一、master-slave配置
原理:
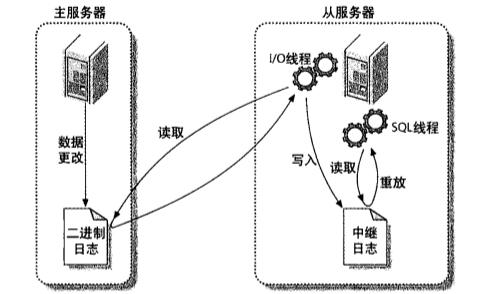
在slave端会有两个线程负责同步工作,一个IO线程,负责将master中的bin log读取过来转换为relay log;另一个是sql线程,根据relay log执行sql语句。
1.主服务器把数据更改记录到二进制日志中。
2.从服务器把主服务器的二进制日志事件拷贝到自己的中继日志(relay log)中.
3.从服务器重放中继日志中的时间,把更改应用到自己的数据上。
原理图:
有关原理的详细说明参见附录A
复制实现级别:
Mysql的复制可以是基于一条语句(Statement level),也可以是基于一条记录(Row level),可以在Mysql的配置参数中设定这个复制级别,不同复制级别的设置会影响到Master端的bin-log记录成不同的形式。
应用:
slave作为master的一个备份,可以处理数据库读取的请求,从而降低主服务器的压力。但是注意slave不能提供写数据库的请求,否则就会导致数据库不一致。
配置步骤:
1. 配置一个服务器作为master
2. 配置一个服务器作为slave
3. 将slave连接到master
下面给出最精简的配置项:
本人将外面的ubuntu配置为master, IP为192.168.10.142,
虚拟机中ubuntu配置为slave, IP为192.168.10.122, 注意虚拟机设置为桥接。
1. 配置master
打开my.cnf,更改其配置如下,省略号表示其他配置
|
[mysqld] ...... server-id=1 log-bin=master-bin log-bin-index=master-bin.index ...... |
log-bin选项给出了二进制日志的所有文件的基本名(master会产生很多logbin日志,比如指定了master-bin的基本名,那么所产生的二进制日志文件的命名会如: master-bin.000001 , master-bin.000002 ……)
log-bin-index选项给出了二进制索引文件的文件名,这个索引文件保存了所有binlog文件的列表。
server-id用来区分不同的主机,所有master和slave的server-id必须不同。
保存my.cnf之后需要重新启动mysql:
|
$ sudo /etc/init.d/mysql restart |
如果不是按照本人文章《ubuntu下mysql安装和配置文件说明》配置的将mysql.server拷贝到了/etc/init.d/mysql ,那么需要cd 到mysql的目录,然后 support-files/mysql.server restart
然后创建一个复制用户, $ mysql -u root 登录之后
|
master>CREATE USER repl1; master>GRANT REPLICATION SLAVE on *.* TO repl1 IDENTIFIED BY '123'; |
REPLICATION SLAVE 权限表示这个用户能够从master上取得二进制日志的转储数据。这里也可以给一个现有的mysql用户赋予该权限以供slave连接,但是,重新创建一个专用于复制的用户更方便,如果以后要禁止某个slave的链接,直接删除该用户即可。
2. 配置slave
打开my.cnf,更改其配置如下,省略号表示其他配置.
|
[mysqld] ...... server-id=2 relay-log-index=slave-relay-bin.index relay-log= slave-relay-bin log-bin=mysql-bin log-bin-index=mysql-bin.index log-slave-updates=1 ...... |
relay-log选项给出了二进制中继日志的所有文件的基本名(slave会产生很多relay-logbin日志,比如指定了slave-relay-bin的基本名,那么所产生的二进制日志文件的命名会如: slave-relay-bin.000001 , slave-relay-bin.000002 ……)
relay-log-index选项给出了二进制索引文件的文件名,这个索引文件保存了所有binlog文件的列表。
server-id为了和master区分,这里设置为2.
保存my.cnf之后需要重新启动mysql。
这里同样开启了binlog是因为二进制日志的作用不仅仅是master将信息传给slave。
slave也同样可以需要binlog来记录它的一些信息,特别是配置级联主从的时候,详见后面部分。
log-slave-updates=1 这个参数详见第二部分的第2点
3.连接master和slave
slave通过change master to命令连接到master需要知道:master的IP,端口,拥有REPLICATION SLAVE 权限的用户名和密码。
在本例中:
在slave机上:
|
$ mysql -u root进入mysql |
|
mysql > CHANGE MASTER TO -> MASTER_HOST='192.168.10.142' , -> MASTER_PORT=3306 , -> MASTER_USER='repl1' , -> MASTER_PASSWORD='123' ; mysql > START SALVE; |
配置到此结束!
