URL详解
格式:schema://host[:port]/path/.../[?query-string][#anchor]
- scheme 指定低层使用的协议(例如:http, https, ftp)
- host HTTP服务器的IP地址或者域名
- port HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/
- path 访问资源的路径
- query-string 发送给http服务器的数据
- anchor 锚
举例:http://www.mywebsite.com/sj/test/test.aspx?name=sviergn&x=true#stuff
Request结构
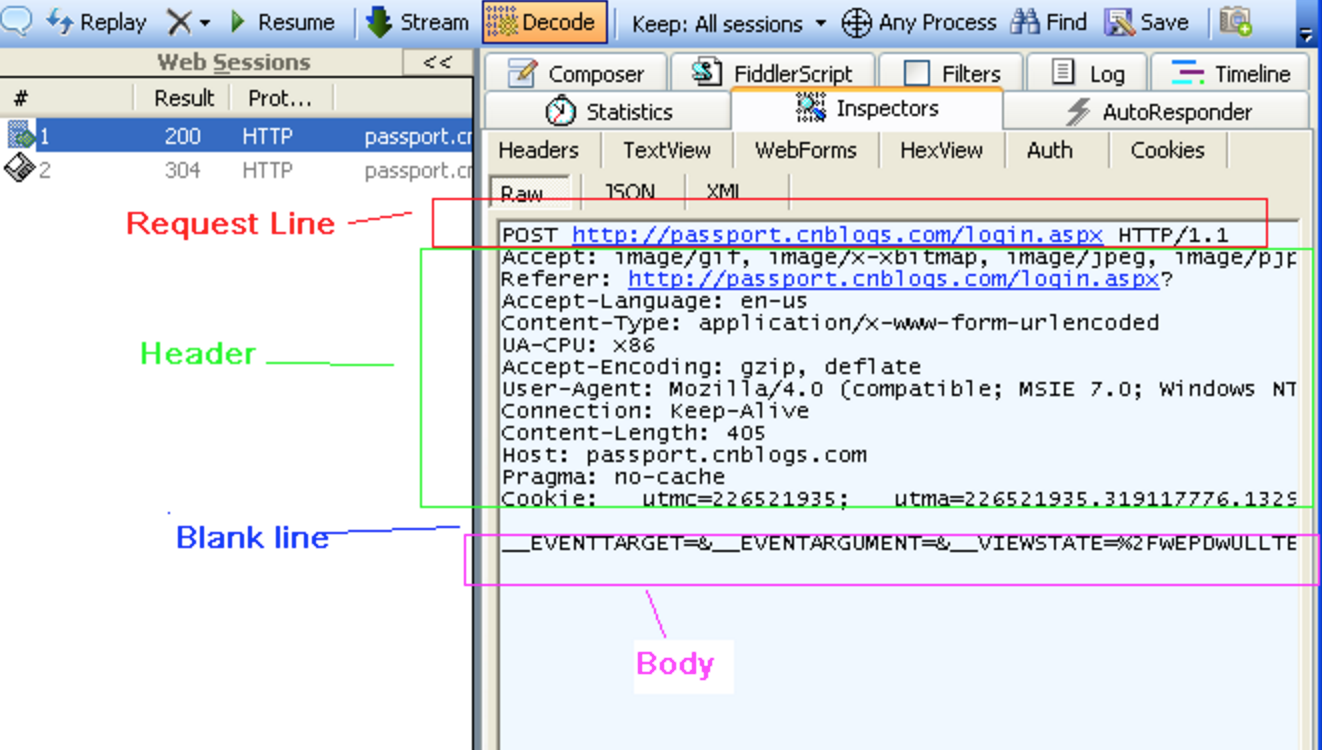
Request 消息分为3部分,第一部分叫Request line, 第二部分叫Request header, 第三部分是body. header和body之间有个空行。
第一行中的Method表示请求方法,比如"POST","GET", Path-to-resoure表示请求的资源, Http/version-number 表示HTTP协议的版本号
第二行是header。
第三部分,当使用的是"GET" 方法的时候, body是为空的。
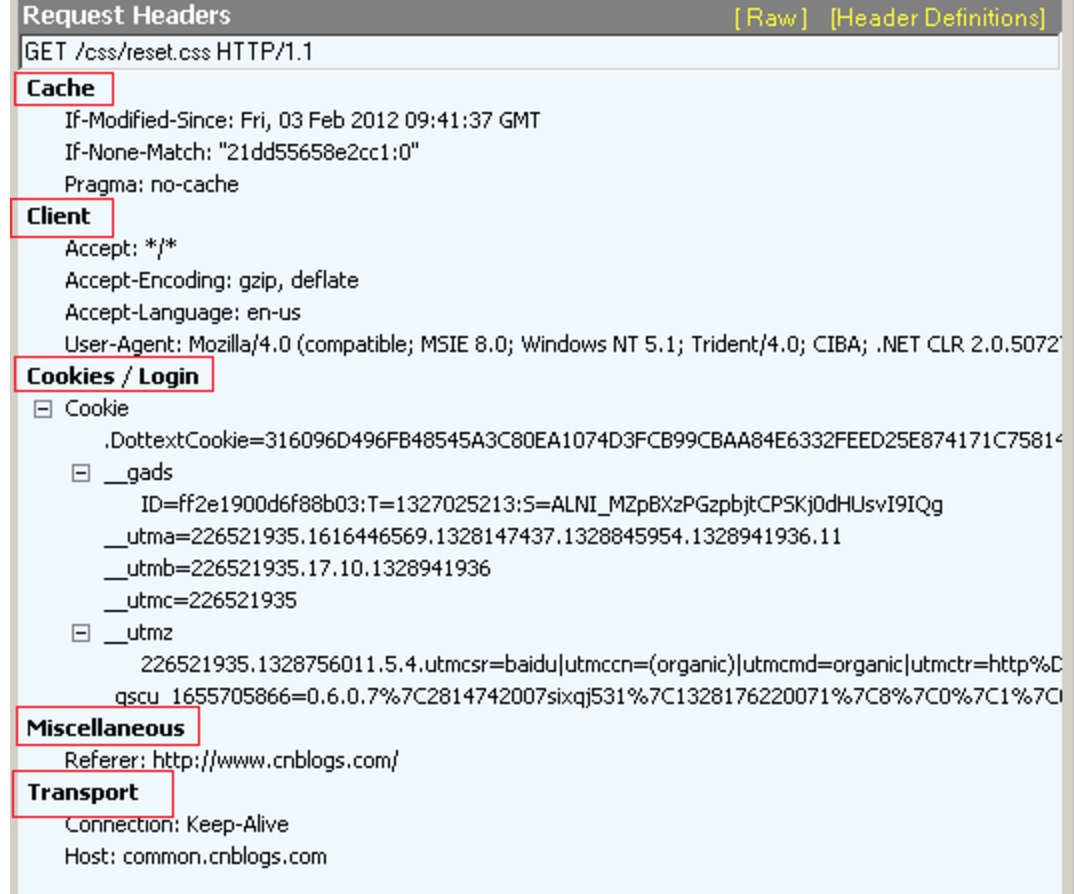
对header分类记忆:
Cache头域:
- If-Modified-Since -- 把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。如果时间一致,那么返回304,客户端就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中.
