elasticsearch专栏:https://www.cnblogs.com/hello-shf/category/1550315.html
一、预备知识
在对document的curd进行深度分析之前,我们不得不了解以下几个小的知识点,不了解一下几个知识点我们将很难理解document是如何进行增删改查的。
1.1、路由(索引)与primary shard不可变
大家有没有考虑过这个问题,当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢? 进程不能是随机的,因为我们将来要检索文档。事实上,它根据一个简单的算法决定:
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是 _id 但也可以自定义。这个 routing 字符串通过哈 希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远 是 0 到 number_of_primary_shards - 1 ,这个数字就是特定文档所在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
我们演示一下这个路由的过程。假设我们有三个节点,一个student索引,对应有三个primary shard和一个replica shard。此时集群如图1所示

向该节点中插入一个document,并且我们指定_id(在es中_id可以自定义es也可以自动生成)假如_id = 1000,根据我们上面描述,此时会按照如下算法计算其会命中哪个shard。假设此时hash(1000)= 13;
shard = hash(routing) % number_of_primary_shards 即: shard = 13 % 3 = 1;(假设hash(1000) = 13) 注:因为es的hash函数具体是怎么计算的不得而知,也不重要,我们主要是关注其原理。
根据计算可得该插入请求会命中P1,shard此时会将该document插入到P1。是不是很简单。
以上也可就是es路由的过程,也可称为es索引(这个索引是动词,理解一下)过程。
1.2、shard负载均衡与节点对等
在es集群中每个节点,每个shard(包括primary shard和replica shard)都具备处理任何请求的能力。这意味着在es集群中节点间是高度的负载均衡的,即并不是只有主节点是流量的入口,每个节点都具备处理请求的能力。primary shard和replica shard也是高度负载均衡的,因为并不是只有primary shard才具备处理curd的能力,replica shard可处理检索的请求。这也是es的性能为什么表现这么好的原因之一。
二、document增、删、改
2.1、增删改过程分析
新建、索引和删除请求都是写(write)操作,它们必须在primary shard上成功完成才能复制到相关的replica shard分片上。
关于新增document索引过程可以参考《es的索引过程》

如上图所示,从客户端发起请求到es集群向客户端响应大致可以分为以上6个阶段。
阶段1:
客户端向node1发起增、删、改请请求。node1将作为协调节点(coordinate node)进行相关工作。
阶段2:
node1根据文档 _id 计算出命中的primary shard为P1,然后将请求转发到node2,P1分片位于node2上面。
