官网配置地址:
ResourceManager HA : http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
安装jdk
关闭防火墙
hadoop自动HA借助于zookeeper实现,整体架构如下:
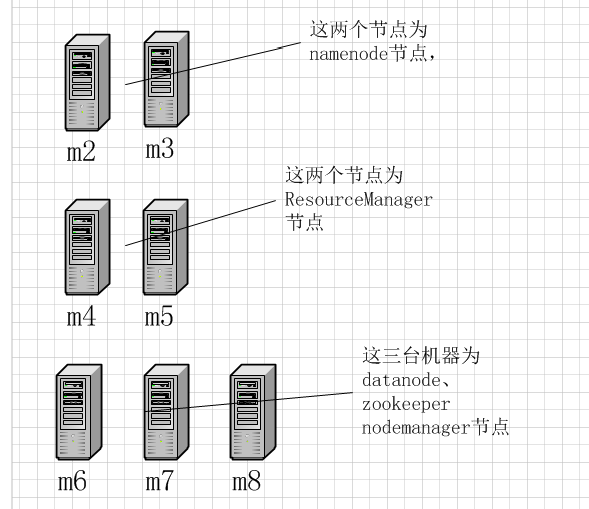
m2和m3作为NameNode节点应该配置与其他所有节点的SSH无密码登录
m4和m5应该与m6、m7、m8配置SSH无密码登录
core-site.xml具体配置
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://cluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/app/hadoop-2.7.3/tmp/data</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>m6:2181,m7:2181,m8:2181</value> </property> </configuration>
hdfs-site.xml具体配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>m2:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>m3:9820</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>m2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>m3:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://m6:8485;m7:8485;m8:8485;/cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(shell(/bin/true))
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/journalnode/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
yarn-site.xml具体配置
<?xml version="1.0"?> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>m4</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>m5</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>m4:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>m5:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>m6:2181,m7:2181,m8:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml具体配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves具体配置
m6 m7 m8
拷贝hadoop到m3、m4、m5、m6、m7、m8
scp -r hadoop-2.7.3/ m3:/home/hadoop/app/ scp -r hadoop-2.7.3/ m4:/home/hadoop/app/ scp -r hadoop-2.7.3/ m5:/home/hadoop/app/ scp -r hadoop-2.7.3/ m6:/home/hadoop/app/ scp -r hadoop-2.7.3/ m7:/home/hadoop/app/ scp -r hadoop-2.7.3/ m8:/home/hadoop/app/
zookeeper配置zoo.cfg(m6 m7 m8)
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. dataDir=/home/hadoop/app/zookeeper-3.3.6/data # the port at which the clients will connect clientPort=2181 server.1=m6:2888:3888 server.2=m7:2888:3888 server.3=m8:2888:3888
配置好后的启动顺序:
1、启动zookeeper ./bin/zkServer.sh start
2、分别在m6 m7 m8上启动journalnode, ./hadoop-daemon.sh start journalnode只有第一次才需要手动启动journalnode,以后启动hdfs的时候会自动启动journalnode
3、在m2上格式化namenode,格式化成功后拷贝元数据到m3节点上
4、格式化zkfc ./bin/hdfs zkfc -formatZK 只需要一次
5、启动hdfs
6、启动yarn
验证:
通过kill命令杀死namenode进程观察namenode节点是否会自动切换
yarn rmadmin -getServiceState rm1查看那个resourceManager是active那个是standby
单独启动namenode: ./sbin/hadoop-daemon.sh start namenode