- If-None-Match -- If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 当用户再次请求该资源时,将在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服务器验证资源的ETag没有改变(该资源没有更新),将返回一个304状态告诉客户端使用本地缓存文件。否则将返回200状态和新的资源和Etag. 使用这样的机制将提高网站的性能。
- Pragma -- 防止页面被缓存, 在HTTP/1.1版本中,它和Cache-Control:no-cache作用一模一样。Pargma只有一个用法, 例如: Pragma: no-cache
- Cache-Control -- 这个是非常重要的规则。 这个用来指定Response-Request遵循的缓存机制。各个指令含义如下。Cache-Control:Public 可以被任何缓存所缓存()Cache-Control:Private 内容只缓存到私有缓存中 Cache-Control:no-cache 所有内容都不会被缓存。
Client头域:
Cookie/Login 头域:
- Cookie -- 最重要的header, 将cookie的值发送给HTTP 服务器。
Entity头域:
- Content-Length -- 发送给HTTP服务器数据的长度。
- Content-Type -- 例如:Content-Type: application/x-www-form-urlencoded
Miscellaneous头域:
- Referer--提供了Request的上下文信息的服务器,告诉服务器我是从哪个链接过来的,比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。
Transport头域:
- Connection--例如:Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。在 HTTP 1.1 版本中,默认情况下所有连接都被保持,如果加入 "Connection: close" 才关闭。目前大部分浏览器都使用 HTTP 1.1 协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
