运行一个Map Reduce job 想查看日志:
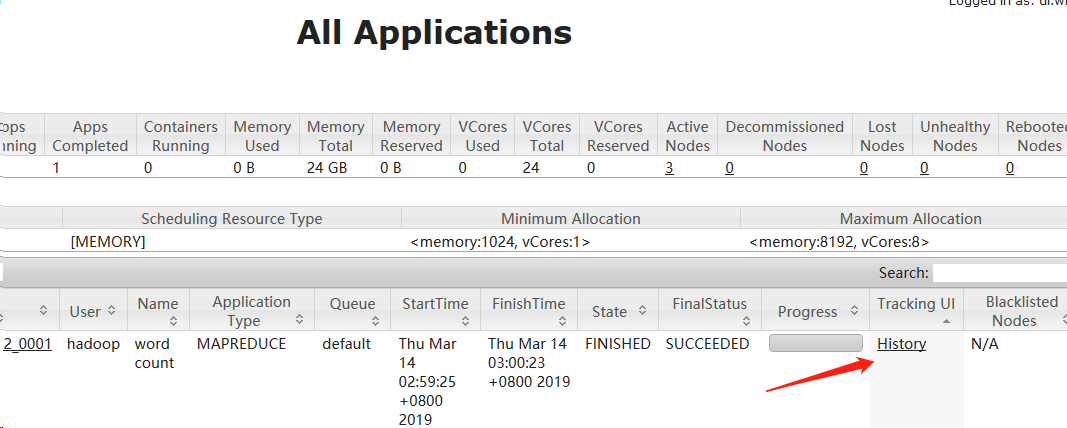
点击History ,找不到网页
解决办法如下:
1.其中有一个进程是需要启动的:
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器
mr-jobhistory-daemon.sh start historyserver
主要是向用户提供历史的mapred Job 查询
2.需要修改配置文件 mapred-site.xml yarn-site.xml
往mapred-site.xml文件添加:
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/mr-history/done</value>
<description>MR JobHistory Server管理的日志的存放位置,默认:/mr-history/done</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/mr-history/mapred/tmp</value>
<description>MapReduce作业产生的日志存放位置,默认值:/mr-history/tmp</description>
</property>
往yarn-site.xml文件中添加:
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
3.配置window 本地的hosts
C:WindowsSystem32driversetchosts
127.0.0.1 localhost 192.168.1.30 master 192.168.1.40 saver1 192.168.1.50 saver2
4.重启集群,使生效
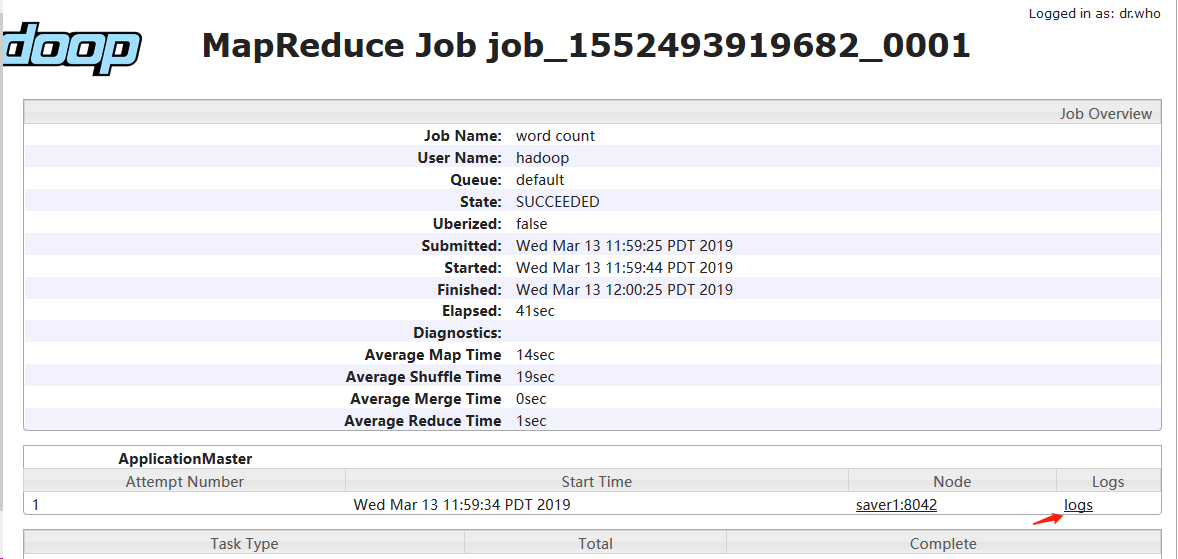
然后再点击logs 可以看到:
