1. 流程分析
1.1 分析目标地址分页的情况
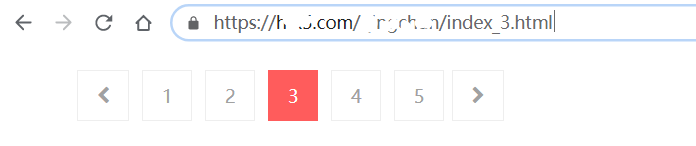
- 第一页:https://域名/分类/index.html
- 第二页:https://域名/分类/index_2.html
- 第三页:https://域名/分类/index_3.html
即可得出目标分页的规律
1.2 分析某一页各个项的特征
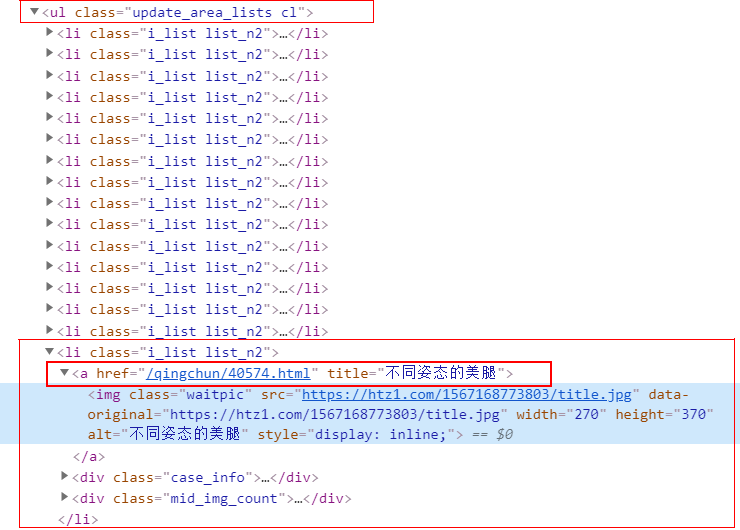
观察得出每一项的url地址在单页各个项的ul下面的li中的a标签中保存,进入这个url地址即可得到此项中所有图片的地址;
此外这个a标签的alt属性中还保存了此项的摘要描述。
1.3 进入某一目标项获取图片

通过以上步骤,我们要想获取图片的url的路径,需要访问每一页的每一项的URL,这样即可加载获取所有图片的URL地址;
拿到图片地址后保存,然后即可开启多线程下载图片。
2. 代码实现
2.1 代码
import os, re import requests import logging from bs4 import BeautifulSoup from urllib.request import urlretrieve from concurrent.futures import ThreadPoolExecutor logging.captureWarnings(True) # 忽略所有警告信息 class fuck_photo(): xxoo = """ 1: Asian 2: Cartoon 3: Cute 4: Secret 5: Silk """ def __init__(self, server, base_url, dirname, thread_num, headers, ): self.server = server self.base_url = base_url self.dirname = dirname self.headers = headers self.set_path(dirname) self.thread_poll = ThreadPoolExecutor(thread_num) self.photo_type = { 1: "yazhousetu/", 2: "katong/", 3: "mengmeizi/", 4: "zipai/", 5: "qingchun/", } def get_page_list(self, target, start_page, max_page): """获取所有页的url""" if start_page <= 1: page_list = [target, ] print("从第一页开始爬...") start_page += 1 else: page_list = [] for i in range(start_page, max_page + 1): page_link = target[:-5] + "_" + str(i) + ".html" page_list.append(page_link) print(' 所有图片会保存在【%s】文件夹中... ' % self.dirname) return page_list def get_list(self, target): """获取每页所有项目的url""" per_page_link_list = [] response = requests.get(url=target, headers=self.headers, verify=False) content = BeautifulSoup(response.text, features="html.parser") the_list = content.find('ul', class_='update_area_lists cl').find_all('a') for i in the_list: per_page_link_list.append(self.server[:-1] + i.get('href')) return per_page_link_list def get_photo_link_list(self, link_target): """获取某页中某个项中所有图片的URL""" photo_link_dick = {} response = requests.get(url=link_target, headers=self.headers, verify=False) content = BeautifulSoup(response.text, features="html.parser") the_list = content.find('div', class_='content_left').find_all('img') for i in the_list: photo_link_dick[i.get('src')] = i.get('alt') return photo_link_dick def set_path(self, dirname): self.dirpath = os.getcwd() + os.sep + dirname if not os.path.isdir(self.dirpath): os.mkdir(dirname) def download_photo(self, photo_links, ret): """下载图片""" try: # filename = re.findall('/(w*?.jpg)', photo_links)[0] filename = re.findall('/(w*?.jpg)', photo_links)[0][-12:] path = self.dirpath + os.sep + ret[photo_links] + filename urlretrieve(photo_links, path) except Exception as e: print("sorry,图片下载时出现了一个错误: %s 【已忽略...】" % e) pass def download_thread(self, i): ret = photo.get_photo_link_list(i) for item in ret: self.thread_poll.submit(photo.download_photo, item, ret) def start_fuck(self): type_num = int(input(self.xxoo + ' ' + "请输入图片类型:")) while not type_num: print("请输入对应的数字!" + ' ' + self.xxoo) type_num = int(input("请输入图片类型:")) target = self.base_url + self.photo_type.get(type_num) + 'index.html' startpage = int(input("从哪一页开始:")) maxpage = int(input("到哪一页为止:")) # 获取指定范围内所有项的URL all_page_list = self.get_page_list(target, startpage, maxpage) for item in all_page_list: try: content_list = photo.get_list(item) for i in content_list: photo.download_thread(i) except Exception as e: print("出现了一个错误: %s 【已忽略】" % e) pass if __name__ == '__main__': photo = fuck_photo( "https://htx5.com/", # 目标主机 "https://htx5.com/", # 目标地址 "精美壁纸", # 设置保存图片的目录,更改爬取类型时,要修改这里的目录名称 64, # 线程数 { # 配置请求头 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0', 'Referer': "https://htx5.com/", } ) photo.start_fuck()
2.2 运行效果