4.查看状态及测试
在master端:
|
mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000004 | 106 | | | +------------------+----------+--------------+------------------+ |
这里记录了当前master正在记录的binlog文件和位置,
在slave端:
|
mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.142 Master_User: repl1 Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-bin.000004 Read_Master_Log_Pos: 106 Relay_Log_File: slave-relay-bin.000002 Relay_Log_Pos: 393 Relay_Master_Log_File: master-bin.000004 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 247 Relay_Log_Space: 548 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: |
部分参数解释如下:
Slave_IO_State: Waiting for master to send event #说明当前IO状态
Master_Host: 192.168.10.142
Master_User: repl1
Master_Port: 3306
Connect_Retry: 60 #60秒重连
Master_Log_File: master-bin.000004 #对应的master的binlog文件,目前是从这个binlog获取数据,这个参数和show master status 的结果一致。
Read_Master_Log_Pos: 106 #对应的master的binlog位置,目前是从这个binlog的位置获取数据,这个参数和show master status 的结果一致。
Relay_Log_File: slave-relay-bin.000002 #对应的本地中继日志binlog文件名,目前是这个中继日志来接收master的binlog信息
Relay_Log_Pos: 393 #对应的本地中继日志binlog位置,目前是来接收master的binlog信息已经写到这个位置
Relay_Master_Log_File: master-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: #要复制的数据库
Replicate_Ignore_DB: #不需要复制的数据库
Replicate_Do_Table: #要复制的表
Replicate_Ignore_Table: #不要复制的表
#以上四个参数可以在my.cnf中配置,详见《高可用mysql》第5章 -> 专用slave
我们看一下master端和slave端的线程:
在master端:
|
*************************** 1. row *************************** Id: 2 User: root Host: localhost db: NULL Command: Query Time: 0 State: NULL Info: show processlist *************************** 2. row *************************** Id: 3 User: system user Host: db: NULL Command: Connect Time: 456 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL |
在slave端:
|
mysql> show processlist\G; *************************** 1. row *************************** Id: 2 User: root Host: localhost db: NULL Command: Query Time: 0 State: NULL Info: show processlist *************************** 2. row *************************** Id: 3 User: system user Host: db: NULL Command: Connect Time: 1412 State: Waiting for master to send event Info: NULL |
下面我们来测试一下是否能正确复制
在master 端:
|
mysql > CREATE DATABASE testrepl; |
在slave 端:
|
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | test | | testrepl | +--------------------+ |
发现复制成功了(网速太慢可能要等一会儿,这是因为复制是异步的,参见上面的原理图。当然也可以配置成半同步的:半同步要求在允许master的更改操作继续执行之前,确保更改操作至少被写入了一个slave磁盘,这意味着对于每一个连接,最多有一个事务会由于mysql崩溃而丢失。有关同步复制更多内容参见《高可用mysql》第四章 -> 程序 -> 半同步复制)
下面我们来查看下binlog:
在master端, 如果按照本人文章《ubuntu下mysql安装和配置文件说明》中所配置的binlog路径:/vobiledata/mysqllog
|
$ su - root $ cd /vobiledata/mysqllog $ mysqlbinlog master-bin.000004 |
我们可以找到“create database testrepl;”这句话
|
# at 106 #120809 13:19:47 server id 1 end_log_pos 247 Query thread_id=1 exec_time=0 error_code=0 SET TIMESTAMP=1344489587; create database testrepl ; DELIMITER ; # End of log file |
在slave端:
|
$ su - root $ cd /vobiledata/mysqllog $ mysqlbinlog slave-relay-bin.000002 |
我们同样可以看到“create database testrepl;”这句话. 并且是从位置393开始写的,这和show slave status所显示的“Relay_Log_Pos: 393” 的结果一致。
|
# at 393 #120809 13:19:47 server id 1 end_log_pos 343 Query thread_id=1 exec_time=0 error_code=0 SET TIMESTAMP=1344489587; create database testrepl ; DELIMITER ; # End of log file |
最后,我们可以看下log-slave-updates这个配置选项的作用。
如果开启了这个参数,在slave端:
|
$ mysql -u root mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000004 | 106 | | | +------------------+----------+--------------+------------------+ |
通过这里我们知道要去看mysql-bin.000004
|
$ su - root $ cd /vobiledata/mysqllog $ mysqlbinlog mysql-bin.000004 |
如果slave的my.cnf中设置了log-slave-updates这个参数,那么就会看到“create database testrepl;”这句话,否则不会。这有助于理解后面第三部分的内容,这里暂不解释。
5. 更多设置和线上环境
my.cnf中,和复制相关的一些重要选项
expire_logs_days=7表示二进制日志文件只保留最近7天的,设置了该选项,mysql会自动只保留最近7天的二进制日志。
max_binlog_size=100M表示一个二进制日志文件最大为100M。超过该大小之后会新建一个binlog。
binlog_format详解参见附录B
|
slave-skip-errors=all |
#出现错误后忽略,如果不加这个,出现任何错误,同步进程会终止。自行选择加上或者不加该选项
另外,在实际线上环境,只进行之前几步的操作并不能将master的所有数据复制到slave,只能保证在start slave的那一刻开始,master上的数据会复制到slave。为了完全复制,需要先用mysqldump将master备份到slave。具体可以可以参照附录C。
在dump之前,一般要求: mysql> FLUSH TABLES WITH READ LOCK;
这是为了在导出之前先将缓存写入硬盘,并锁定表。
最后,我们可以将CHANGE MASTER TO后面的一些参数在my.cnf中配置,如:
|
[mysqld] ...... master-host=192.168.10.142 ...... |
二、双master 配置
双master的原理就是无为master和slave,所以只要分别配置为对方的master和slave即可。
但是有几点需要注意:
1.双master互备和主从复制有一些区别,因为多主中都可以对服务器有写权限,所以设计到自增长重复问题
出现的问题(多主自增长ID重复)
1:首先我们通过A,B的test表结构
2:掉A,在B上对数据表test(存在自增长ID)执行插入操作,返回插入ID为1
3:后停掉B,在A上对数据表test(存在自增长ID)执行插入操作,返回的插入ID也是1
4:然后我们同时启动A,B,就会出现主键ID重复
解决方法:
我们只要保证两台服务器上插入的自增长数据不同就可以了
如:A查奇数ID,B插偶数ID,当然如果服务器多的话,你可以定义算法,只要不同就可以了
在这里我们在A,B上加入参数,以实现奇偶插入
在其中一台机子上:my.cnf上加入参数
|
auto_increment_offset = 1 |
这样A的auto_increment字段产生的数值是:1, 3, 5, 7, …等奇数ID了
在另一台机子上:my.cnf上加入参数
|
auto_increment_offset = 2 |
这样B的auto_increment字段产生的数值是:2, 4, 6, 8, …等偶数ID了
可以看出,你的auto_increment字段在不同的服务器之间绝对不会重复,所以Master-Master结构就没有任何问题了。当然,你还可以使用3台,4台,或者N台服务器,只要保证auto_increment_increment = N 再设置一下auto_increment_offset为适当的初始值就可以了,
那样,我们的MySQL可以同时有几十台主服务器,而不会出现自增长ID 重复。
在这里我们说的是2台MYSQL服务器,你也可以扩展到多台,实现方法类似
A -> B -> C-> D ->A
这样一个环形的备份结构就形成了,最后可要记住自增长ID(主键)要设计好哦,否则会出错的,另外需要注意log-slave-updates. 详见下面第2点。
但是尽管如此,也只能适用于只有插入操作的情况,如果两边同时删除某条记录,依然出错。
所以最稳妥的方法是业务拆分,也就是保证两边不会操作相同的表,这需要程序的支持。
有关拆分的详细介绍参见http://developer.51cto.com/art/201007/212944_1.htm和http://kill8108.blog.163.com/blog/static/434199682009616111456433
2. 两边的my.cnf都加上
|
log-slave-updates=1 |
这个选项非常重要。这是为了将中继日志接收到的信息复制到本地的binlog:
Because updates received by a slave from the master are not logged in the binary log unless --log-slave-updates is specified, the binary log on each slave is empty initially.”
