目录:
一:概述
二:无失真图像压缩编码
三:有限失真图像压缩编码
四:图像编码新技术
一:概述:
由于图像信息的编码必须在保持信息源内容不变,或者损失不大的前提下才有意义,这就必然涉及到信息的度量问题。
信息量:
从统计学的角度来看,信息出现的概率是可以度量的,这个度量就是信息量。
一般而言小概率的事件所包含的信息量更大,所以事件所包含的信息量与其发生的概率成反比例关系。
将信息量定义为信息源发出的所有消息中该信息出现概率的倒数的对数。
I(ai)=-logp(ai) (7.1)
式(7.1)中,对数的底数决定了衡量信息的单位。通常取2为对数的底数,这时定义的信息量单位为比特。
信息熵:
对信息源X的各符号的自信息量取统计平均,可得平均自信息量为: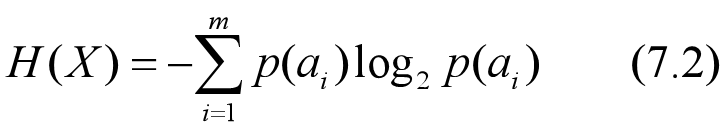
在信息论中,香农借鉴热力学中的概念,把平均自信息量H(X)称为信息源X的信息熵,用以衡量信息的不确定性。 信息熵可以理解为信息源 发出的 一个符号所携带的平均信息量,单位为比特/符号。
1 I=imread('D:/picture/lenagray.jpg'); 2 x=double(I); 3 n=256;%灰度级总数 4 xh=hist(x(:),n);%计算出图像的直方图 5 xh=xh/sum(xh(:));%计算各个灰度级出现的概率 6 i=find(xh);%直方图对应的灰度级 7 h=-sum(log2(xh(i)).*xh(i));%求出图像的熵
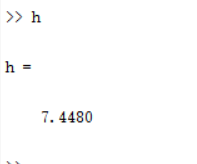
图像数据冗余类型:空间冗余,时间冗余,信息熵冗余,视觉冗余,结构冗余,知识冗余
压缩比:
为了表明某种压缩编码的效率,通常引入压缩比这一参数,它的定义为:
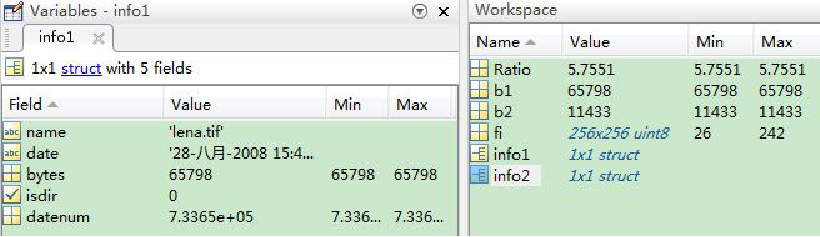
其中b1表示压缩前图像每像素的平均比特数, b2表示压缩后每像素所需的平均比特数,一般的情况下压缩比Ratio总是大于等于1的, Ratio愈大则压缩程度愈高。
1 %计算图像的压缩比c的值。 2 fi=imread(‘lena.tif’);%读取非压缩tif图像 3 imwrite(fi,’lena.jpg’);以jpg压缩格式存储图像 4 info1=dir(‘lena.tif’); 5 b1=info1.bytes; 6 info2=dir(‘lena.jpg’); 7 b2=info2.bytes; 8 Ratio=b1/b2; 9 figure,imshow(‘lena.tif’); 10 figure,imshow(‘lena.jpg’);

平均码字长度:
设m为数字图像中码字的个数,l(ck)为数字图像中第k个码字ck的长度,其相应出现的概率为p(ck),则该数字图像所赋予的平均码字长度为:

编码效率:
其中,H是原始图像的熵,L是实际编码图像的平均码字长度。

二:无失真图像压缩编码
哈夫曼编码

1 I=imread('D:/picture/lenagray.jpg'); 2 [zipped,info]=huffencode(I);%调用哈夫曼编码程序进行压缩 3 4 unzipped=huffdecode(zipped,info);%调用哈夫曼解码程序进行解码 5 6 disp('平均码长');L=info.avalen 7 8 disp('压缩比');CR=info.ratio 9 10 disp('信息熵');H=info.h 11 12 disp('编码效率');CE=info.ce 13 14 subplot(131);imshow(Source);title('原始图像'); 15 16 subplot(132);imshow(Gray);title('灰度图像'); 17 18 subplot(133);imshow(unzipped);title('哈夫曼编码并解码重构图像');
%%huffencode.m与huffdecode.m实际代码展示一部分:
1 info.zeropad=zp;%添加的比特数 2 3 info.huffcodes=huffcodes; 4 5 info.length=length(vector);%灰度图矩阵长度 6 7 info.rows=m; 8 9 info.cols=n; 10 11 info.avalen=avawordlen;%平均码长 12 13 info.ratio=8/avawordlen;%压缩比 14 15 info.h=H; 16 17 info.ce=H/avawordlen;%编码效率
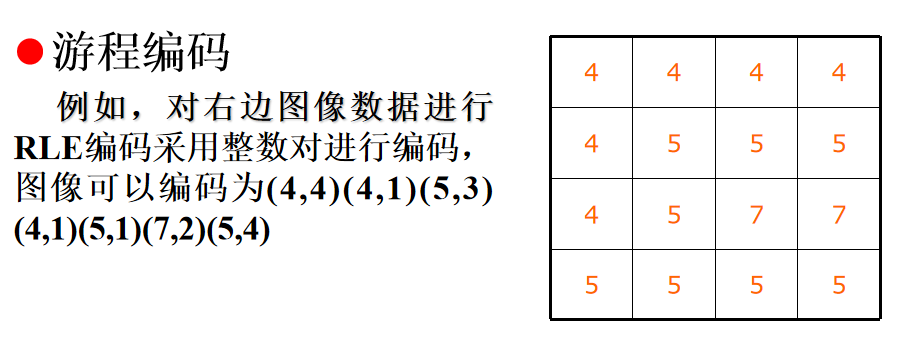
游程编码

1 I=imread('D:/picture/ZiXia.jpg'); 2 if ndims(I)>2 3 I=rgb2gray(I); 4 end 5 BW=im2bw(I,0.4);%二值化 6 [zipped,info]=RLEencode(BW);%游程编码 7 unzipped=RLEdecode(zipped,info);%游程解码 8 subplot(131);imshow(I); 9 subplot(132);imshow(BW); 10 subplot(133);imshow(uint8(unzipped)*255); 11 cr=info.ratio 12 whos BW unzipped zipped
函数程序直接截图了

算术编码:
参考:https://blog.csdn.net/qq_36752072/article/details/77986159
三:有限失真图像压缩编码
预测编码
参考:https://blog.csdn.net/qingkongyeyue/article/details/76218403
变换编码
参考:https://blog.csdn.net/qingkongyeyue/article/details/76099927
四:图像编码新技术
子带编码
子带编码是一种在频率域中进行数据压缩的算法。其指导思想是首先在发送端将图像信号在频率域分成若干子带,
然后分别对这些子带信号进行频带搬移,将其转换成基带信号,再根据奈奎斯特定理对各基带信号进行取样、量化和编码,
最后合并成为一个数据流进行传送。
模型编码
模型基编码主要是一种参数编码方法,因此它与基于保持信号原始波形的所谓波形编码相比有着本质区别。相对于对像素进行编码而言,对参数的编码所
需的比特数要少得多,因此可以节省大量的编码数据。 模型基编码主要依据对图像内容的先验知识的了解,根据掌握的信息,编码器对图像内容进行复杂的分析,并借助于一定的模型,用一系列模型的参数对图
像内容进行描述,并把这些参数进行编码传输到解码器。解码器根据接收到的参数和用同样方法建立的模型可以重建图像的内容。
分型编码
分形编码是在分形几何理论的基础上发展起来的一种编码方法。 分形编码最大限度地利用了图像在空间域上的自相似性
(即局部与整体之间存在某种相 似性),通过消除图像的几何冗余来压缩数据,对某些特定图像可获得10000: 1的压缩比。