七:kafka基本的Java API操作
案例一:send函数参数中不带回调函数的Producer API操作:
1:先启动一个消费者

2:编写代码如下
package kafka_producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* @author Dawn
* @date 2019年6月3日14:21:23
* @version 1.0
* kafka生产者 API
*/
public class Producer1 {
public static void main(String[] args){
//1.配置生产者属性(指定多个参数)
Properties prop = new Properties();
//参数配置
//kafka节点的地址
prop.put("bootstrap.servers","192.168.40.11:9092");
//发送消息是否等待应答
prop.put("acks","all");
//配置发送消息失败重试
prop.put("retries","0");
//配置批量处理消息大小
prop.put("batch.size","10241");
//配置批量处理数据延迟
prop.put("linger.ms","5");
//配置内存缓冲大小
prop.put("buffer.memory", "12341235");
//消息在发送前必须序列化(*)
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//2.实例化producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//3.发送消息
for (int i=0; i<100; i++){
producer.send(new ProducerRecord<String, String>("morning","have_freshair"+i));
}
//4.释放资源
producer.close();
}
}
3:运行结果
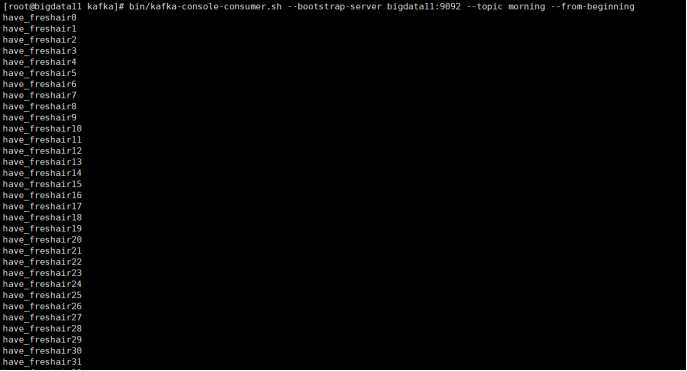
案例二:自定义分区以及Send函数参数中使用带回调函数的Producer
1:还是使用morning主题
2:编写代码:
分区:
package kafka_producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* @author Dawn
* @date
* @version 1.0
* 自定义分区,返回分区 1
*/
public class Partition1 implements Partitioner {
//分区逻辑
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
return 1;
}
//设置
public void configure(Map<String, ?> map) {
}
//释放资源
public void close() {
}
}
生成者,带回调函数
package kafka_producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* @author Dawn
* @date 2019年6月3日14:21:23
* @version 1.0
* kafka生产者 加入自定义分区。并且发送数据时使用回调函数CallBack
*/
public class Producer2 {
public static void main(String[] args){
//1.配置生产者属性(指定多个参数)
Properties prop = new Properties();
//参数配置
//kafka节点的地址
prop.put("bootstrap.servers","192.168.40.11:9092");
//发送消息是否等待应答
prop.put("acks","all");
//配置发送消息失败重试
prop.put("retries","0");
//配置批量处理消息大小
prop.put("batch.size","10241");
//配置批量处理数据延迟
prop.put("linger.ms","5");
//配置内存缓冲大小
prop.put("buffer.memory", "12341235");
//自定义分区就打开这个注释
prop.put("partitioner.class","kafka_producer.Partition1");
//消息在发送前必须序列化(*)
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//2.实例化producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//3.发送消息,使用回调函数
for (int i=0; i<100; i++){
producer.send(new ProducerRecord<String, String>("morning", "have_freshair +" + i), new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
//如果recordMetadata不为null 拿到当前的数据偏移量与分区
if (recordMetadata != null){
System.out.println(recordMetadata.topic() + "----" + recordMetadata.offset() + "----" + recordMetadata.partition());
}
}
});
}
//4.释放资源
producer.close();
}
}
3:运行结果
Kafka消费者中没有数据,一直悬停的

4:回调结果如下

分析:我们创建主题的时候就只有一个分区 即0号分区,我们在终端是消费的分区0中的数据。代码中我们添加了一个自定义分区,分区号为1,生成者send到分区1中的,所有消费者那里没有数据以及回调结果偏移量也是不变的。结合下面图看

