前言:本实验采用自上而下的方法实现算术表达式的语法分析器。只是实现了对加减乘数和带括号的语法分析,判断语法的正确性。
一 实验要求:
(1)程序通过标准输入按行读取用户输入,表达式在1行内读完。
(2)程序对用户输入的内容首先进行词法分析处理(可以复用实验一的部分代码,由于词法规则更简单,可以大大简化),词法分析得到的词法单位对应文法中的终结符。//代码太长直接就用词法分析的结果进行语法分析。
(3)对于用户输入的表达式,如果经过分析后语法正确,给出相应提示。如果分析过程中遇到错误不需要尝试恢复分析,停止该次分析过程即可,但应尽量给出说明性较强的错误提示。
下面给出一些验证语法分析结果正确性的测试用例:
正确:a+3*( b + c/10) -4 +5 错误:a+3 ( b + c/10) 错误:(1+2)(3-4) 错误:(1+2
二:假设词法分析已经正确的完成,只进行语法分析
比如以 a+3*( b + c/10) -4 +5为例,进行词法分析后得到的结果为
1 (29,a) 2 (12,+) 3 (28,3) 4 (14,*) 5 (21,() 6 (29,b) 7 (12,+) 8 (29,c) 9 (15,/) 10 (28,10) 11 (22,)) 12 (13,-) 13 (28,4) 14 (12,+) 15 (28,5)
注意,上面的结果第一个参数是种别码,种别码的声明如下(关于词法分析的过程可具体参考我之前写的词法分析 https://www.cnblogs.com/henuliulei/p/10597281.html),当然种别码可以自己声明。


1 begin 1 2 end 2 3 if 3 4 then 4 5 while 5 6 do 6 7 const 7 8 var 8 9 call 9 10 procedure 10 11 odd 11 12 + 12 13 - 13 14 * 14 15 / 15 16 = 16 17 # 17 18 < 18 19 > 19 20 := 20 21 ( 21 22 ) 22 23 , 23 24 . 24 25 ; 25 26 (*多行注释*) 26 27 //单行注释 27 28 常数 28 29 标识符 29
输入:
以上面的结果作为输入
输出:
对于语法正确的表达式,报告“正确:“+”表达式”;
对于语法错误的表达式,报告“语法错误”, 指出错误原因
设计思想
递归下降分析法的原理是利用函数之间的递归调用来模拟语法树自上而下的构建过程。从根节点出发,自顶向下为输入串中寻找一个最左匹配序列,建立一棵语法树。在不含左递归和每个非终结符的所有候选终结首字符集都两两不相交条件下,我们就可能构造出一个不带回溯的自顶向下的分析程 序,这个分析程序是由一组递归过程(或函数)组成的,每个过程(或函数)对应文法的而一个非终结符。
代码:
1 #include<bits/stdc++.h> 2 using namespace std; 3 ifstream infile("D:/Test/Test1.txt"); 4 string str;//string变量进行字符识别 5 string sym; //指针 6 7 void expressionAnalysis();//表达式分析 8 void termAnaysis();//项分析 9 void factorAnalysis();//因子分析 10 int advance(); 11 12 int conterr=0;//记录错误 13 int lpnum=0;//记录左括号 14 int found;//提取字符串中指针的位置 15 int flag=0;//记录往后移动一个指针SYM是否正确 16 17 int advance(){//SYM的移动 18 if(!getline(infile,str)){//从文件中提取字符 19 return 0; 20 } 21 found=str.find(',',0); 22 if(found==-1){//当为error的时候,没有‘,’ 23 conterr++; 24 cout<<"语法错误 识别字符错误"<<endl; 25 return -1; 26 } 27 sym=str.substr(1,found-1); 28 //cout<<sym<<endl; 29 return 1; 30 } 31 32 void factorAnalysis(){//识别分析标识符 33 if(sym=="29"||sym=="28"){//如果是标识符和无符号整数,指针就往后移动 34 flag=advance(); 35 if(conterr){ 36 return; 37 } 38 if(lpnum==0&&sym=="22"){// 39 conterr++; 40 cout<<"语法错误 ')'不匹配"<<endl; 41 return; 42 } 43 } 44 else if(sym=="21"){//如果是左括号,就要接下来判断是否为表达式,指针往后移动 45 lpnum++; 46 // cout<<lpnum<<endl; 47 flag=advance(); 48 if(conterr){ 49 return; 50 } 51 if(flag==0){//当为最后一个标志的时候,若没有右括号匹配就错误 52 conterr++; 53 cout<<"语法错误 '('后缺少表达式"<<endl; 54 return; 55 } 56 expressionAnalysis(); 57 if(conterr){ 58 return; 59 } 60 if(flag==0||sym!