#------------------------------------------------------------------------------------ # 理想论坛爬虫1.08,用于爬取主贴再爬子贴,数据存到文件里,再由insertDB.py读取插DB # 增加同网址访问五次异常后退出机制 # 2018年4月27日 #------------------------------------------------------------------------------------ from bs4 import BeautifulSoup import requests import threading import re import time import datetime import os import json import colorama from colorama import Fore, Back, Style colorama.init() user_agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' headers={'User-Agent':user_agent} # 存储数据文件的目录 folder="" # 主帖数组 topics=[] #------------------------------------ # 在论坛页中寻找主贴 # pageUrl:论坛页url #------------------------------------ def findTopics(pageUrl): print(" 开始读取页面"+pageUrl+"的帖子"); try: rsp=requests.get(pageUrl,headers=headers) rsp.encoding = 'gb18030' #解决中文乱码问题的关键 soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='gb2312') for tbodys in soup.find_all('tbody'): pageCount=1 url='none' title='none' for spans in tbodys.find_all('span',class_="forumdisplay"): for link in spans.find_all('a'): if link and link.get("href"): url="http://www.55188.com/"+link.get("href") title=link.text for spans in tbodys.find_all('span',class_="threadpages"): for link in spans.find_all('a'): pageCount=link.text if url!='none' and title!='none': topic={'pageCount':pageCount,'url':url,'title':title} #print("topic="+str(topic)) topics.append(topic) #print("读取页面"+pageUrl+"的帖子完毕"); except Exception as e: log("findTopics出现异常:"+str(e),'red') #------------------------------------ # 以不同颜色在控制台输出文字 # pageUrl:论坛页url #------------------------------------ def log(text,color): if color=='red': print(Fore.RED + text+ Style.RESET_ALL) elif color=='green': print(Fore.GREEN + text+ Style.RESET_ALL) elif color=='yellow': print(Fore.YELLOW + text+ Style.RESET_ALL) else: print(text) #------------------------------------ # 找到并保存帖子的细节 # index:序号,url:地址,title:标题 #------------------------------------ def saveTopicDetail(index,url,title): infos=[] # 找到的子贴信息 tried=0; # 尝试次数 while(len(infos)==0): try: rsp=requests.get(url,headers=headers) rsp.encoding = 'gb18030' #解决中文乱码问题的关键 soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='gb2312') session = requests.session() session.keep_alive = False for divs in soup.find_all('div',class_="postinfo"): # 用正则表达式将多个空白字符替换成一个空格 RE = re.compile(r'(s+)') line=RE.sub(" ",divs.text) arr=line.split(' ') arrLength=len(arr) if arrLength==7: info={'楼层':arr[1], '作者':arr[2].replace('只看:',''), '日期':arr[4], '时间':arr[5],'title':title,'url':url} infos.append(info) elif arrLength==8: info={'楼层':arr[1], '作者':arr[2].replace('只看:',''), '日期':arr[5], '时间':arr[6],'title':title,'url':url} infos.append(info) #存文件 filename=folder+"/"+str(index)+'.json' with open(filename,'w',encoding='utf-8') as fObj: json.dump(infos,fObj) except Exception as e: log("saveTopicDetail访问"+url+"时出现异常:"+str(e),'red') time.sleep(5) # 如果出现异常,休息五秒后再试 tried=tried+1 if(tried>4): log("尝试5次仍无法访问:"+url+",只得跳过此页",'yellow') break continue #------------------------------------ # 入口函数 # start:起始页,end:终止页 #------------------------------------ def main(start,end): # 创建目录 currTime=time.strftime('%H_%M_%S',time.localtime(time.time())) global folder folder="./"+currTime os.makedirs(folder) print("目录"+folder+"创建完成") # 获取主贴 print(' 将从以下页面获取主贴:'); for i in range(start,end+1): pageUrl='http://www.55188.com/forum-8-'+str(i)+'.html' # 这个页是论坛页,即第1页,第2页等 findTopics(pageUrl); n=len(topics) log("共读取到:"+str(n)+"个主贴",'green') # 获取主贴及其子贴 finalTopics=[] index=0 for topic in topics: end=int(topic['pageCount'])+1 title=topic['title'] for i in range(1,end): pattern='-(d+)-(d+)-(d+)' newUrl=re.sub(pattern,lambda m:'-'+m.group(1)+'-'+str(i)+'-'+m.group(3),topic['url']) #print(newUrl) newTopic={'index':index,'url':newUrl,'title':title} finalTopics.append(newTopic) index=index+1 n=len(finalTopics) log("共读取到:"+str(n)+"个帖子",'green') # 遍历finalTopics for newTopic in finalTopics: saveTopicDetail(newTopic['index'],newTopic['url'],newTopic['title']); # 开始 main(1,10)