阶段3:
node2在P1上处理该请求。如果请求处理成功,node2将会把请求继续转发到其副本R1上。R1位于node3。
阶段4:
node3在R1上处理完该请求,如果成功,node3会将处理成功的消息返回给node2。
阶段5:
node2收到P1副本处理成功的消息,也就意味着该请求已经处理完成。然后将处理结果返回给node1节点。
阶段6:
协调节点node1收到响应结果后,将该结果返回给客户端。
整个过程就完成了。
看到这里大家是不是也在思考一个请求进来,我还要等待所有的分片都处理完成这个操作才算是完成,这样是不是很影响响应速度。基于这个思考,es同样也给我们提供了自定义参数的支持,比如我们可以使用replication参数来指定primary shard是不是要等到replica shard处理完成后才能响应到客户端。但是,该配置配置参数并不推荐使用,大家知道有这么个东西就行了。
2.1、写一致性保障
1 one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行。 2 all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作 3 quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
上面三点其实很好理解,只有quorum所谓的“大部分”感觉不是那么的明确。下面有个公式,当集群中的active(可用)分片数量达到如下公式结果时写操作就是可以执行的。否则该操作将无法进行。
int( (primary + number_of_replicas) / 2 ) + 1
依然用我们上面的例子,假设我们创建了一个student索引,并且设置primary shard为3个,replica shard有1个(这个1个是相对于索引来说的,对于主分片该数字1意味着每个primary shard都对应的存在一个副本)。也就意味着primary=3,number_of_replicas=1(依然是相对于索引)。shard总数为6。
此时计算上面公式可知:
int((3+1)/2) + 1 = 3
PUT /index/type/id?consistency=quorum
当然如果我们不指定就是使用默认的,也就是quorum。
三、document检索
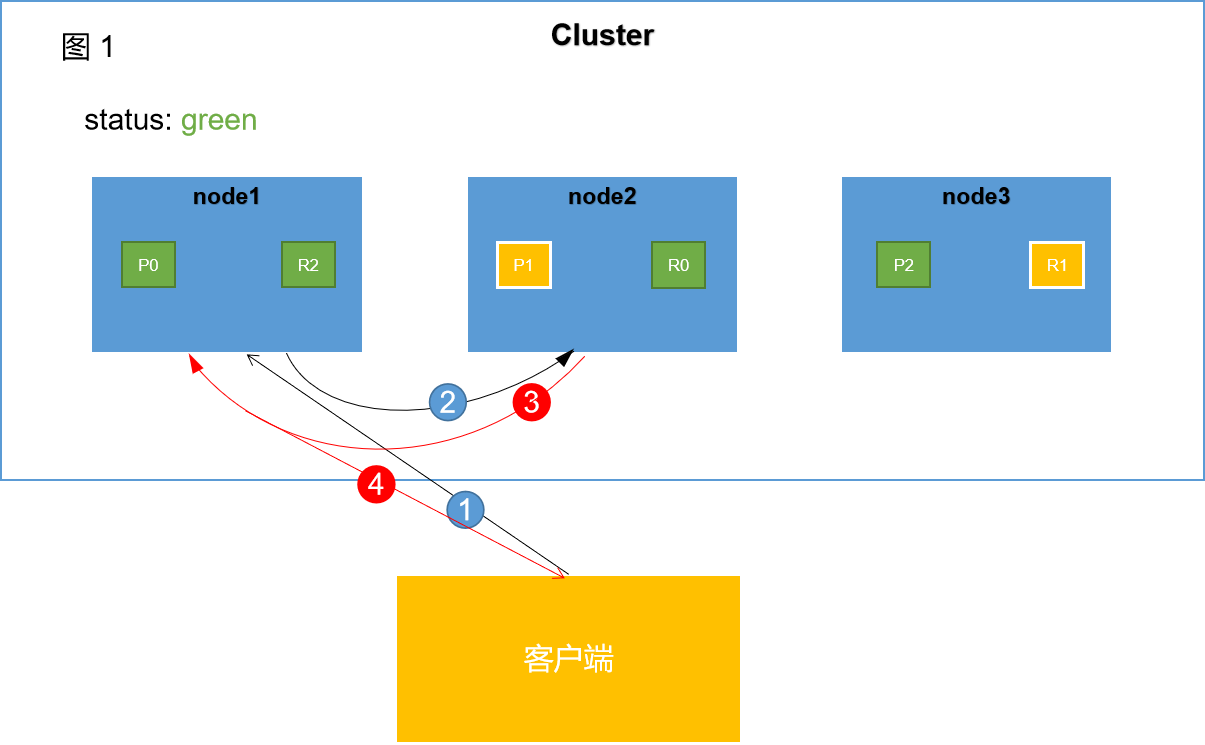
检索过程大致可以分为4个阶段
阶段1:
客户端向node1发送检索请求。node1将作为协调节点(coordinate node)进行相关工作。
阶段2:
node1根据文档 _id 计算出命中的primary shard为P1,node1会找到P1的所有副本,然后通过round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡。假如此时随机选取的是P1,node1会将该请求转发到P1对应的节点上。
阶段3:
P1处理完该请求将结果返回给协调节点node1。
阶段4:
协调节点node1收到该node2的相应结果,进而将该结果返回给客户端。
参考文献:
《elasticsearch-权威指南》
如有错误的地方还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11543480.html