案例3:kafka的拦截器
这里只是进行了一个简单处理。就是前面加了一个时间戳
1:代码如下
拦截器:
package kafka_interceptor;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
/**
* @author Dawn
* @date 2019年6月3日15:58:15
* @version 1.0
* 这里在拦截器哪里添加了当前时间
*/
public class TimeInterceptor implements ProducerInterceptor<String,String> {
//配置信息
public void configure(Map<String, ?> configs) {
}
//业务逻辑
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return new ProducerRecord<String, String>(
record.topic(),
record.partition(),
record.key(),
System.currentTimeMillis() + "-" + record.value());
}
//发送失败调用
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
//关闭资源
public void close() {
}
}
生成者:
package kafka_interceptor;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.ArrayList;
import java.util.Properties;
/**
* @author Dawn
* @date 2019-6-3 15:47:10
* @version 1.0
* kafka的拦截器
*/
public class Producer1 {
public static void main(String[] args) {
//1.配置生产者属性(指定多个参数)
Properties prop = new Properties();
//参数配置
//kafka节点的地址
prop.put("bootstrap.servers","192.168.40.11:9092");
//发送消息是否等待应答
prop.put("acks","all");
//配置发送消息失败重试
prop.put("retries","0");
//配置批量处理消息大小
prop.put("batch.size","10241");
//配置批量处理数据延迟
prop.put("linger.ms","5");
//配置内存缓冲大小
prop.put("buffer.memory", "12341235");
//消息在发送前必须序列化(*)
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//拦截器
ArrayList<String> list = new ArrayList<String>();
list.add("kafka_interceptor.TimeInterceptor");
prop.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,list);
//2.实例化producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//3.发送消息
for (int i=0; i<100; i++){
producer.send(new ProducerRecord<String, String>("morning","dawntest ---"+i));
}
//4:释放资源
producer.close();
}
}
运行结果如下:
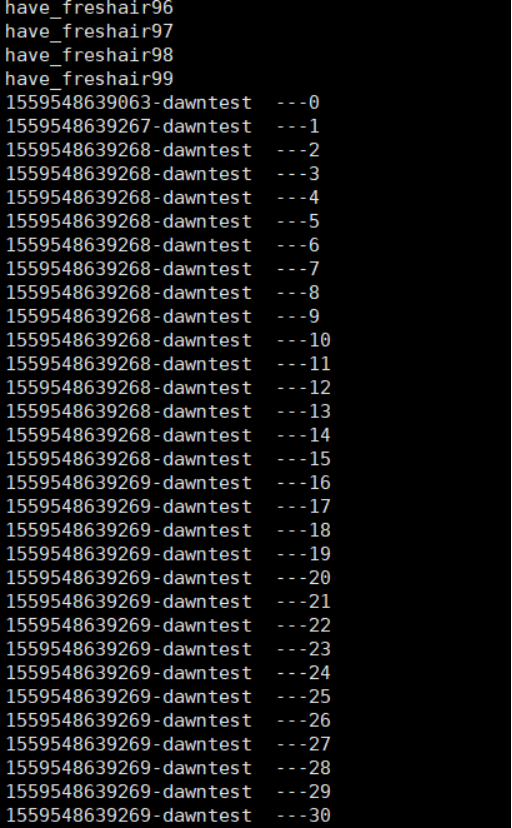
案例4:kafka Stream
需求?
这里进行简单的kafka计算。(注意kafka计算的性能不是很好,只能满足一点点的计算,一般情况下都是结合SparkStream storm用的)。这里进行简单的数据清洗
例如,在主题t1 producer中输入了dawn-persist
在主题t2 consumer中接收来的就是persist
1:代码如下
package kafka_stream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
/**
* @author Dawn
* @date 2019年6月3日16:55:09
* @version 1.0
* kafka简单数据清洗
* 需求?
* 例如:dawn-persist 结果: persist
* 定义主题,并将结果发送到另一个主题中
*/
public class LogProcessor implements Processor<byte[],byte[]> {
private ProcessorContext context;
public void init(ProcessorContext context) {
//传输
this.context=context;
}
//具体业务逻辑
public void process(byte[] key, byte[] value) {
//1.拿到具体数据,并装换成字符串
String message = new String(value);
//2:如果包含 - 就去掉,并且只保存右侧数据 例如 dawn-persist 结果: persist
if (message.contains("-")){
message=message.split("-")[1];
}
//3:发送数据
context.forward(key,message.getBytes());
}
public void close() {
}
}
主程序:
package kafka_stream;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import java.util.Properties;
/**
* @author Dawn
* @date
* @version 1.0
* kafka数据清洗。
*/
public class Application {
public static void main(String[] args) {
//1.定义2个主题,并将结果发送到另一个主题中
String firstTopic="t1";
String secondTopic="t2";
//2.设置属性
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"logProcessor");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata11:9092,bigdata12:9092,bigdata13:9092");
//3.实例对象
StreamsConfig config = new StreamsConfig(prop);
//4.流计算 拓扑
Topology bulider = new Topology();
//5.定义kafka组件数据源
bulider.addSource("Source",firstTopic).addProcessor("Processor", new ProcessorSupplier<byte[],byte[]>() {
public Processor<byte[],byte[]> get() {
return new LogProcessor();
}
//从哪里来
},"Source")
//去哪里
.addSink("Sink",secondTopic,"Processor");
//6.实例化kafkaStream
KafkaStreams kafkaStreams = new KafkaStreams(bulider, prop);
kafkaStreams.start();
}
}
2:运行结果

发送:

接收:
