1 模型表示
以房屋交易问题为例,假使问题的训练集如下:
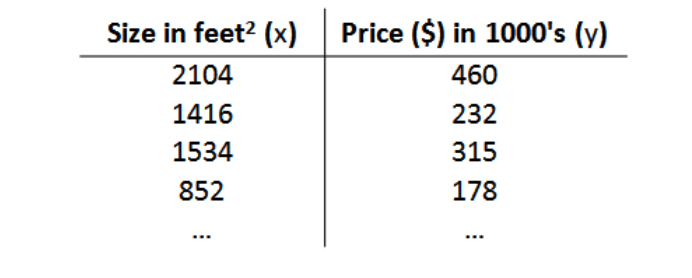
我们将要用来描述这个回归问题的标记如下:
- (m) :代表训练集中实例的数量
- (x) :代表特征/输入变量
- (y) :代表目标变量/输出变量
- (left( x,y
ight)) :代表训练集中的实例
- (({{x}^{(i)}},{{y}^{(i)}})): 代表第(i) 个观察实例
- (h) :代表学习算法的解决方案或函数也称为假设(hypothesis)
整个回归模型流程如下
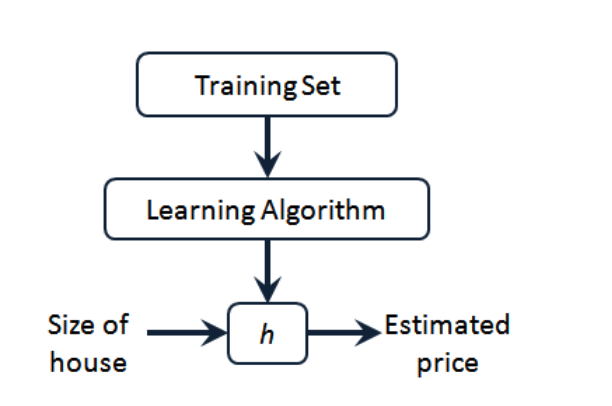
2 代价函数
目标函数为:
[h_ heta left( x
ight)= heta_{0}+ heta_{1}x
]
求出合适的参数(parameters)( heta_{0}) 和 ( heta_{1}),在这个例子中便是直线的斜率和在 (y) 轴上的截距。
模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)
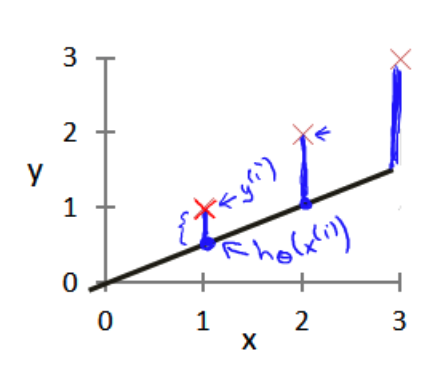
目标是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价函数最小。
[J left( heta_0, heta_1
ight) = frac{1}{2m}sumlimits_{i=1}^m left( h_{ heta}(x^{(i)})-y^{(i)}
ight)^{2}
]
绘制一个等高线图,三个坐标分别为 ( heta_{0}) 和 ( heta_{1}) 和 (J( heta_{0}, heta_{1})):
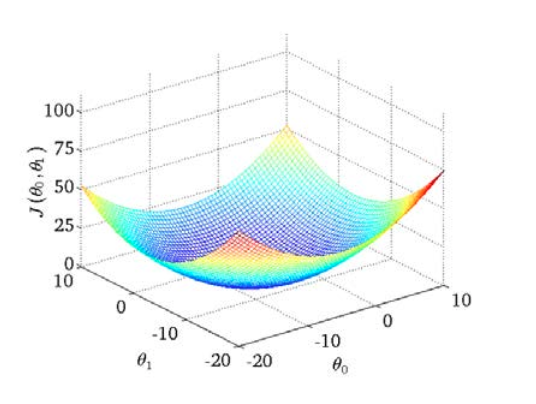
可以看出在三维空间中存在一个使得 (J( heta_{0}, heta_{1})) 最小的点。
这类代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。
优化的目标是最小化代价函数,即
[ underset{ heta_{0}, heta_{1}}{operatorname{minimize}}J( heta_{0}, heta_{1})
]
代价函数等高线图如下,可以看出在三维空间中存在一个使得(J( heta_{0}, heta_{1}))最小的点。
需要的是一种算法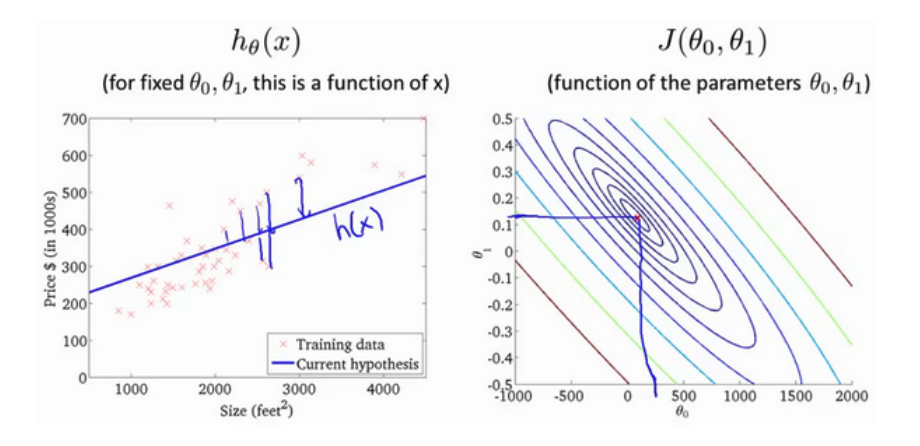 能自动地找出这些使代价函数(J)取最小值的参数 ( heta_{0}) 和 ( heta_{1}) 来。
能自动地找出这些使代价函数(J)取最小值的参数 ( heta_{0}) 和 ( heta_{1}) 来。
3 梯度下降
梯度下降是用来求函数最小值的算法,使用梯度下降法来求出代价函数 (J( heta_{0}, heta_{1})) 的最小值。
梯度下降背后的思想:
-
Step 1 :随机选择一个初始参数 (left( { heta_{0}},{ heta_{1}},......,{ heta_{n}}
