转载自:
https://www.cnblogs.com/pinard/p/6208966.html
http://www.cnblogs.com/pinard/p/6217852.html
https://blog.csdn.net/zhouxianen1987/article/details/68945844
原理+实践
原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
- 流程
输入:数据集D
给定点在邻域内成为核心对象的最小邻域点数:MinPts
邻域半径:Eps
输出:簇集合
计算过程:
(1)DBSCAN通过检查数据集中每点的Eps邻域来搜索簇,如果点p的Eps邻域包含的点多于MinPts个,则创建一个以p为核心对象的簇;
(2)然后,DBSCAN迭代地聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并;
(3)当没有新的点添加到任何簇时,该过程结束。
- 相关概念
DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(Eps, MinPts)用来描述邻域的样本分布紧密程度。其中,Eps描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为Eps的邻域中样本个数的阈值。
假设我的样本集是D=(x1,x2,...,xm),则DBSCAN具体的密度描述定义如下:
- Eps邻域:给定对象半径Eps内的邻域称为该对象的Eps邻域
- 核心点(core point):如果对象的Eps邻域至少包含最小数目MinPts的对象,则称该对象为核心对象
- 边界点(edge point):边界点不是核心点,但落在某个核心点的邻域内
- 噪音点(outlier point):既不是核心点,也不是边界点的任何点
- 密度直达:如果xi位于xj的Eps邻域中,且xj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达, 除非且xi也是核心对象。不满足对称性
- 密度可达:对于xi和xj,如果存在样本样本序列p1,p2,...,pT,满足p1=xi,pT=xj, 且pt+1由pt密度直达,则称xj由xi密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,...,pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出
- 密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的。
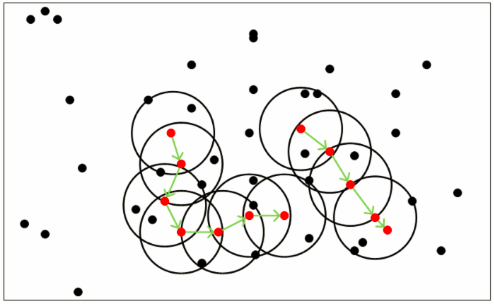
从上图可以很容易看出理解上述定义,图中MinPts=5,红色的点都是核心对象,因为其ϵ-邻域至少有5个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列的Eps邻域内所有的样本相互都是密度相连的。
- 三个问题
- 第一个是一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
- 第二个是距离的度量问题,即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离。这和KNN分类算法的最近邻思想完全相同。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一般采用KD树或者球树来快速的搜索最近邻。
- 第三种问题比较特殊,某些样本可能到两个核心对象的距离都小于ϵ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说BDSCAN的算法不是完全稳定的算法。
- 复杂度
时间复杂度:
(1)DBSCAN的基本时间复杂度是 O(N*找出Eps领域中的点所需要的时间), N是点的个数。最坏情况下时间复杂度是O(N2)
(2)在低维空间数据中,有一些数据结构如KD树,使得可以有效的检索特定点给定距离内的所有点,时间复杂度可以降低到O(NlogN)
空间复杂度:低维和高维数据中,其空间都是O(N),对于每个点它只需要维持少量数据,即簇标号和每个点的标识(核心点或边界点或噪音点)
- 参数选择
Eps:可以使用绘制k-距离曲线(k-distance graph)方法得当,在k-距离曲线图明显拐点位置为对应较好的参数。若参数设置过小,大部分数据不能聚类;若参数设置过大,多个簇和大部分对象会归并到同一个簇中。
K-距离:K距离的定义在DBSCAN算法原文中给出了详细解说,给定K邻域参数k,对于数据中的每个点,计算对应的第k个最近邻域距离,并将数据集所有点对应的最近邻域距离按照降序方式排序,称这幅图为排序的k距离图,选择该图中第一个谷值点位置对应的k距离值设定为Eps。一般将k值设为4。
MinPts:有一个指导性的原则(a rule of thumb),MinPts≥dim+1, 其中dim表示待聚类数据的维度。MinPts设置为1是不合理的,因为设置为1,则每个独立点都是一个簇,MinPts≤2时,与层次距离最近邻域结果相同,因此,MinPts必须选择大于等于3的值。若该值选取过小,则稀疏簇中结果由于密度小于MinPts,从而被认为是边界点儿不被用于在类的进一步扩展;若该值过大,则密度较大的两个邻近簇可能被合并为同一簇。因此,该值是否设置适当会对聚类结果造成较大影响。
- 优缺点
和传统的K-Means算法相比,DBSCAN最大的不同就是不需要输入类别数k,当然它最大的优势是可以发现任意形状的聚类簇,而不是像K-Means,一般仅仅使用于凸的样本集聚类。同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
DBSCAN聚类适用场景:一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐用DBSCAN来聚类。
优点
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
缺点
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
实践