensorFlow以经封装好了:tf.image.non_max_suppression
至此,我们获取了全部的推荐区域。