一、模块概述
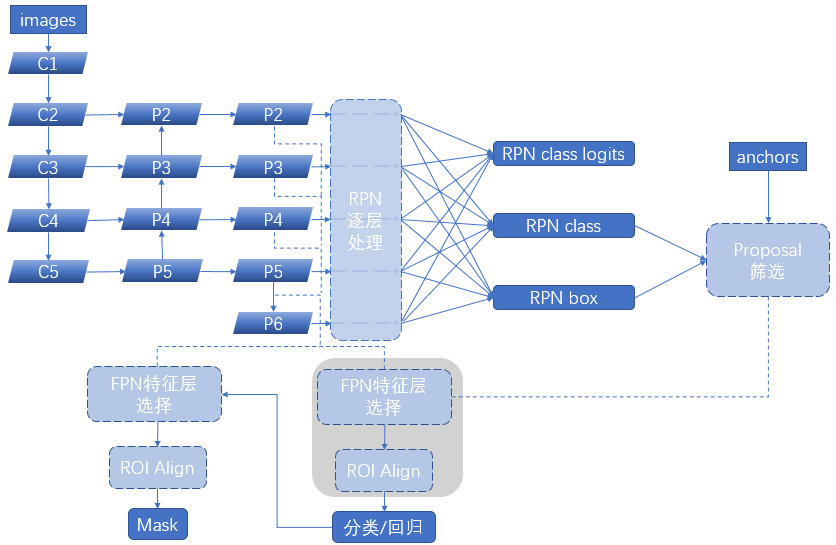
上节的最后,我们进行了如下操作获取了有限的proposal,
# [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)]
# IMAGES_PER_GPU取代了batch,之后说的batch都是IMAGES_PER_GPU
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD, # 0.7
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
总结一下:
与 GT 的 IOU 大于0.7
与某一个 GT 的 IOU 最大的那个 anchor
进一步,我们需要按照RCNN的思路,使用proposal对共享特征进行ROI操作,在Mask-RCNN中这里有两个创新:
ROI使用ROI Align取代了之前的ROI Pooling
共享特征由之前的单层变换为了FPN得到的金字塔多层特征,即:
mrcnn_feature_maps=[P2, P3, P4, P5]
其中创新点2意味着我们不同的proposal对应去ROI的特征层并不相同,所以,我们需要:
按照proposal的长宽,将不同的proposal对应给不同的特征层
在对应特征层上进行ROI操作
二、实现分析
下面会用到高维切片函数,这里先行给出讲解链接:『TensorFlow』高级高维切片gather_nd
接前文bulid函数代码,我们如下调入实现本节的功能,
if mode == "training":
……
else:
# Network Heads
# Proposal classifier and BBox regressor heads
# output shapes:
# mrcnn_class_logits: [batch, num_rois, NUM_CLASSES] classifier logits (before softmax)
# mrcnn_class: [batch, num_rois, NUM_CLASSES] classifier probabilities
# mrcnn_bbox(deltas): [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =
fpn_classifier_graph(rpn_rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
FPN特征层分类函数纵览如下,
############################################################
# Feature Pyramid Network Heads
############################################################
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024):
"""Builds the computation graph of the feature pyramid network classifier
and regressor heads.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
fc_layers_size: Size of the 2 FC layers
Returns:
logits: [batch, num_rois, NUM_CLASSES] classifier logits (before softmax)
probs: [batch, num_rois, NUM_CLASSES] classifier probabilities
bbox_deltas: [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes
"""
# ROI Pooling
# Shape: [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
# Two 1024 FC layers (implemented with Conv2D for consistency)
# TimeDistributed拆分了输入数据的第1维(从0开始),将完全一样的模型独立的应用于拆分后的输入数据,具体到下行,
# 就是将num_rois个卷积应用到num_rois个维度为[batch, POOL_SIZE, POOL_SIZE, channels]的输入,结果合并
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x) # [batch, num_rois, 1, 1, 1024]
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x) # [batch, num_rois, 1024]
# Classifier head
mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# [batch, num_rois, NUM_CLASSES * (dy, dx, log(dh), log(dw))]
x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
s = K.int_shape(x)
# 下行源码:K.reshape(inputs, (K.shape(inputs)[0],) + self.target_shape)
mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