————引自http://docs.oracle.com/cd/E17952_01/refman-5.5-en/replication-solutions-switch.html
三、A-B-C级联主从配置
原理依然是基于最普通的master-slave。 首先建立A-B之间的master-slave. 然后建立B-C之间的master-slave. 需要注意的是必须在B的my.cnf配置中加上 log-slave-updates=1.这是为了将中继日志接收到的信息复制到本地的binlog,这样C才能收到更新信息。
有关slave过滤要复制的库和表等更多高级复制话题,详见《高可用mysql》2~6 章。
附录A Mysql的复制原理
Mysql的复制(Replication)是一个异步的复制,从一个Mysql instace(称之为Master)复制到另一个Mysql instance(称之Slave)。实现整个复制操作主要由三个进程完成的,其中两个进程在Slave(Sql进程和IO进程),另外一个进程在 Master(IO进程)上。
要实施复制,首先必须打开Master端的binary log(bin-log)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。
复制的基本过程如下:
1) Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2) Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取制定日志指定位置之后的日志信息,返回给Slave 的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
3) Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”;
4) Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
实际上在老版本的Mysql的复制实现在Slave端并不是两个进程完成的,而是由一个进程完成。但是后来发现这样做存在较大的风险和性能问题,主要如下:
首先,一个进程就使复制bin-log日志和解析日志并在自身执行的过程成为一个串行的过程,性能受到了一定的限制,异步复制的延迟也会比较长。
另外,Slave端从Master端获取bin-log过来之后,需要接着解析日志内容,然后在自身执行。在这个过程中,Master端可能又产生了大量变化并声称了大量的日志。如果在这个阶段Master端的存储出现了无法修复的错误,那么在这个阶段所产生的所有变更都将永远无法找回。如果在Slave 端的压力比较大的时候,这个过程的时间可能会比较长。
所以,后面版本的Mysql为了解决这个风险并提高复制的性能,将Slave端的复制改为两个进程来完成。提出这个改进方案的人是Yahoo!的一位工程 师“Jeremy Zawodny”。这样既解决了性能问题,又缩短了异步的延时时间,同时也减少了可能存在的数据丢失量。当然,即使是换成了现在这样两个线程处理以后,同样也还是存在slave数据延时以及数据丢失的可能性的,毕竟这个复制是异步的。只要数据的更改不是在一个事物中,这些问题都是会存在的。如果要完全避免这些问题,就只能用mysql的cluster来解决了。不过mysql的cluster是内存数据库的解决方案,需要将所有数据都load到内存中,这样就对内存的要求就非常大了,对于一般的应用来说可实施性不是太大。
附录B:复制的级别和配置选项
Row Level:日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
优点:
在row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以row level的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或function,以及 trigger的调用和触发无法被正确复制的问题。
缺点:
row level下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如有这样一条update语句:update product set owner_member_id = ‘b’ where owner_member_id = ‘a’,执行之后,日志中记录的不是这条update语句所对应额事件(mysql以事件的形式来记录bin-log日志),而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然,bin-log日志的量就会很大。尤其是当执行alter table之类的语句的时候,产生的日志量是惊人的。因为Mysql对于alter table之类的表结构变更语句的处理方式是整个表的每一条记录都需要变动,实际上就是重建了整个表。那么该表的每一条记录都会被记录到日志中。
Statement Level:每一条会修改数据的sql都会记录到 master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行。
优点:
statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约IO,提高性能。因为他只需要记录在Master上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:
由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端杯执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于Mysql现在发展比较快,很多的新功能不断的加入,使mysql得复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement level下,目前已经发现的就有不少情况会造成mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能真确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行来记录的变化,所以不会出现类似的问题。
从官方文档中看到,之前的Mysql一直都只有基于statement的复制模式,直到5.1.5版本的Mysql才开始支持row level的复制。从5.0开始,Mysql的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给Mysql的复制又带来了更大的新挑战。另外,看到官方文档说,从5.1.8版本开始,Mysql提供了除Statement Level和Row Level之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。
在Mixed模式下,Mysql会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。新版本中的Statment level还是和以前一样,仅仅记录执行的语句。而新版本的Mysql中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
有关binlog三种模式的区别(row,statement,mixed), 下面引用 xue_binbin的文章说明:
binlog模式分三种(row,statement,mixed) 1.Row 日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改,只记录要修改的数据,只有value,不会有sql多表关联的情况。 优点:在row模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了,所以row 的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程和function,以及trigger的调用 和出发无法被正确复制问题。缺点:在row模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
mysql> insert into username(username) select * from aa; ERROR 1146 (42S02): Table 'test.username' doesn't exist mysql> insert into user(username) select * from aa; Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0
查看binlog
root@xuebinbin:/vobiledata/mysqllog# mysqlbinlog mysql-bin.000017
BINLOG ' 63EfUBNQAAAALgAAAA8CAAAA
由此可见,row模式是针对每一行的数据,而于关联表无关,它把关联中的相应数据记录在log中。这样一来会产生大量的数据。
2.statement 每一条会修改数据的sql都会记录到master的binlog中,slave在复制的时候sql进程会解析成和原来master端执行多相同的sql再 执行。 有点:在statement模式下首先就是解决了row模式的缺点,不需要记录每一行数据的变化减少了binlog日志量,节省了I/O以及存储资源,提高性能。因为他只需要激励在master上所执行的语句的细节一届执行语句时候的上下的信息。缺点:在statement模式下,由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端被执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于mysql现在发展比较快,很多的新功能不断的加入,使mysql的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在 statement中,目前已经发现不少情况会造成Mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能被正确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得 到不一致的id等等。由于row是基于每一行来记录的变化,所以不会出现,类似的问题。
mysql> insert into user(username) values('xuebinbin'); ERROR 1598 (HY000): Binary logging not possible. Message: Transaction level 'READ-COMMITTED' in InnoDB is not safe for binlog mode 'STATEMENT' mysql> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
-> ;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into user(username) values('xuebinbin'); Query OK, 1 row affected (0.00 sec)
查看binlog root@xuebinbin:/vobiledata/mysqllog# mysqlbinlog mysql-bin.000008
BEGIN ; # at 174 #120806 14:47:35 server id 80 end_log_pos 202 Intvar SET INSERT_ID=2; # at 202 #120806 14:47:35 server id 80 end_log_pos 311 Query thread_id=5 exec_time=0 error_code=0 use test; SET TIMESTAMP=1344235655; insert into user(username) values('xuebinbin') ; # at 311 #120806 14:47:35 server id 80 end_log_pos 338 Xid = 20 COMMIT; # at 338 #120806 14:53:18 server id 80 end_log_pos 357 Stop DELIMITER ; # End of log file ROLLBACK ; ;
结果发现statement是以sql记录形式记录的。这样的话一个sql就只记录一条,减少了大量的数据存储。
3.Mixed 从官方文档中看到,之前的 MySQL 一直都只有基于 statement 的复制模式,直到 5.1.5 版本的 MySQL 才开始支持 row 复制。从 5.0 开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL Replication 又带来了更大的新挑战。另外,看到官方文档说,从 5.1.8 版本开始,MySQL 提供了除 Statement 和 Row 之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在 Mixed 模式下,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。新版本中的 statment 还是和以前一样,仅仅记录执行的语句。而新版本的 MySQL 中对 row 模式也被做了优化,并不是所有的修改都会以 row 模式来记录,比如遇到表结构变更的时候就会以 statement 模式来记录,如果 SQL 语句确实就是 update 或者 delete 等修改数据的语句,那么还是会记录所有行的变更。
附录C:自动配置slave的python脚本
第一次写DBA脚本,就当练手,python还是挺简练的。期间发现mysql的命令source不被MySQLdb支持,详见:
http://stackoverflow.com/questions/1932298/cant-get-mysql-source-query-to-work-using-python-mysqldb-modul
那里也给出了解决方案,详见我的代码。
不过后来发现source可以跟在mysql的命令后面,也就是直接调用terminal命令即可,于是简化为代码中的方案二。
流程如下:先远程导出master的.sql,然后stop slave,reset slave,change master to
然后导入.sql, 最后start slave.
脚本在slave端运行,因为要求远程连接master进行锁表和解锁,所以要求master需要分配slave机mysql用户权限。
///////////////////////////以下是代码/////////////////////////////////////////
|
#coding=utf-8 try: connection2 = MySQLdb.connect(user="root",passwd="",host="192.168.10.142",charset='utf8') #将master缓存中数据写入硬盘并锁表 #远程获得master的.sql sqlstr="ublock tables;" |