- Host--请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的。
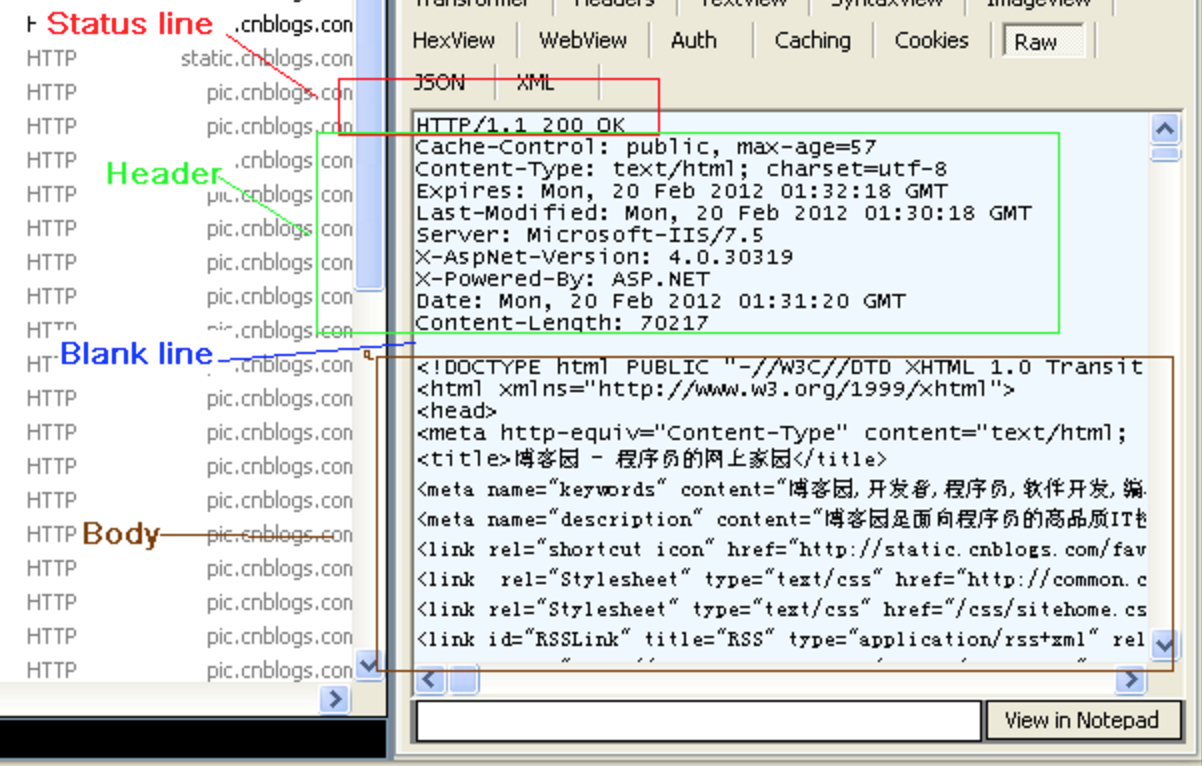
Response结构
同Request一样的结构。
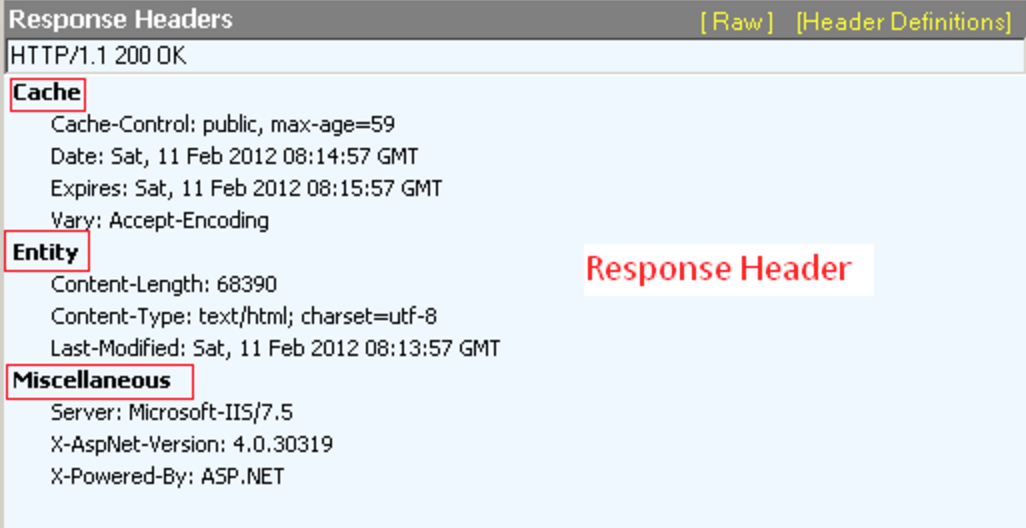
Response的header
GET和POST的区别
1. GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连. POST方法是把提交的数据放在HTTP包的Body中.
2. GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4. GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
状态码
HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别。
- 1XX 提示信息 - 表示请求已被成功接收,继续处理
- 2XX 成功 - 表示请求已被成功接收,理解,接受
- 3XX 重定向 - 要完成请求必须进行更进一步的处理
- 4XX 客户端错误 - 请求有语法错误或请求无法实现
- 5XX 服务器端错误 - 服务器未能实现合法的请求
举例:
302 Found -- 重定向,新的URL会在response 中的Location中返回,浏览器将会自动使用新的URL发出新的Request。
304 Not Modified -- 代表上次的文档已经被缓存了, 还可以继续使用。
400 Bad Request -- 客户端请求与语法错误,不能被服务器所理解。
403 Forbidden -- 服务器收到请求,但是拒绝提供服务。
500 Internal Server Error -- 服务器发生了不可预期的错误。
503 Server Unavailable -- 服务器当前不能处理客户端的请求,一段时间后可能恢复正常。
http keep-alive
在HTTP1.0和HTTP1.1协议中都有对KeepAlive的支持。其中HTTP1.0需要在request中增加“Connection:keep-alive” header才能够支持,而HTTP1.1默认支持。当使用Keep-Alive模式时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
可以在服务器端设置是否支持keep-alive。
注意:
-
HTTP Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接。
-
HTTP 长连接不可能一直保持,例如
Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。 -
HTTP是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive没能改变这个结果。另外,Keep-Alive也不能保证客户端和服务器之间的连接一定是活跃的,在HTTP1.1版本中也如此。唯一能保证的就是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于Keep-Alive的保持连接特性,否则会有意想不到的后果。
-
使用长连接之后,客户端、服务端怎么知道本次传输结束呢?两部分:1. 判断传输数据是否达到了Content-Length 指示的大小;2. 动态生成的文件没有 Content-Length ,它是分块传输(chunked),这时候就要根据 chunked 编码来判断,chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束。