下面我们来分析一下该函数。进入函数,首先调用了PyramidROI,
# ROI Pooling
# Shape: [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
这个class基本实现了我们开篇所说的全部功能,即特征层分类并ROI。
ROIAlign类
首先我们依据『计算机视觉』FPN特征金字塔网络中第三节所讲,对proposal进行分类,注意的是我们使用于网络中的hw是归一化了的(以原图hw为单位长度),所以计算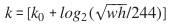 时需要还原(对于公式而言:w,h分别表示宽度和高度;k是分配RoI的level;
时需要还原(对于公式而言:w,h分别表示宽度和高度;k是分配RoI的level;是w,h=224,224时映射的level)。
注意两个操作节点:level_boxes和box_indices,第一个记录了对应的level特征层中分配到的每个box的坐标,第二个则记录了每个box对应的图片在batch中的索引(一个记录了候选框索引对应的图片即下文中的两个大块,一个记录了候选框的索引对应其坐标即小黑框的坐标),两者结合可以索引到下面每个黑色小框的坐标信息。
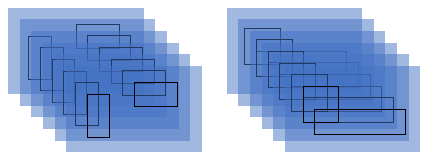
至于ROI Align本身,实际就是双线性插值,使用内置API实现即可。
这里属于RPN网络和RCNN网络的分界线,level_boxes和box_indices本身属于RPN计算出来结果,但是两者作用于feature后的输出Tensor却是RCNN部分的输入,但是两部分的梯度不能相互流通的,所以需要tf.stop_gradient()截断梯度传播。
############################################################
# ROIAlign Layer
############################################################
def log2_graph(x):
"""Implementation of Log2. TF doesn't have a native implementation."""
return tf.log(x) / tf.log(2.0)
class PyramidROIAlign(KE.Layer):
"""Implements ROI Pooling on multiple levels of the feature pyramid.
Params:
- pool_shape: [pool_height, pool_width] of the output pooled regions. Usually [7, 7]
Inputs:
- boxes: [batch, num_boxes, (y1, x1, y2, x2)] in normalized
coordinates. Possibly padded with zeros if not enough
boxes to fill the array.
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
- feature_maps: List of feature maps from different levels of the pyramid.
Each is [batch, height, width, channels]
Output:
Pooled regions in the shape: [batch, num_boxes, pool_height, pool_width, channels].
The width and height are those specific in the pool_shape in the layer
constructor.
"""
def __init__(self, pool_shape, **kwargs):
super(PyramidROIAlign, self).__init__(**kwargs)
self.pool_shape = tuple(pool_shape)
def call(self, inputs):
# num_boxes指的是proposal数目,它们均会作用于每张图片上,只是不同的proposal作用于图片
# 的特征级别不同,我通过循环特征层寻找符合的proposal,应用ROIAlign
# Crop boxes [batch, num_boxes, (y1, x1, y2, x2)] in normalized coords
boxes = inputs[0]
# Image meta
# Holds details about the image. See compose_image_meta()
image_meta = inputs[1]
# Feature Maps. List of feature maps from different level of the
# feature pyramid. Each is [batch, height, width, channels]
feature_maps = inputs[2:]
# Assign each ROI to a level in the pyramid based on the ROI area.
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# Use shape of first image. Images in a batch must have the same size.
