转自:Python 使用 PyMysql、DBUtils 创建连接池,提升性能 和 python多线程操作数据库问题
python多线程并发操作数据库,会存在链接数据库超时、数据库连接丢失、数据库操作超时等问题。
解决方法:使用数据库连接池,并且每次操作都从数据库连接池获取数据库操作句柄,操作完关闭连接返回数据库连接池。
*连接数据库需要设置charset = 'utf8', use_unicode = True,不然会报中文乱码问题
*网上说解决python多线程并发操作数据库问题,连接时使用self.conn.ping(True)(检查并保持长连接),但是我这边亲测无法解决,建议还是使用数据库连接池
解决方案:DBUtils
Python 编程中可以使用 PyMysql 进行数据库的连接及诸如查询/插入/更新等操作,但是每次连接 MySQL 数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对 mysql 的性能会产生较大的影响。因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的。
DBUtils 是一套 Python 数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装。DBUtils 来自 Webware for Python 。
原理:
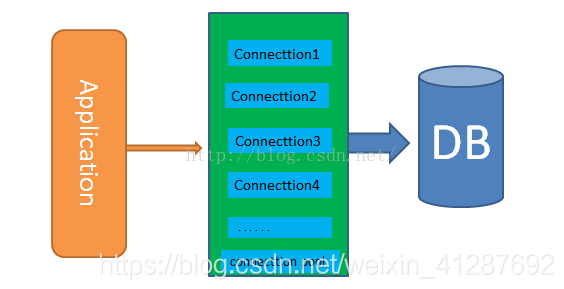
在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
python多线程代码:
import threading class MyThread(threading.Thread): def __init__(self, name, count, exec_object): threading.Thread.__init__(self) self.name = name self.count = count self.exec_object = exec_object def run(self): while self.count >= 0: count = count - 1 self.exec_object.execFunc(count) thread1 = MyThread('MyThread1', 3, ExecObject()) thread2 = MyThread('MyThread2', 5, ExecObject()) thread1.start() thread2.start() thread1.join() # join方法 执行完thread1的方法才继续主线程 thread2.join() # join方法 执行完thread2的方法才继续主线程 # 执行顺序 并发执行thread1 thread2,thread1和thread2执行完成才继续执行主线程 # ExecObject类是自定义数据库操作的业务逻辑类 # ########join方法详解######## thread1 = MyThread('MyThread1', 3, ExecObject()) thread2 = MyThread('MyThread2', 5, ExecObject()) thread1.start() thread1.join() # join方法 执行完thread1的方法才继续主线程 thread2.start() thread2.join() # join方法 执行完thread2的方法才继续主线程 # 执行顺序 先执行thread1,执行完thread1再执行thread2,执行完thread2才继续执行主线程
mysql数据库连接池代码:
import MySQLdb from DBUtils.PooledDB import PooledDB class MySQL: host = 'localhost' user = 'root' port = 3306 pasword = '' db = 'testDB' charset = 'utf8' pool = None limit_count = 3 # 最低预启动数据库连接数量 def __init__(self): self.pool = PooledDB(MySQLdb, self.limit_count, host = self.host, user = self.user, passwd = self.pasword, db = self.db, port = self.port, charset = self.charset, use_unicode = True) def select(self, sql): conn = self.pool.connection() cursor = conn.cursor() cursor.execute(sql) result = cursor.fetchall() cursor.close() conn.close() return result def insert(self, table, sql): conn = self.pool.connection() cursor = conn.cursor() try: cursor.execute(sql) conn.commit() return {'result':True, 'id':int(cursor.lastrowid)} except Exception as err: conn.rollback() return {'result':False, 'err':err} finally: cursor.close() conn.close()
精简版的连接池例子
import pymysql from DBUtils.PooledDB import PooledDB pool = PooledDB(pymysql,5,host='ip',user='user',passwd='passwd',db='db',port=3306,setsession=['SET AUTOCOMMIT = 1']) # 5为连接池里的最少连接数,setsession=['SET AUTOCOMMIT = 1']是用来设置线程池是否打开自动更新的配置,0为False,1为True conn = pool.connection() #以后每次需要数据库连接就是用connection()函数获取连接就好了 cur=conn.cursor() SQL="select * from table" count=cur.execute(SQL) results=cur.fetchall() cur.close() conn.close()
PooledDB 的参数:
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=1, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:[“set datestyle to …”, “set time zone …”]
ping=0,
# ping MySQL服务端,检查是否服务可用。
# 如:0 = None = never,
# 1 = default = whenever it is requested,
# 2 = when a cursor is created,
# 4 = when a query is executed,
# 7 = always
host=‘127.0.0.1’,
port=3306,
user=‘root’,
password=’’,
database=‘ziji’,
charset=‘utf8’
)
在 uwsgi 中,每个 http 请求都会分发给一个进程,连接池中配置的连接数都是一个进程为单位的(即上面的最大连接数,都是在一个进程中的连接数),而如果业务中,一个 http 请求中需要的 sql 连接数不是很多的话(其实大多数都只需要创建一个连接),配置的连接数配置都不需要太大。
连接池对性能的提升表现在:
在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
可能遇到的问题
python3 安装 第三方库DBUtils安装成功 项目里却import不了的解决方案
python3 mysql错误 pymysql.err.OperationalError: (2013, 'Lost connection to MySQL server during query')
参考:python3 mysql错误 pymysql.err.OperationalError: (2013, 'Lost connection to MySQL server during query')
AttributeError: 'NoneType' object has no attribute 'read'
推测问题是,多线程操作数据库连接的时候,相互交叉释放了其他线程的连接。
import threading lock = threading.Lock() lock.acquire() conn = pool.getConn() cur = conn.cursor() cur.execute(sql) rows = cur.fetchall() lock.release()