="22"){ 61 conterr++; 62 cout<<"语法错误 表达式后面缺少')'"<<endl; 63 return; 64 }else{ 65 lpnum--; 66 flag=advance(); 67 if(conterr){ 68 return; 69 } 70 if(flag==0){ 71 return; 72 } 73 } 74 }else{ 75 cout<<"语法错误 因子首部不为<标识符>|| <无符号整数> ||'('"<<endl; 76 conterr++; 77 return; 78 } 79 return; 80 } 81 82 void termAnalysis(){//识别分析乘除符号 83 factorAnalysis(); 84 if(conterr){ 85 return; 86 } 87 while((sym=="14")||(sym=="15")){//当为'*'或'/'的时候,一直往后识别因子并循环 88 flag=advance(); 89 if(conterr){ 90 return; 91 } 92 if(flag==0){ 93 conterr++; 94 cout<<"语法错误 <乘除法运算符>后缺因子"<<endl; 95 return; 96 } 97 if(conterr){ 98 return; 99 } 100 factorAnalysis(); 101 if(conterr){ 102 return; 103 } 104 } 105 return; 106 }; 107 108 void expressionAnalysis(){//识别分析加减符号 109 if(conterr){ 110 return; 111 } 112 if((sym=="12")||(sym=="13")){//当为'+'或'-'的时候 113 flag=advance(); 114 if(!conterr){ 115 return; 116 } 117 if(flag==0){ 118 cout<<"语法错误 <加减法运算符>后缺项"<<endl; 119 conterr++; 120 return; 121 } 122 } 123 termAnalysis(); 124 if(conterr){ 125 return; 126 } 127 while((sym=="12")||(sym=="13")){//当为'+'或'-'的时候,一直往后识别项并循环 128 flag=advance(); 129 if(conterr){ 130 return; 131 } 132 if(flag==0){ 133 cout<<"语法错误 <加法运算符>后缺项"<<endl; 134 conterr++; 135 return; 136 } 137 termAnalysis(); 138 if(conterr){ 139 return; 140 } 141 } 142 return; 143 } 144 145 int main(){ 146 flag=advance(); 147 if(flag){ 148 expressionAnalysis(); 149 } 150 if(flag!=-1&&!conterr){ 151 cout<<"语法正确"<<endl; 152 } 153 return 0; 154 }
3:代码中先进行词法分析,再把词法分析的结果作为输入进行语法分析
本代码里的路径D:/Test/b.txt对应文件里放的是要词法分析的表达式,D:/Test/a.txt放的是种别码,程序会把词法分析的结果放到D:/Test/c.txt里面,再读到程序里面进行语法分析,把结果显示在屏幕上,代码里是上面的语法分析和之前写的词法分析的结合。
1 // pL/0语言词法分析器 2 #include<bits/stdc++.h> 3 using namespace std; 4 5 ifstream infile("D:/Test/c.txt");//词法分析的结果或语法分析的输入 6 string str;//string变量进行字符识别 7 string sym; //指针 8 9 void expressionAnalysis();//表达式分析 10 void termAnaysis();//项分析 11 void factorAnalysis();//因子分析 12 int advance(); 13 14 int conterr=0;//记录错误 15 int lpnum=0;//记录左括号 16 int found;//提取字符串中指针的位置 17 int flag=0;//记录往后移动一个指针SYM是否正确 18 string s;//用来保存要分析的字符串 19 struct _2tup 20 { 21 string token; 22 int id; 23 }; 24 25 int advance(){//SYM的移动 26 if(!getline(infile,str)){//从文件中提取字符 27 return 0; 28 } 29 found=str.find(',',0); 30 if(found==-1){//当为error的时候,没有‘,’ 31 conterr++; 32 cout<<"语法错误 识别字符错误"<<endl; 33 return -1; 34 } 35 sym=str.substr(1,found-1); 36 //cout<<sym<<endl; 37 return 1; 38 } 39 40 void factorAnalysis(){//识别分析标识符 41 if(sym=="29"||sym=="28"){//如果是标识符和无符号整数,指针就往后移动 42 flag=advance(); 43 if(conterr){ 44 return; 45 } 46 if(lpnum==0&&sym=="22"){// 47 conterr++; 48 cout<<"语法错误 ')'不匹配"<<endl; 49 return; 50 } 51 } 52 else if(sym=="21"){//如果是左括号,就要接下来判断是否为表达式,指针往后移动 53 lpnum++; 54 // cout<<lpnum<<endl; 55 flag=advance(); 56 if(conterr){ 57 return; 58 } 59 if(flag==0){//当为最后一个标志的时候,若没有右括号匹配就错误 60 conterr++; 61 cout<<"语法错误 '('后缺少表达式"<<endl; 62 return; 63 } 64 expressionAnalysis(); 65 if(conterr){ 66 return; 67 } 68 if(flag==0||sym!