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0] # h, w, c
# Equation 1 in the Feature Pyramid Networks paper. Account for
# the fact that our coordinates are normalized here.
# e.g. a 224x224 ROI (in pixels) maps to P4
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32)
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area))) # h、w已经归一化
roi_level = tf.minimum(5, tf.maximum(
2, 4 + tf.cast(tf.round(roi_level), tf.int32))) # 确保值位于2到5之间
roi_level = tf.squeeze(roi_level, 2) # [batch, num_boxes]
# Loop through levels and apply ROI pooling to each. P2 to P5.
pooled = []
box_to_level = []
for i, level in enumerate(range(2, 6)):
# tf.where 返回值格式 [坐标1, 坐标2……]
# np.where 返回值格式 [[坐标1.x, 坐标2.x……], [坐标1.y, 坐标2.y……]]
ix = tf.where(tf.equal(roi_level, level)) # 返回坐标表示:第n张图片的第i个proposal
level_boxes = tf.gather_nd(boxes, ix) # [本level的proposal数目, 4]
# Box indices for crop_and_resize.
box_indices = tf.cast(ix[:, 0], tf.int32) # 记录每个propose对应图片序号
# Keep track of which box is mapped to which level
box_to_level.append(ix)
# Stop gradient propogation to ROI proposals
level_boxes = tf.stop_gradient(level_boxes)
box_indices = tf.stop_gradient(box_indices)
# Crop and Resize
# From Mask R-CNN paper: "We sample four regular locations, so
# that we can evaluate either max or average pooling. In fact,
# interpolating only a single value at each bin center (without
# pooling) is nearly as effective."
#
# Here we use the simplified approach of a single value per bin,
# which is how it's done in tf.crop_and_resize()
# Result: [this_level_num_boxes, pool_height, pool_width, channels]
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))
# 输入参数shape:
# [batch, image_height, image_width, channels]
# [this_level_num_boxes, 4]
# [this_level_num_boxes]
# [height, pool_width]
# Pack pooled features into one tensor
pooled = tf.concat(pooled, axis=0) # [batch*num_boxes, pool_height, pool_width, channels]
# Pack box_to_level mapping into one array and add another
# column representing the order of pooled boxes
box_to_level = tf.concat(box_to_level, axis=0) # [batch*num_boxes, 2]
box_range = tf.expand_dims(tf.range(tf.shape(box_to_level)[0]), 1) # [batch*num_boxes, 1]
box_to_level = tf.concat([tf.cast(box_to_level, tf.int32), box_range],
axis=1) # [batch*num_boxes, 3]
# 截止到目前,我们获取了记录全部ROIAlign结果feat集合的张量pooled,和记录这些feat相关信息的张量box_to_level,
# 由于提取方法的原因,此时的feat并不是按照原始顺序排序(先按batch然后按box index排序),下面我们设法将之恢复顺
# 序(ROIAlign作用于对应图片的对应proposal生成feat)
# Rearrange pooled features to match the order of the original boxes
# Sort box_to_level by batch then box index
# TF doesn't have a way to sort by two columns, so merge them and sort.
# box_to_level[i, 0]表示的是当前feat隶属的图片索引,box_to_level[i, 1]表示的是其box序号
sorting_tensor = box_to_level[:, 0] * 100000 + box_to_level[:, 1] # [batch*num_boxes]
ix = tf.nn.top_k(sorting_tensor, k=tf.shape(
box_to_level)[0]).indices[::-1]
ix = tf.gather(box_to_level[:, 2], ix)
pooled = tf.gather(pooled, ix)
# Re-add the batch dimension
# [batch, num_boxes, (y1, x1, y2, x2)], [batch*num_boxes, pool_height, pool_width, channels]
shape = tf.concat([tf.shape(boxes)[:2], tf.shape(pooled)[1:]], axis=0)
pooled = tf.reshape(pooled, shape)
return pooled # [batch, num_boxes, pool_height, pool_width, channels]
初步分类/回归
经过ROI之后,我们获取了众多shape一致的小feat,为了获取他们的分类回归信息,我们构建一系列并行的网络进行处理,
# Two 1024 FC layers (implemented with Conv2D for consistency)
# TimeDistributed拆分了输入数据的第1维(从0开始),将完全一样的模型独立的应用于拆分后的输入数据,具体到下行,
# 就是将num_rois个卷积应用到num_rois个维度为[batch, POOL_SIZE, POOL_SIZE, channels]的输入,结果合并
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x) # [batch, num_rois, 1, 1, 1024]
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x) # [batch, num_rois, 1024]
# Classifier head
mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# [batch, num_rois, NUM_CLASSES * (dy, dx, log(dh), log(dw))]
x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
s = K.int_shape(x)
# 下行源码:K.reshape(inputs, (K.shape(inputs)[0],) + self.target_shape)
mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
返回如下:
mrcnn_class_logits: [batch, num_rois, NUM_CLASSES] classifier logits (before softmax)
mrcnn_class: [batch, num_rois, NUM_CLASSES] classifier probabilities
mrcnn_bbox(deltas): [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
KL.TimeDistributed实现建立一系列同样架构的的并行网络结构(dim0个),将[dim0, dim1, ……]中的每个[dim1, ……]作为输入,并行的计算输出。
附、build函数总览
def build(self, mode, config):
"""Build Mask R-CNN architecture.
input_shape: The shape of the input image.
mode: Either "training" or "inference". The inputs and
outputs of the model differ accordingly.