用得到的数据再用以下数据进行一次统计:
# 对发帖时间进行统计 import re import pymysql # 入口函数 def main(): dic={'00':0,'01':0,'02':0,'03':0,'04':0,'05':0,'06':0,'07':0,'08':0,'09':0,'10':0,'11':0,'12':0,'13':0,'14':0,'15':0,'16':0,'17':0,'18':0,'19':0,'20':0,'21':0,'22':0,'23':0} conn=pymysql.connect(host='127.0.0.1',user='root',passwd='12345678',db='test',charset='utf8') cs=conn.cursor() cs.execute("select * from topic0426") results = cs.fetchall() for row in results: ttime=row[4] hour=ttime.split(':')[0] dic[hour]=dic[hour]+1 conn.close() print(dic) # 开始 main()
输出为:
C:Usershorn1Desktoppython28>python sum.py {'00': 4305, '01': 1432, '02': 637, '03': 381, '04': 375, '05': 1304, '06': 3461, '07': 8311, '08': 22321, '09': 38335, '10': 37241, '11': 26504, '12': 13337, '13': 24906, '14': 29231, '15': 24648, '16': 13926, '17': 11280, '18': 9332, '19': 13444, '20': 19144, '21': 24731, '22': 20297, '23': 10736} C:Usershorn1Desktoppython28>
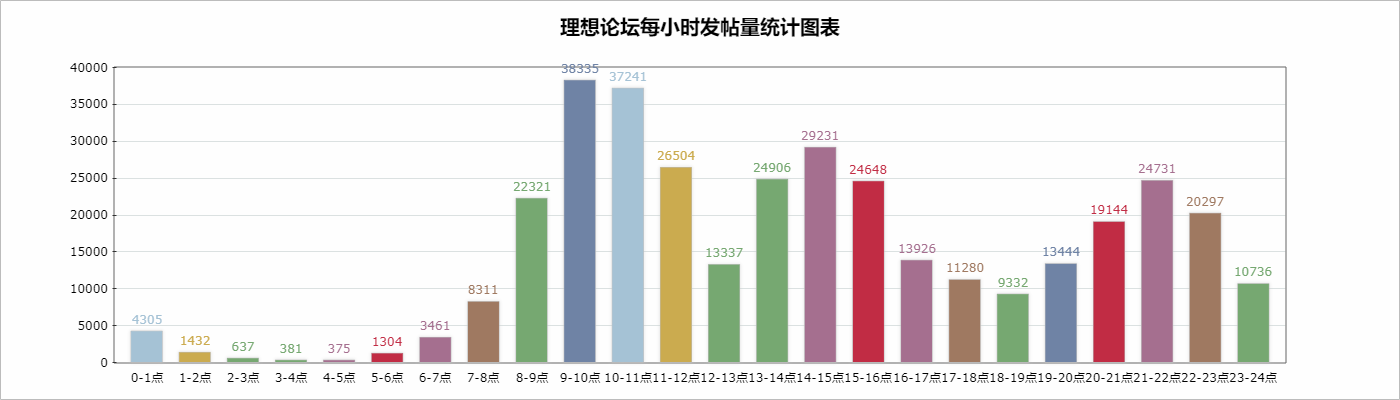
统计图生成代码为:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title> New Document </title> <meta name="Generator" content="EditPlus"> <meta name="Author" content=""> <meta name="Keywords" content=""> <meta name="Description" content=""> </head> <script src="ichart.1.2.min.js"></script> <body> <div id='canvasDiv'></div> </body> </html> <script type="text/javascript"> <!-- var dic={'00': 4305, '01': 1432, '02': 637, '03': 381, '04': 375, '05': 1304, '06': 3461, '07': 8311, '08': 22321, '09': 38335, '10': 37241, '11': 26504, '12': 13337, '13': 24906, '14': 29231, '15': 24648, '16': 13926, '17': 11280, '18': 9332, '19': 13444, '20': 19144, '21': 24731, '22': 20297, '23': 10736}; //定义数据 var data = [ {name : '0-1点', value : dic['00'],color:'#a5c2d5'}, {name : '1-2点', value : dic['01'],color:'#cbab4f'}, {name : '2-3点', value : dic['02'],color:'#76a871'}, {name : '3-4点', value : dic['03'],color:'#76a871'}, {name : '4-5点', value : dic['04'],color:'#a56f8f'}, {name : '5-6点', value : dic['05'],color:'#c12c44'}, {name : '6-7点', value : dic['06'],color:'#a56f8f'}, {name : '7-8点', value : dic['07'],color:'#9f7961'}, {name : '8-9点', value : dic['08'],color:'#76a871'}, {name : '9-10点', value : dic['09'],color:'#6f83a5'}, {name : '10-11点',value : dic['10'],color:'#a5c2d5'}, {name : '11-12点',value : dic['11'],color:'#cbab4f'}, {name : '12-13点',value : dic['12'],color:'#76a871'}, {name : '13-14点',value : dic['13'],color:'#76a871'}, {name : '14-15点',value : dic['14'],color:'#a56f8f'}, {name : '15-16点',value : dic['15'],color:'#c12c44'}, {name : '16-17点',value : dic['16'],color:'#a56f8f'}, {name : '17-18点',value : dic['17'],color:'#9f7961'}, {name : '18-19点',value : dic['18'],color:'#76a871'}, {name : '19-20点',value : dic['19'],color:'#6f83a5'}, {name : '20-21点',value : dic['20'],color:'#c12c44'}, {name : '21-22点',value : dic['21'],color:'#a56f8f'}, {name : '22-23点',value : dic['22'],color:'#9f7961'}, {name : '23-24点',value : dic['23'],color:'#76a871'} ]; $(function(){ var chart = new iChart.Column2D({ render : 'canvasDiv',//渲染的Dom目标,canvasDiv为Dom的ID data: data,//绑定数据 title : '理想论坛每小时发帖量统计图表',//设置标题 width : 1400,//设置宽度,默认单位为px height : 400,//设置高度,默认单位为px shadow:true,//激活阴影 shadow_color:'#c7c7c7',//设置阴影颜色 coordinate:{//配置自定义坐标轴 scale:[{//配置自定义值轴 position:'left',//配置左值轴 start_scale:0,//设置开始刻度为0 end_scale:10000,//设置结束刻度为26 scale_space:5000,//设置刻度间距 listeners:{//配置事件 parseText:function(t,x,y){//设置解析值轴文本 return {text:t+""} } } }] } }); //调用绘图方法开始绘图 chart.draw(); }); //--> </script>
以上全体代码可以在这里下载:
https://files.cnblogs.com/files/xiandedanteng/lixiang108_20180427.rar