="22"){ 69 conterr++; 70 cout<<"语法错误 表达式后面缺少')'"<<endl; 71 return; 72 }else{ 73 lpnum--; 74 flag=advance(); 75 if(conterr){ 76 return; 77 } 78 if(flag==0){ 79 return; 80 } 81 } 82 }else{ 83 cout<<"语法错误 因子首部不为<标识符>|| <无符号整数> ||'('"<<endl; 84 conterr++; 85 return; 86 } 87 return; 88 } 89 90 void termAnalysis(){//识别分析乘除符号 91 factorAnalysis(); 92 if(conterr){ 93 return; 94 } 95 while((sym=="14")||(sym=="15")){//当为'*'或'/'的时候,一直往后识别因子并循环 96 flag=advance(); 97 if(conterr){ 98 return; 99 } 100 if(flag==0){ 101 conterr++; 102 cout<<"语法错误 <乘除法运算符>后缺因子"<<endl; 103 return; 104 } 105 if(conterr){ 106 return; 107 } 108 factorAnalysis(); 109 if(conterr){ 110 return; 111 } 112 } 113 return; 114 }; 115 116 void expressionAnalysis(){//识别分析加减符号 117 if(conterr){ 118 return; 119 } 120 if((sym=="12")||(sym=="13")){//当为'+'或'-'的时候 121 flag=advance(); 122 if(!conterr){ 123 return; 124 } 125 if(flag==0){ 126 cout<<"语法错误 <加减法运算符>后缺项"<<endl; 127 conterr++; 128 return; 129 } 130 } 131 termAnalysis(); 132 if(conterr){ 133 return; 134 } 135 while((sym=="12")||(sym=="13")){//当为'+'或'-'的时候,一直往后识别项并循环 136 flag=advance(); 137 if(conterr){ 138 return; 139 } 140 if(flag==0){ 141 cout<<"语法错误 <加法运算符>后缺项"<<endl; 142 conterr++; 143 return; 144 } 145 termAnalysis(); 146 if(conterr){ 147 return; 148 } 149 } 150 return; 151 } 152 153 bool is_blank(char ch) 154 { 155 return ch == ' ' || ch == ' ';//空格或控制字符 156 } 157 bool gofor(char& ch, string::size_type& pos, const string& prog)//返回指定位置的字符 158 { 159 ++pos; 160 if (pos >= prog.size()) 161 { 162 return false; 163 } 164 else 165 { 166 ch = prog[pos]; 167 return true; 168 } 169 } 170 171 _2tup scanner(const string& prog, string::size_type& pos, const map<string, int>& keys, int& row) 172 { 173 /* 174 if 175 标示符 176 else if 177 数字 178 else 179 符号 180 */ 181 _2tup ret; 182 string token; 183 int id = 0; 184 185 char ch; 186 ch = prog[pos]; 187 188 while(is_blank(ch)) 189 { 190 ++pos; 191 ch = prog[pos]; 192 } 193 // 判断标示符、关键字 194 if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || ch == '_') 195 { 196 //保证读取一个单词 197 while((ch >= '0' && ch <= '9') || (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || ch == '_') 198 { 199 token += ch;//追加标示符、关键字 200 if (!gofor(ch, pos, prog)) 201 { 202 break; 203 } 204 } 205 // 这里先看做都是其他标示符 206 id = keys.size(); 207 208 // 验证是否是关键字 209 map<string, int>::const_iterator cit = keys.find(token);//根据string类型的token返回int类型的id赋值给cit 210 if (cit != keys.end()) 211 { 212 id = cit->second;//此时是关键字,记录他的id 213 } 214 } 215 // 识别常数 216 else if ((ch >= '0' && ch <= '9') || ch == '.') 