"""
assert mode in ['training', 'inference']
# Image size must be dividable by 2 multiple times
h, w = config.IMAGE_SHAPE[:2] # [1024 1024 3]
if h / 2**6 != int(h / 2**6) or w / 2**6 != int(w / 2**6): # 这里就限定了下采样不会产生坐标误差
raise Exception("Image size must be dividable by 2 at least 6 times "
"to avoid fractions when downscaling and upscaling."
"For example, use 256, 320, 384, 448, 512, ... etc. ")
# Inputs
input_image = KL.Input(
shape=[None, None, config.IMAGE_SHAPE[2]], name="input_image")
input_image_meta = KL.Input(shape=[config.IMAGE_META_SIZE],
name="input_image_meta")
if mode == "training":
# RPN GT
input_rpn_match = KL.Input(
shape=[None, 1], name="input_rpn_match", dtype=tf.int32)
input_rpn_bbox = KL.Input(
shape=[None, 4], name="input_rpn_bbox", dtype=tf.float32)
# Detection GT (class IDs, bounding boxes, and masks)
# 1. GT Class IDs (zero padded)
input_gt_class_ids = KL.Input(
shape=[None], name="input_gt_class_ids", dtype=tf.int32)
# 2. GT Boxes in pixels (zero padded)
# [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)] in image coordinates
input_gt_boxes = KL.Input(
shape=[None, 4], name="input_gt_boxes", dtype=tf.float32)
# Normalize coordinates
gt_boxes = KL.Lambda(lambda x: norm_boxes_graph(
x, K.shape(input_image)[1:3]))(input_gt_boxes)
# 3. GT Masks (zero padded)
# [batch, height, width, MAX_GT_INSTANCES]
if config.USE_MINI_MASK:
input_gt_masks = KL.Input(
shape=[config.MINI_MASK_SHAPE[0],
config.MINI_MASK_SHAPE[1], None],
name="input_gt_masks", dtype=bool)
else:
input_gt_masks = KL.Input(
shape=[config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1], None],
name="input_gt_masks", dtype=bool)
elif mode == "inference":
# Anchors in normalized coordinates
input_anchors = KL.Input(shape=[None, 4], name="input_anchors")
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# Don't create the thead (stage 5), so we pick the 4th item in the list.
if callable(config.BACKBONE):
_, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True,
train_bn=config.TRAIN_BN)
else:
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE,
stage5=True, train_bn=config.TRAIN_BN)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5) # 256
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]
# Anchors
if mode == "training":
anchors = self.get_anchors(config.IMAGE_SHAPE)
# Duplicate across the batch dimension because Keras requires it
# TODO: can this be optimized to avoid duplicating the anchors?
anchors = np.broadcast_to(anchors, (config.BATCH_SIZE,) + anchors.shape)
# A hack to get around Keras's bad support for constants
anchors = KL.Lambda(lambda x: tf.Variable(anchors), name="anchors")(input_image)
else:
anchors = input_anchors
# RPN Model, 返回的是keras的Module对象, 注意keras中的Module对象是可call的
rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE, # 1 3 256
len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE)
# Loop through pyramid layers
layer_outputs = [] # list of lists
for p in rpn_feature_maps:
layer_outputs.append(rpn([p])) # 保存各pyramid特征经过RPN之后的结果
# Concatenate layer outputs
# Convert from list of lists of level outputs to list of lists
# of outputs across levels.
# e.g. [[a1, b1, c1], [a2, b2, c2]] => [[a1, a2], [b1, b2], [c1, c2]]
output_names = ["rpn_class_logits", "rpn_class", "rpn_bbox"]
outputs = list(zip(*layer_outputs)) # [[logits2,……6], [class2,……6], [bbox2,……6]]
outputs = [KL.Concatenate(axis=1, name=n)(list(o))
for o, n in zip(outputs, output_names)]
# [batch, num_anchors, 2/4]
# 其中num_anchors指的是全部特征层上的anchors总数
rpn_class_logits, rpn_class, rpn_bbox = outputs
# Generate proposals
# Proposals are [batch, N, (y1, x1, y2, x2)] in normalized coordinates
# and zero padded.
# POST_NMS_ROIS_INFERENCE = 1000
# POST_NMS_ROIS_TRAINING = 2000
proposal_count = config.POST_NMS_ROIS_TRAINING if mode == "training"
else config.POST_NMS_ROIS_INFERENCE
# [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)]
# IMAGES_PER_GPU取代了batch,之后说的batch都是IMAGES_PER_GPU
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD, # 0.7
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
if mode == "training":
# Class ID mask to mark class IDs supported by the dataset the image
# came from.
active_class_ids = KL.Lambda(
lambda x: parse_image_meta_graph(x)["active_class_ids"]
)(input_image_meta)
if not config.USE_RPN_ROIS:
# Ignore predicted ROIs and use ROIs provided as an input.
input_rois = KL.Input(shape=[config.POST_NMS_ROIS_TRAINING, 4],
name="input_roi", dtype=np.int32)
# Normalize coordinates
target_rois = KL.Lambda(lambda x: norm_boxes_graph(
x, K.shape(input_image)[1:3]))(input_rois)
else:
target_rois = rpn_rois
# Generate detection targets
# Subsamples proposals and generates target outputs for training
# Note that proposal class IDs, gt_boxes, and gt_masks are zero
# padded. Equally, returned rois and targets are zero padded.
rois, target_class_ids, target_bbox, target_mask =
DetectionTargetLayer(config, name="proposal_targets")([
target_rois, input_gt_class_ids, gt_boxes, input_gt_masks])
# Network Heads
# TODO: verify that this handles zero padded ROIs
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =
fpn_classifier_graph(rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
mrcnn_mask = build_fpn_mask_graph(rois, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
# TODO: clean up (use tf.identify if necessary)
output_rois = KL.Lambda(lambda x: x * 1, name="output_rois")(rois)
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])
# Model
inputs = [input_image, input_image_meta,
input_rpn_match, input_rpn_bbox, input_gt_class_ids, input_gt_boxes, input_gt_masks]
if not config.USE_RPN_ROIS:
inputs.append(input_rois)
outputs = [rpn_class_logits, rpn_class, rpn_bbox,
mrcnn_class_logits, mrcnn_class, mrcnn_bbox, mrcnn_mask,
rpn_rois, output_rois,
rpn_class_loss, rpn_bbox_loss, class_loss, bbox_loss, mask_loss]
model = KM.Model(inputs, outputs, name='mask_rcnn')
else:
# Network Heads
# Proposal classifier and BBox regressor heads
# output shapes:
# mrcnn_class_logits: [batch, num_rois, NUM_CLASSES] classifier logits (before softmax)
# mrcnn_class: [batch, num_rois, NUM_CLASSES] classifier probabilities
# mrcnn_bbox(deltas): [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =
fpn_classifier_graph(rpn_rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
# Detections
# output is [batch, num_detections, (y1, x1, y2, x2, class_id, score)] in
# normalized coordinates
detections = DetectionLayer(config, name="mrcnn_detection")(
[rpn_rois, mrcnn_class, mrcnn_bbox, input_image_meta])
# Create masks for detections
detection_boxes = KL.Lambda(lambda x: x[..., :4])(detections)
mrcnn_mask = build_fpn_mask_graph(detection_boxes, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
model = KM.Model([input_image, input_image_meta, input_anchors],
[detections, mrcnn_class, mrcnn_bbox,
mrcnn_mask, rpn_rois, rpn_class, rpn_bbox],
name='mask_rcnn')
# Add multi-GPU support.
if config.GPU_COUNT > 1:
from mrcnn.parallel_model import ParallelModel
model = ParallelModel(model, config.GPU_COUNT)
return model