ight)),计算代价函数,
-
Step 2 :寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到找到一个局部最小值(local minimum)
因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
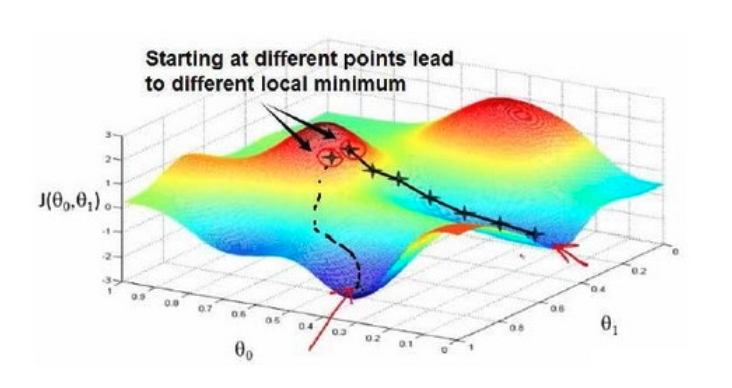
想象正站立在山的这一点上,在梯度下降算法中,我们要做的就是旋转360度,朝梯度最大的某个方向上,用小碎步尽快下山。
批量梯度下降(batch gradient descent)算法的公式为:
[�egin{array}{l} ext { repeat until convergence { } \ left.qquad heta_{j}:= heta_{j}-alpha frac{partial}{partial heta_{j}} Jleft( heta_{0}, heta_{1}
ight) quad ext { (for } j=0 ext { and } j=1
ight) \ }end{array}
]
其中 (alpha) 是学习率(learning rate),决定移动步幅大小
在批量梯度下降中,每次都同时让所有的参数减去学习速率乘以代价函数的导数。其实就是代价函数的偏导,通常使用不同的搜索算法对此进行搜索找到最优值
[alpha frac{partial }{partial {{ heta }_{0}}}J({{ heta }_{0}},{{ heta }_{1}})
\
alpha frac{partial }{partial {{ heta }_{1}}}J({{ heta }_{0}},{{ heta }_{1}})
]
梯度下降更新参数:
[�egin{array}{l} ext { temp } 0:= heta_{0}-alpha frac{partial}{partial heta_{0}} Jleft( heta_{0}, heta_{1}
ight) \ ext { temp } 1:= heta_{1}-alpha frac{partial}{partial heta_{1}} Jleft( heta_{0}, heta_{1}
ight) \ heta_{0}:= ext { temp } 0 \ heta_{1}:= ext { temp } 1end{array}
]
4 梯度下降的直观理解
[{ heta_{j}}:={ heta_{j}}-alpha frac{partial }{partial { heta_{j}}}Jleft( heta
ight)
]
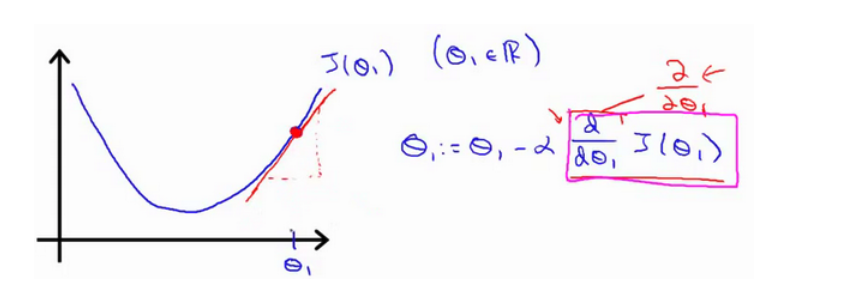
对 $ heta $ 赋初值,使得 (Jleft( heta
ight)) 按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。其中 (alpha) 是学习率(learning rate),决定了沿着下降程度最大的方移动的程度。