- server为多为静态内容时,开启keep-alive,增加传输效率。动态请求,已占用的资源得不到释放,效率低下。
HTTP Pipelining(HTTP 管线化)
默认情况下 HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求。在使用持久连接的情况下,某个连接上消息的传递类似于请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3。
HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应。使用 HTTP Pipelining 技术之后,某个连接上的消息变成了类似这样请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3。
注意:
- 管线化机制通过持久连接(persistent connection)完成,仅 HTTP/1.1 支持此技术(HTTP/1.0不支持)
- 只有 GET 和 HEAD 请求可以进行管线化,而 POST 则有所限制
- 初次创建连接时不应启动管线机制,因为对方(服务器)不一定支持 HTTP/1.1 版本的协议
- 管线化不会影响响应到来的顺序,如上面的例子所示,响应返回的顺序并未改变
- HTTP /1.1 要求服务器端支持管线化,但并不要求服务器端也对响应进行管线化处理,只是要求对于管线化的请求不失败即可
- 由于上面提到的服务器端问题,开启管线化很可能并不会带来大幅度的性能提升,而且很多服务器端和代理程序对管线化的支持并不好,因此现代浏览器如 Chrome 和 Firefox 默认并未开启管线化支持。
会话跟踪
浏览器与服务器之间的通信是通过HTTP协议进行通信的,而HTTP协议是”无状态”的协议,它不能保存客户的信息,即一次响应完成之后连接就断开了,下一次的请求需要重新连接,这样就需要判断是否是同一个用户,所以才有会话跟踪技术来实现这种要求。
会话跟踪常用的方法:
- URL重写。URL(统一资源定位符)是Web上特定页面的地址,URL重写的技术就是在URL结尾添加一个附加数据以标识该会话,把会话ID通过URL的信息传递过去,以便在服务器端进行识别不同的用户。
- 隐藏表单域。将会话ID添加到HTML表单元素中提交到服务器,此表单元素并不在客户端显示。
- Cookie。Cookie是Web服务器发送给客户端的一小段信息,客户端请求时可以读取该信息发送到服务器端,进而进行用户的识别。对于客户端的每次请求,服务器都会将Cookie发送到客户端,在客户端可以进行保存,以便下次使用。客户端可以采用两种方式来保存这个Cookie对象,一种方式是保存在客户端内存中,称为临时Cookie,浏览器关闭后这个Cookie对象将消失。另外一种方式是保存在客户机的磁盘上,称为永久Cookie。以后客户端只要访问该网站,就会将这个Cookie再次发送到服务器上,前提是这个Cookie在有效期内,这样就实现了对客户的跟踪。Cookie是可以被禁止的。
- Session。每一个用户都有一个不同的session,各个用户之间是不能共享的,是每个用户所独享的,在session中可以存放信息。在服务器端会创建一个session对象,产生一个sessionID来标识这个session对象,然后将这个sessionID放入到Cookie中发送到客户端,下一次访问时,sessionID会发送到服务器,在服务器端进行识别不同的用户。Session的实现依赖于Cookie,如果Cookie被禁用,那么session也将失效。