217 { 218 while (ch >= '0' && ch <= '9' || ch == '.') 219 { 220 token += ch; 221 if (!gofor(ch, pos, prog)) 222 { 223 break; 224 } 225 } 226 id = keys.size() - 1; 227 int dot_num = 0; 228 for (string::size_type i = 0; i != token.size(); ++i) 229 { 230 if (token[i] == '.') 231 { 232 ++dot_num; 233 } 234 } 235 if (dot_num > 1) 236 { 237 id = -1; 238 } 239 } 240 else 241 { 242 map<string, int>::const_iterator cit; 243 switch (ch) 244 { 245 case '-': // - 操作符 246 token += ch; 247 if (gofor(ch, pos, prog)) 248 { 249 if (ch == '-' || ch == '=' || ch == '>') // -- 操作符 250 { 251 token += ch; 252 gofor(ch, pos, prog); 253 } 254 } 255 cit = keys.find(token); 256 if (cit != keys.end()) 257 { 258 id = cit->second; 259 } 260 break; 261 case ':': 262 token += ch; 263 if (gofor(ch, pos, prog)) 264 { 265 if (ch == '=') // -- 操作符 266 { 267 token += ch; 268 gofor(ch, pos, prog); 269 } 270 } 271 cit = keys.find(token); 272 if (cit != keys.end()) 273 { 274 id = cit->second; 275 } 276 break; 277 278 case '=': 279 token += ch; 280 if (gofor(ch, pos, prog)) 281 { 282 if (ch == '=') // !% %= 操作符 283 { 284 token += ch; 285 gofor(ch, pos, prog); 286 } 287 } 288 cit = keys.find(token); 289 if (cit != keys.end()) 290 { 291 id = cit->second; 292 } 293 break; 294 295 case '/': // / 操作符 296 token += ch; 297 if (gofor(ch, pos, prog)) 298 { 299 if (ch == '=') // /= 操作符 300 { 301 token += ch; 302 gofor(ch, pos, prog); 303 } 304 else if (ch == '/') // 单行注释 305 { 306 token += ch; 307 ++pos; 308 while (pos < prog.size()) 309 { 310 ch = prog[pos]; 311 if (ch == ' ') 312 { 313 break; 314 } 315 token += ch; 316 ++pos; 317 } 318 if (pos >= prog.size()) 319 { 320 ; 321 } 322 else 323 { 324 ; 325 } 326 id = keys.size() - 2; 327 break; 328 } 329 else if (ch == '*') // 注释 330 { 331 token += ch; 332 if (!gofor(ch, pos, prog)) 333 { 334 token += " !!!注释错误!!!"; 335 id = -10; 336 break; 337 } 338 if (pos + 1 >= prog.size()) 339 { 340 token += ch; 341 token += " !!!注释错误!!!"; 342 id = -10; 343 break; 344 } 345 char xh = prog[pos + 1]; 346 while (ch != '*' || xh != '/') 347 { 348 token += ch; 349 if (ch == ' ') 350 { 351 ++row; 352 } 353 //++pos; 354 if (!gofor(ch, pos, prog)) 355 { 356 token += " !!!注释错误!!!"; 357 id = -10; 358 ret.token = token; 359 ret.id = id; 360 return ret; 361 } 362 //ch = prog[pos]; 363 if (pos + 1 >= prog.size()) 364 { 365 token += ch; 366 token += " !!!