[{ heta_{j}}:={ heta_{j}}-alpha frac{partial }{partial { heta_{j}}}Jleft( heta
ight)
]
如果我们预先把 ({ heta_{1}}) 放在一个局部的最低点,下一步梯度下降法会怎样
假设将 ({ heta_{1}}) 初始化在局部最低点,那么对于将各参数的偏导将等于零,那么梯度下降法更新其实什么都没做,它不会改变参数的值。
在梯度下降中,当接近局部最低点时,根据凸函数的性质,偏导会变小,梯度下降法会自动采取更小的幅度,没有必要再另外减小 (a),所以 (a) 是全局固定的。
5 梯度下降的线性回归
对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
[frac{partial }{partial {{ heta }_{j}}}J({{ heta }_{0}},{{ heta }_{1}})=frac{partial }{partial {{ heta }_{j}}}frac{1}{2m}{{sumlimits_{i=1}^{m}{left( {{h}_{ heta }}({{x}^{(i)}})-{{y}^{(i)}}
ight)}}^{2}}
]
(j=0) 时:
[frac{partial }{partial {{ heta }_{0}}}J({{ heta }_{0}},{{ heta }_{1}})=frac{1}{m}{{sumlimits_{i=1}^{m}{left( {{h}_{ heta }}({{x}^{(i)}})-{{y}^{(i)}}
ight)}}}
]
(j=1) 时:
[frac{partial }{partial {{ heta }_{1}}}J({{ heta }_{0}},{{ heta }_{1}})=frac{1}{m}sumlimits_{i=1}^{m}{left( left( {{h}_{ heta }}({{x}^{(i)}})-{{y}^{(i)}}
ight)cdot {{x}^{(i)}}
ight)}
]
则算法改写成:
[�egin{array}{l} ext { Repeat { } \ qquad �egin{array}{l} heta_{0}:= heta_{0}-a frac{1}{m} sum_{i=1}^{m}left(h_{ heta}left(x^{(i)}
ight)-y^{(i)}
ight) \ heta_{1}:= heta_{1}-a frac{1}{m} sum_{i=1}^{m}left(left(h_{ heta}left(x^{(i)}
ight)-y^{(i)}
ight) cdot x^{(i)}
ight)end{array} \ }end{array}
]
批量梯度下降
指在梯度下降的每一步中,我们都用到了所有的训练样本,更新所有的调整参数,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,我们最终都要计算这样一个东西,这个项需要对所有 (m)个训练样本求和。
6 多变量情形
6.1 形式变化
假设函数变为以下形式
