Apache Spark™是用于大规模数据处理的统一分析引擎。
从右侧最后一条新闻看,Spark也用于AI人工智能
中间结果输出:基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的,考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
Spark的四大特性
1、高效性
运行速度提高100倍。
Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能
2、易用性
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
3、通用性
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
4、兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Spark的组成
Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法、机器、人之间展现大数据应用的一个平台。也是处理大数据、云计算、通信的技术解决方案。
它的主要组件有:
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
MLlib:提供常用机器学习算法的实现库。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
应用场景
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。
export PATH=$SCALA_HOME/bin:$PATH
Scala code runner version 2.12.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
[hadoop@master ~]$ scalac -version
Scala compiler version 2.12.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
[hadoop@master ~]$ which scala
~/scala-2.12.8/bin/scala
Scala code runner version 2.12.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
Scala code runner version 2.12.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
安装步骤:
第一步:下载
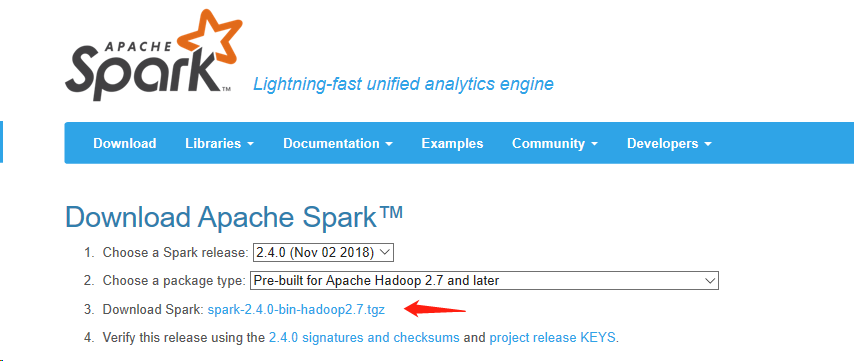
下载可以直接点击Download Spark 后面的链接,不过这个链接特别慢。还有一种下载方法:spark-2.4.0-bin-hadoop2.7.tgz 在这里下载相对会快一点,具体网址:http://www.apache.org/dist/spark/ 下面有各个版本。
第二步:解压
tar -zxvf spark-2.4.0-bin-hadoop2.7.gz
rm -rf spark-2.4.0-bin-hadoop2.7.gz
mv spark-2.4.0-bin-hadoop2.7 spark-2.4.0
第三步,配置环境变量
vi .bash_profile
export SPARK_HOME=/home/hadoop/spark-2.4.0
export PATH=$SPARK_HOME/bin:$PATH
source .bash_profile
此处需要配置的文件为两个 spark-env.sh和slaves
cd /home/hadoop/spark-2.4.0/conf
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
编辑文件:
vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8
export SCALA_HOME=/home/hadoop/scala-2.12.8
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
SPARK_WORKER_PORT=7078
SPARK_MASTER_PORT=7077
SPARK_WORKER_WEBUI_PORT=8081
SPARK_MASTER_WEBUI_PORT=8080
编辑文件slaves:
vi slaves
#最后面添加
master
saver1
saver2
把spark复制到其他两台从节点上:
scp -r spark-2.4.0 192.168.1.40:/home/hadoop
scp -r spark-2.4.0 192.168.1.50:/home/hadoop
然后分别在两个从节点声明环境变量
export SPARK_HOME=/home/hadoop/spark-2.4.0
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$SCALA_HOME/bin:$SPARK_HOME/bin
安装验证:
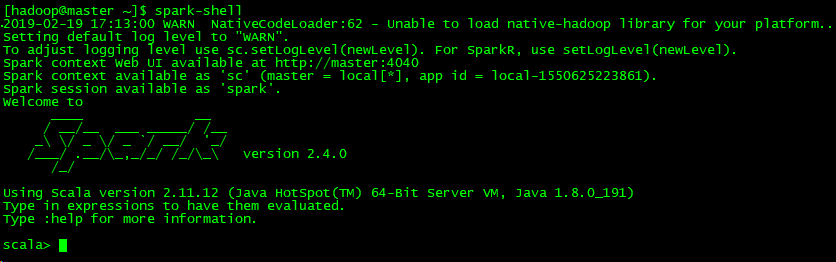
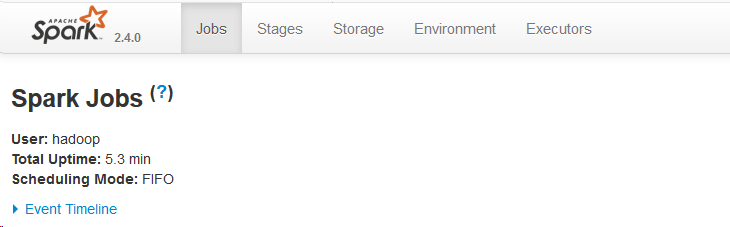
前台网址:http://192.168.1.30:4040
《完》