注释错误!!!"; 367 id = -10; 368 ret.token = token; 369 ret.id = id; 370 return ret; 371 } 372 xh = prog[pos + 1]; 373 } 374 token += ch; 375 token += xh; 376 pos += 2; 377 ch = prog[pos]; 378 id = keys.size() - 2; 379 break; 380 } 381 } 382 cit = keys.find(token); 383 if (cit != keys.end()) 384 { 385 id = cit->second; 386 } 387 break; 388 case '+': 389 token += ch; 390 cit = keys.find(token); 391 if (cit != keys.end()) 392 { 393 id = cit->second; 394 } 395 gofor(ch, pos, prog); 396 break; 397 398 case '<': 399 token += ch; 400 if (gofor(ch, pos, prog)) 401 { 402 if (ch == '<') 403 { 404 token += ch; 405 if (gofor(ch, pos, prog)) 406 { 407 if (ch == '=') 408 { 409 token += ch; 410 gofor(ch, pos, prog); 411 } 412 } 413 } 414 else if (ch == '=') 415 { 416 token += ch; 417 gofor(ch, pos, prog); 418 } 419 } 420 cit = keys.find(token); 421 if (cit != keys.end()) 422 { 423 id = cit->second; 424 } 425 break; 426 427 case '>': 428 token += ch; 429 if (gofor(ch, pos, prog)) 430 { 431 if (ch == '>') 432 { 433 token += ch; 434 if (gofor(ch, pos, prog)) 435 { 436 if (ch == '=') 437 { 438 token += ch; 439 gofor(ch, pos, prog); 440 } 441 } 442 } 443 else if (ch == '=') 444 { 445 token += ch; 446 gofor(ch, pos, prog); 447 } 448 } 449 cit = keys.find(token); 450 if (cit != keys.end()) 451 { 452 id = cit->second; 453 } 454 break; 455 case '(': // / 操作符 456 token += ch; 457 if (gofor(ch, pos, prog)) 458 459 { 460 if (ch == '*') // 注释 461 { 462 token += ch; 463 if (!gofor(ch, pos, prog)) 464 { 465 token += " !!!注释错误!!!"; 466 id = -10; 467 break; 468 } 469 if (pos + 1 >= prog.size()) 470 { 471 token += ch; 472 token += " !!!注释错误!!!"; 473 id = -10; 474 break; 475 } 476 char xh = prog[pos + 1]; 477 while (ch != '*' || xh != ')') 478 { 479 token += ch; 480 if (ch == ' ') 481 { 482 ++row; 483 } 484 //++pos; 485 if (!gofor(ch, pos, prog)) 486 { 487 token += " !!!注释错误!!!"; 488 id = -10; 489 ret.token = token; 490 ret.id = id; 491 return ret; 492 } 493 //ch = prog[pos]; 494 if (pos + 1 >= prog.size()) 495 { 496 token += ch; 497 token += " !!!注释错误!!!"; 498 id = -10; 499 ret.token = token; 500 ret.id = id; 501 return ret; 502 } 503 xh = prog[pos + 1]; 504 } 505 token += ch; 506 token += xh; 507 pos += 2; 508 ch = prog[pos]; 509 id = keys.size() - 2; 510 break; 511 } 512 } 513 cit = keys.find(token); 514 if (cit != keys.end()) 515 { 516 id = cit->second; 517 } 518 break; 519 520 case '*': 521 token += ch; 522 cit = keys.find(token); 523 if (cit != keys.end()) 524 { 525 id = cit->second; 526 } 527 gofor(ch, pos, prog); 528 break; 529 530 case ',': 531 case ')': 532 case '#': 533 case '.': 534 case ';': 535 token += ch; 536 gofor(ch, pos, prog); 537 //++pos; 538 //ch = prog[pos]; 539 cit = keys.find(token); 540 if (cit != keys.end()) 541 { 542 id = cit->second; 543 } 544 break; 545 546 case ' ': 547 token += "换行"; 548 ++pos; 549 ch = prog[pos]; 550 id = -2; 551 break; 552 default: 553 token += "错误"; 554 ++pos; 555 ch = prog[pos]; 556 id = -1; 557 break; 558 } 559 } 560 ret.token = token; 561 ret.id = id; 562 563 return ret; 564 } 565 566 void init_keys(const string& file, map<string, int>& keys)//读取单词符号和种别码 567 { 568 ifstream fin(file.c_str());//.c_str返回的是当前字符串的首地址 569 if (!fin) 570 { 571 cerr << file << " doesn't exist!" << endl;//cerr不经过缓冲而直接输出,一般用于迅速输出出错信息 572 // exit(1); 573 } 574 keys.clear();//清空map对象里面的内容 575 string line; 576 string key; 577 int id; 578 while (getline(fin, line))//这个函数接收两个参数:一个输入流对象和一个string对象,getline函数从输入流的下一行读取,并保存读取的内容到string中 579 { 580 istringstream sin(line);//istringstream sin(s);定义一个字符串输入流的对象sin,并调用sin的复制构造函数,将line中所包含的字符串放入sin 对象中! 581 sin >> key >> id;//读取里面的字符串每一行一个key id 582 keys[key] = id; 583 } 584 } 585 586 void read_prog(const string& file, string& prog){//读取代码,并追加到prog上 587 ifstream fin(file.c_str()); 588 if (!fin) 589 { 590 cerr << file << " error!" << endl; 591 // exit(2); 592 } 593 prog.clear(); 594 string line; 595 while (getline(fin, line)) 596 { 597 prog += line + ' '; 598 } 599 } 600 601 void cifafenxi() 602 { 603 map<string, int> keys; 604 init_keys("D:/Test/a.txt", keys); 605 606 string prog; 607 read_prog("D:/Test/b.txt", prog); 608 609 vector< _2tup > tups; 610 string token, id; 611 612 string::size_type pos = 0;//size_type属于string标准库,作用可看做相当于unsigned·int 613 int row = 1; 614 615 _2tup tu; 616 int no = 0; 617 freopen("D:/Test/c.txt","w",stdout); 618 do 619 { 620 tu = scanner(prog, pos, keys, row); 621 622 switch (tu.id) 623 { 624 case -1://返回的是错误 625 ++no; 626 cout << no << ": "; 627 cout << "Error in row" << row << "!" << '<' << tu.token<< "," << tu.id << '>' << endl; 628 tups.push_back(tu); 629 break; 630 case -2: 631 ++row; 632 // cout << '<' << tu.token<< "," << tu.id << '>' << endl; 633 break; 634 default: 635 636 s=prog; 637 cout << '(' << tu.id<< "," << tu.token << ')' << endl; 638 639 tups.push_back(tu); 640 break; 641 } 642 } while (pos < prog.size()); 643 644 } 645 646 yufafenxi()//语法分析 647 { 648 freopen("CON", "w", stdout);//结果在控制台上输出 649 flag=advance(); 650 if(flag){ 651 expressionAnalysis(); 652 } 653 if(flag!=-1&&!conterr){ 654 cout<<"正确:"<<s<<endl; 655 } 656 657 } 658 int main() 659 { 660 cifafenxi(); 661 yufafenxi(); 662 return 0; 663 }
效果如下:
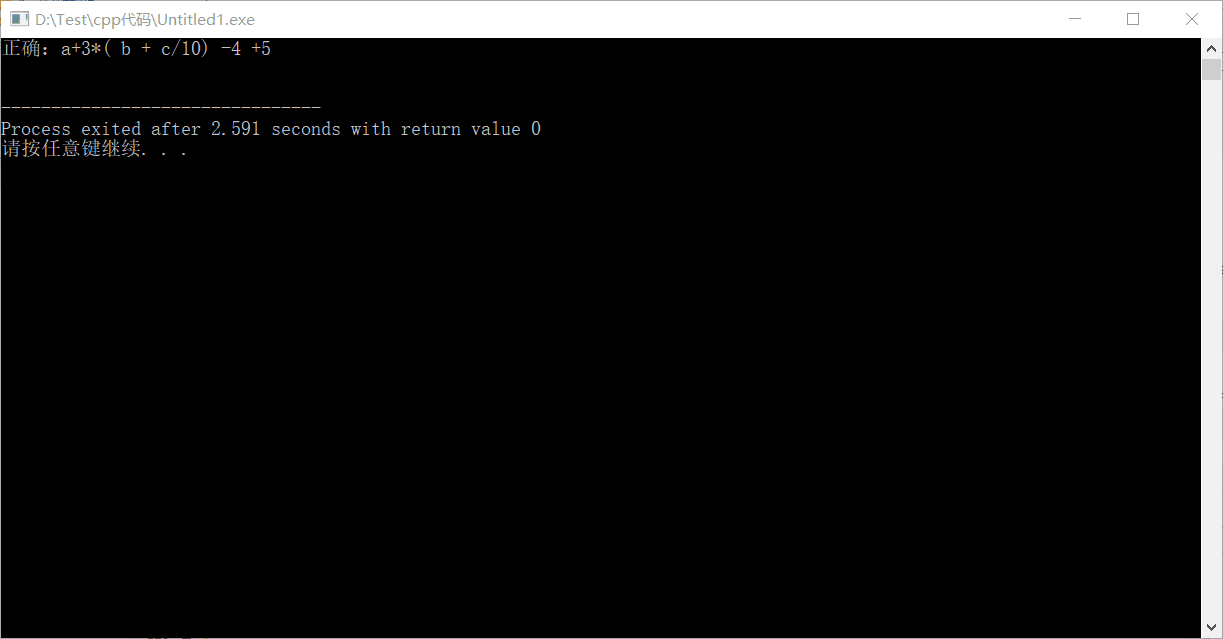
reference:https://blog.csdn.net/Flamewaker/article/details/82899466
注:本文里用到了freopen函数的句柄,该句柄作用是当不想输入或输出到文件了,要恢复句柄,可以重新打开标准控制台设备文件,这个设备文件的名字是与操作系统相关:
DOS/Win: freopen("CON", "r", stdin);
freopen("CON", "w", stdout);
在linux中,控制台设备是 /dev/console:freopen("/dev/console", "r", stdin)