[h_{ heta}left( x
ight)={ heta_{0}}+{ heta_{1}}{x_{1}}+{ heta_{2}}{x_{2}}+...+{ heta_{n}}{x_{n}}
]
为了便于计算,在原特征矩阵中加入全 1 的列 (x_0) 后变为
[h_{ heta} left( x
ight)={ heta_{0}}{x_{0}}+{ heta_{1}}{x_{1}}+{ heta_{2}}{x_{2}}+...+{ heta_{n}}{x_{n}}
]
代价函数类推,梯度下降过程中一次行更新所有的参数,如下
[�egin{array}{l} ext { Repeat }{ \ qquad heta_{mathrm{j}}:= heta_{mathrm{j}}-alpha frac{1}{mathrm{~m}} sum_{mathrm{i}=1}^{mathrm{m}}left(left(mathrm{h}_{ heta}left(mathrm{x}^{(mathrm{i})}
ight)-mathrm{y}^{(mathrm{i})}
ight) cdot mathrm{x}_{mathrm{j}}^{(mathrm{i})}
ight)
\
~~~~~~~~~ ext { ( simultaneously update } heta_{mathrm{j}} ext { for } mathrm{j}=0,1, ldots, mathrm{n}) \ quad}end{array}
]
6.2 特征缩放
特征变多后,存在尺度相差较大的问题,为了解决因为尺度相差较大降低梯度下降效率的问题,将所有特征缩放到同一尺度下
例如在房价问题中
- 尺寸为 (0sim 2000)
- 房间数量为 (0sim 5)
以两个参数分别为横纵坐标,绘制代价函数的等高线图如下
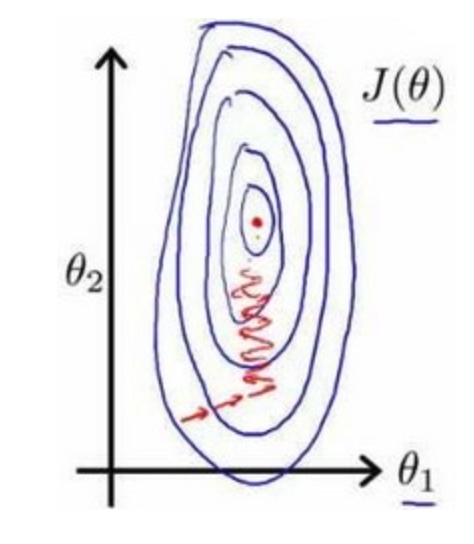
图像很扁,梯度下降需要更多的迭代才能收敛
将所有特征映射到 ([-1, 1]) 之间,变化后如下
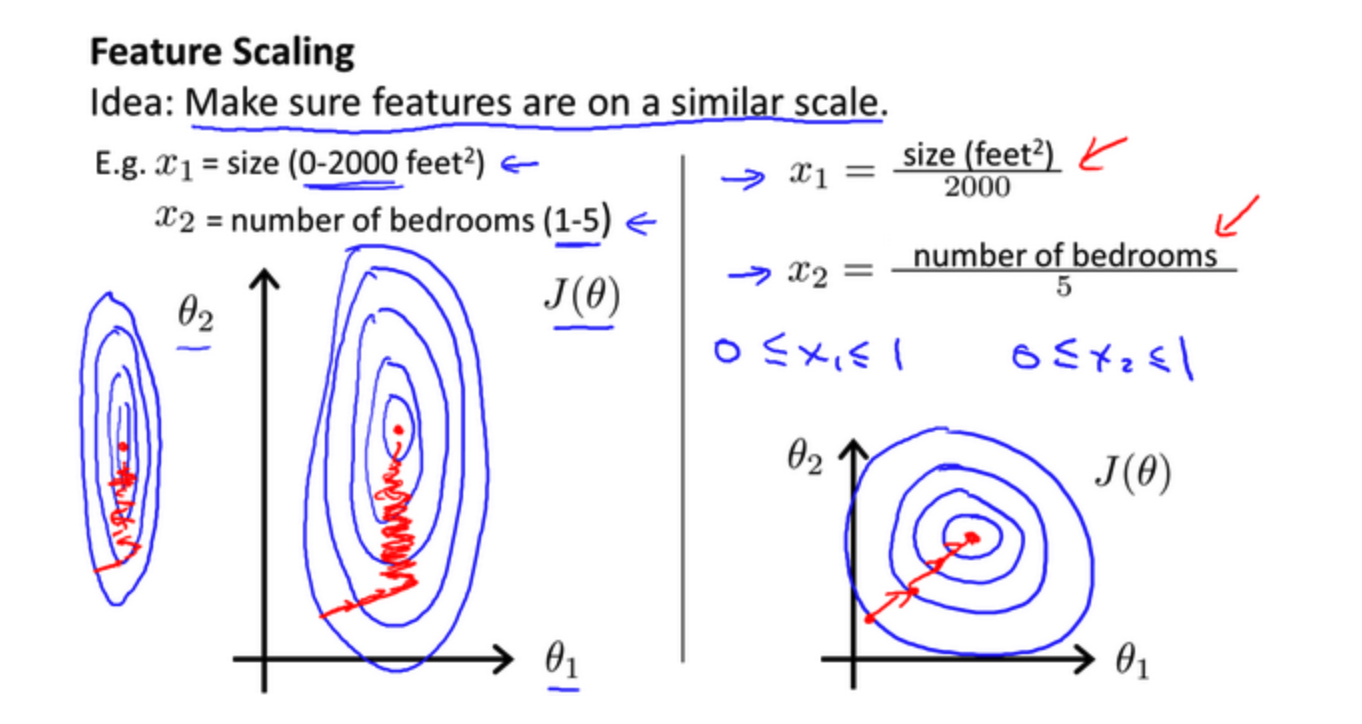
代价函数等高线图更加匀称,梯度下降效率会更高
常用的是 (Z-score),即
[x = frac{x - mu}{s}
]
其中 (mu) 为这个特征所有值的均值,(s) 为特征的标准差
7 正则化
- 过拟合问题一般由于计算的多项式中的高次项特征造成,为了避免这些高次项特征的系数过大,一般的处理方法主要有以下几种
- 使用特征选择工具例如
PCA 选取影响大的特征
- 正则化,保留所有的特征,通过加入惩罚项减少部分高次项特征的系数
假设新型回归模型多项式为
[{h_ heta}left( x
ight)={ heta_{0}}+{ heta_{1}}{x_{1}}+{ heta_{2}}{x_{2}^2}+{ heta_{3}}{x_{3}^3}+{ heta_{4}}{x_{4}^4}
]
- 参数 ( heta_3、 heta_4) 是高次项的系数,目的是减少这两个参数的值
线性回归的损失函数为
[underset{ heta }{mathop{min }}\,frac{1}{2m}[sumlimits_{i=1}^{m}{{{left( {{h}_{ heta }}left( {{x}^{(i)}}
ight)-{{y}^{(i)}}
ight)}^{2}}]}
]
在损失函数中加入对于 ( heta_3、 heta_4) 的惩罚项后损失函数为
[underset{ heta }{mathop{min }}\,frac{1}{2m}[sumlimits_{i=1}^{m}{{{left( {{h}_{ heta }}left( {{x}^{(i)}}
ight)-{{y}^{(i)}}
ight)}^{2}}+1000 heta _{3}^{2}+10000 heta _{4}^{2}]}
]
在加入惩罚项目后,为了使得损失函数最小,高次项系数会变小
在特征很多的时候,需要通过算法自动选择每一项特征的惩罚项,如下所示
[Jleft( heta
ight)=frac{1}{2m}[sumlimits_{i=1}^{m}{{{({h_ heta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+lambda sumlimits_{j=1}^{n}{ heta_{j}^{2}}]}
]
- (lambda) 称作是正则化参数,也是待优化的一个参数
- 如果 (lambda) 过大,所有参数都会变小最终导致 (h_ heta(x) = heta_0),导致欠拟合
- 如果 (lambda) 过小,不能很好的惩罚造成过拟合的特征项
对于校正参数 ( heta_0) 没有进行正则化,所以在梯度下降如下
[�egin{align}
Repeat~~until~~conver&gence { ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\
&{ heta_0}:={ heta_0}-afrac{1}{m}sumlimits_{i=1}^{m}{(({h_ heta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}})
\
&{ heta_j}:={ heta_j}-a[frac{1}{m}sumlimits_{i=1}^{m}{(({h_ heta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{left( i
ight)}}+frac{lambda }{m}{ heta_j}]
\
&for j=1,2,...n \
}~~~~~~~~~&
end{align}
]
其中 ( heta_j) 项提取公因式后化简为
[{ heta_j}:={ heta_j}(1-afrac{lambda }{m})-afrac{1}{m}sumlimits_{i=1}^{m}{({h_ heta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{left( i
ight)}}
]
正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令 $ heta $ 值减少了一个额外的值。