1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
一、用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
1.启动hadoop
2.Hdfs上创建文件夹并查看

3.上传英文词频统计文本至hdfs


4.启动Hive

5.导入文件内容到表docs并查看
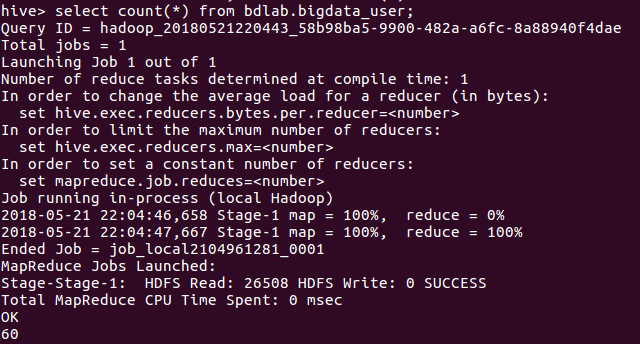
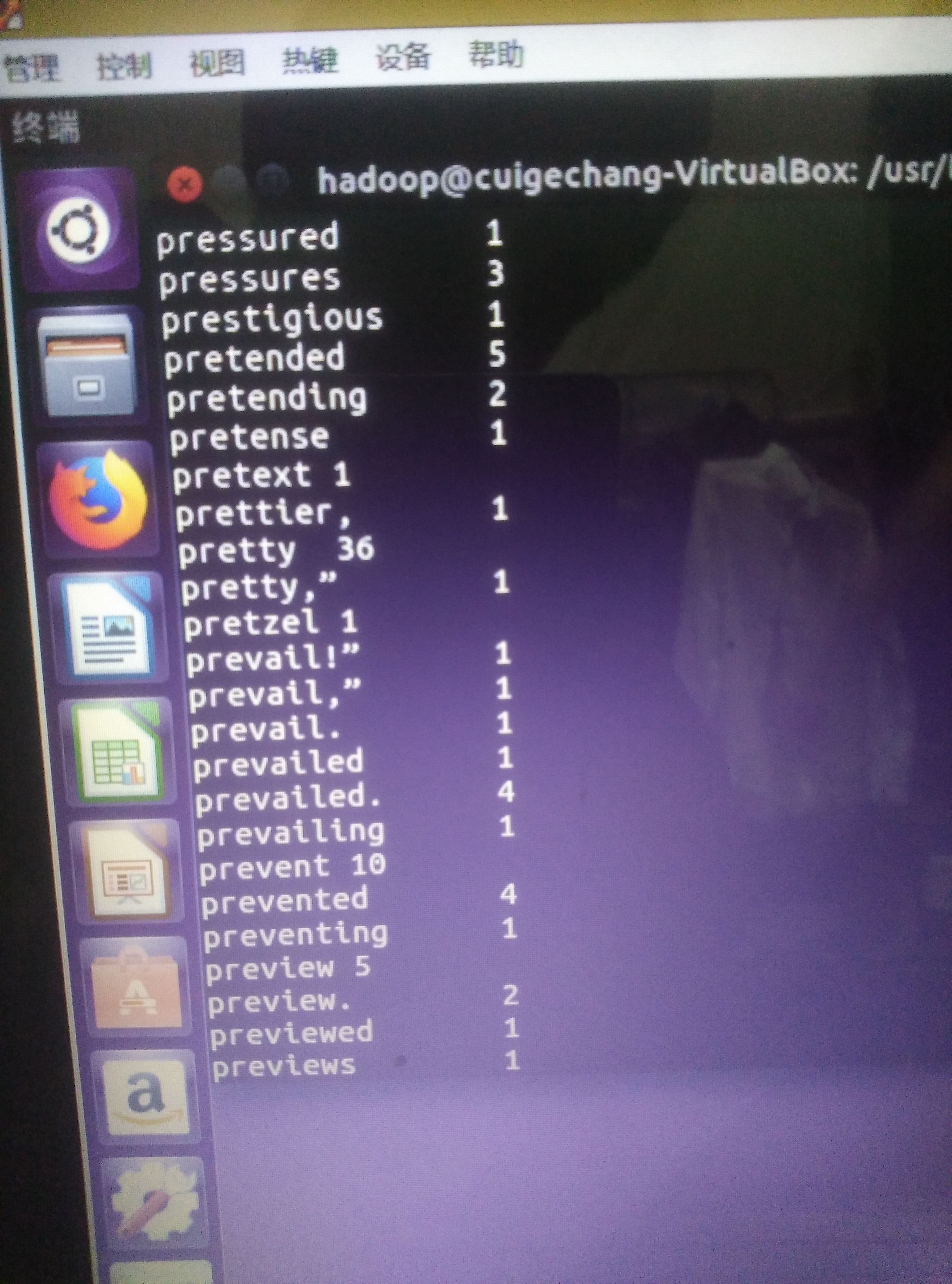
6.进行词频统计,结果放在表t_word_count里

7.查看统计结果
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
首先将爬虫大作业的数据导出为CSV文件cgpnewss.csv
这是我的csv文件:

然后通过邮箱下载进虚拟机中, 将文件拷贝到 /usr/local/bigdatacase/dataset文件夹中

显示文件前五行数据
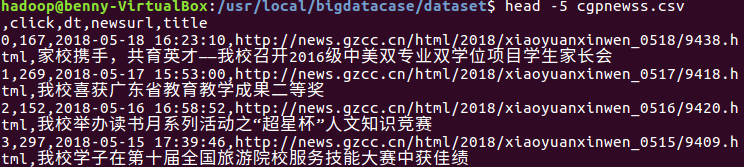
数据集预处理:
删除第一行记录, 即字段名称

对字段进行预处理
为每行记录增加一个id字段(让记录具有唯一性)
增加一个作者字段(用来后续进行可视化分析)
vim建一个脚本文件pre_deal.sh

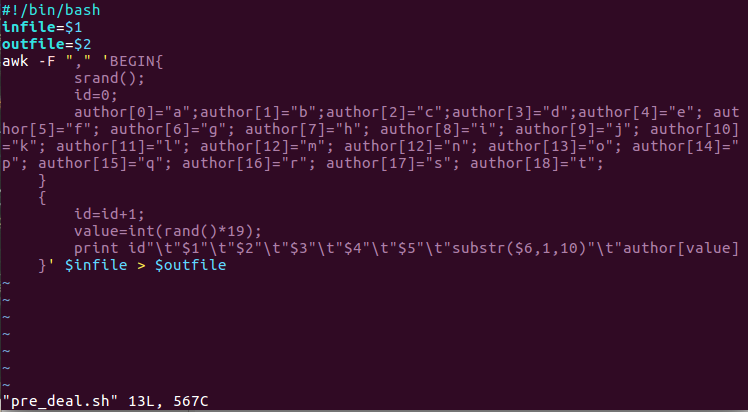
执行pre_deal,sh脚本文件,来对cgpnewss.csv进行数据预处理

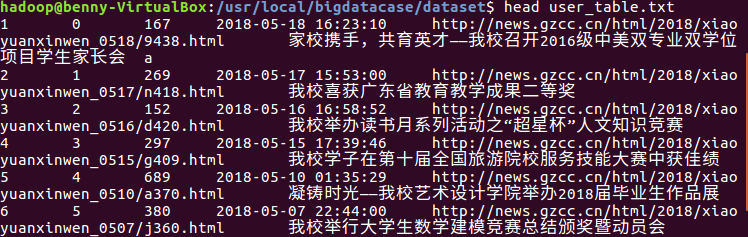
查看生成的user_table.txt
启动HDFS
在HDFS上建立bigdatacase/dataset文件夹

把user_table.txt上传到HDFS中

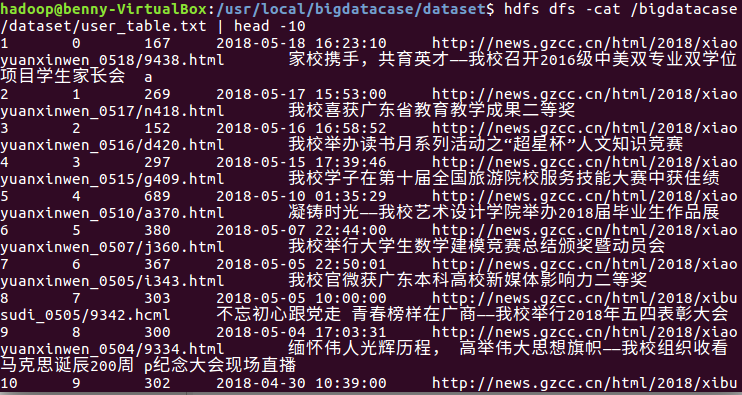
查看HDFS中的user_table.txt的前十条记录
启动HIVE,然后创建数据库bdlab

创建外部表,把HDFS中的“/bigdatacase/dataset”目录下的数据加载到数据仓库HIVE中

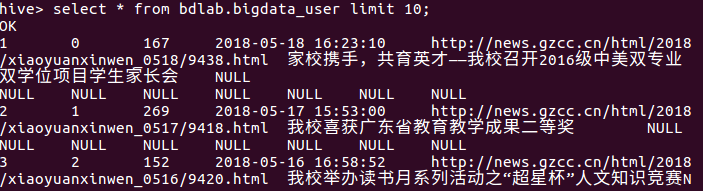
在HIVE中查看数据
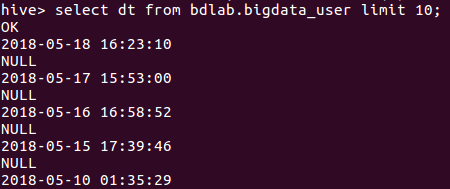
查看其中一列数据
查看有多少条数据