什么是spark SQL
spark SQL是spark处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame,并作为分布式SQL查询引擎来使用。
spark SQL和 hive SQL
hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的复杂度,但是由于MapReduce比较慢,所以spark SQL应运而生。spark SQL将转换为RDD提交到spark集群进行运行,因此,执行效率非常的快。
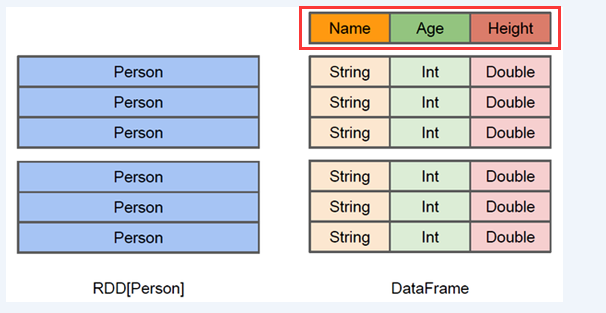
DataFrame
与RDD类似,DataFrame也是一个分布式数据集,然而DataFrame更像传统关系性数据库的二维表。除了记录数据还记录了数据的结构信息,即schema。同时,与hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从api的易用角度来看,DataFrame api提供的是一套高层次的操作,比函数式的RDD api更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame 很好地继承了传统单机数据分析的开发体验。