一:Storm概述
ApacheStorm是一个免费的开源分布式实时计算系统。Storm可以轻松可靠地处理无限数据流,实现Hadoop对批处理所做的实时处理。Storm非常简单,可以与任何编程语言一起使用,并且使用起来很有趣!
Storm有许多用例:实时分析,在线机器学习,连续计算,分布式RPC,ETL等。风暴很快:一个基准测试表示每个节点每秒处理超过一百万个元组。它具有可扩展性,容错性,可确保您的数据得到处理,并且易于设置和操作。
Storm集成了您已经使用的排队和数据库技术。Storm拓扑消耗数据流并以任意复杂的方式处理这些流,然后在计算的每个阶段之间重新划分流。阅读教程中的更多内容。
离线计算是什么?
批量获取数据、批量的传输数据、批量的存储数据、周期性计算数据、数据可视化
flume批量获取数据、sqoop批量传输、hdfs/hive/hbase批量存储、mr/hive计算数据、BI
实时计算是什么?
数据实时产生、数据实时传输、数据实时计算、实时展示
flume实时获取数据、kafka实时数据存储、Storm/JStorm实时计算、实时展示(dataV/quickBI)
二:Storm与Hadoop
|
hadoop |
storm |
|
|
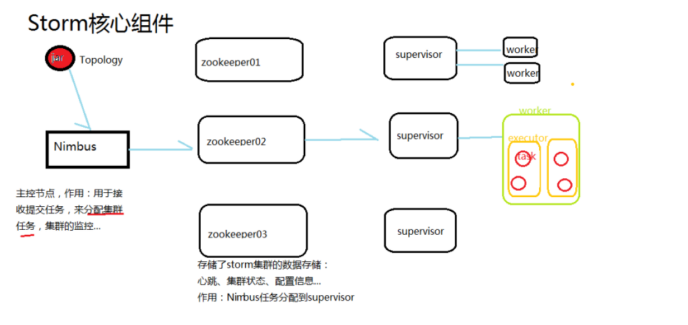
角色 |
JobTracker |
Nimbus |
|
TaskTracker |
Supervisor |
|
|
Child |
Worker |
|
|
应用名称 |
Job |
Topology |
|
编程接口 |
Mapper/Reducer |
Spout/Bolt |
三:storm编程模型

tuple:元祖
是消息传输的基本单元。
Spout:水龙头
storm的核心抽象。拓扑的流的来源。Spout通常从外部数据源读取数据。转换为内部的源数据。
主要方法:nextTuple() -》 发出一个新的元祖到拓扑。
ack()
fail()
Bolt:转接头
Bolt是对流的处理节点。Bolt作用:过滤、业务、连接运算。
Topology:拓扑
是一个实时的应用程序。
永远运行除非被杀死。
Spout到Bolt是一个连接流...
storm流式计算
hadoop与storm兼容性
闲聊:。。。。
spark-core
spark-sql离线计算
spark-streaming流式计算
一个团队开发 没有兼容性问题
spark团队:我要做一栈式开发平台!
但凡涉及到大数据计算 我都能搞定!
spark替代了mapreduce
spark没有底层存储
依赖hdfs
hdfs/mr............
完善整个生态圈系统!
mapreduce思想、编程 、sqoop->mr hive->mr hbasemr
dfs/mapreduce/bigtable
java/scala...
四:Storm集群安装部署
1)准备工作
zk01 zk02 zk03
storm01 storm02 storm03
2)下载安装包
http://storm.apache.org/downloads.html
3)上传
4)解压
5)修改配置文件
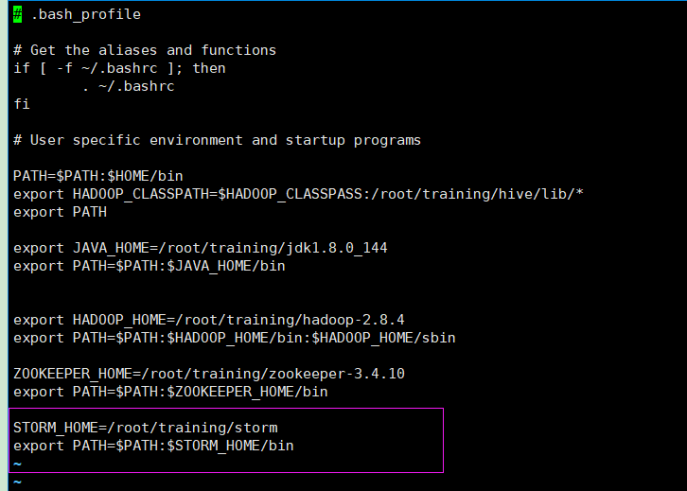
设置环境变量~/.bash_profile
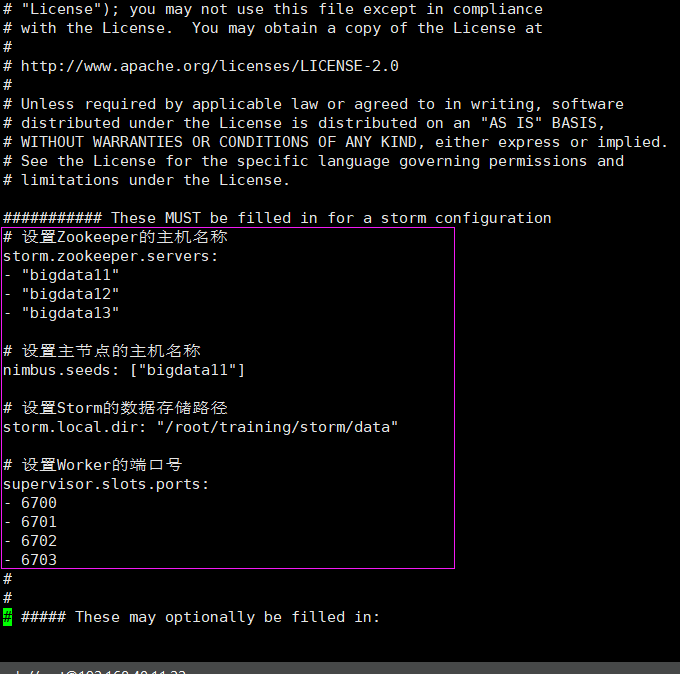
$ vi storm.yaml
# 设置Zookeeper的主机名称
storm.zookeeper.servers:
- "bigdata11"
- "bigdata12"
- "bigdata13"
# 设置主节点的主机名称
nimbus.seeds: ["bigdata11"]
# 设置Storm的数据存储路径(需要自己提前创建)
storm.local.dir: "/root/training/storm/data"
# 设置Worker的端口号
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
分发到bigdata12 和bigdata13,还有~/.bash_profile也要分发
6)启动nimbus
$ storm nimbus &
7) 启动supervisor
$ storm supervisor &
8)启动ui界面 端口8080
$ storm ui
Storm命令行操作
1)查看命令帮助
storm help
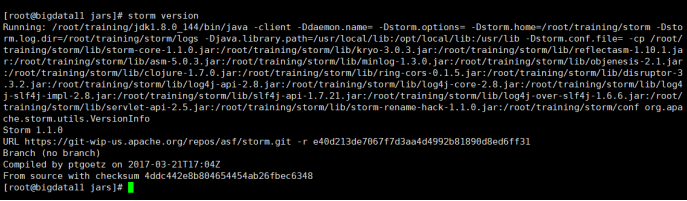
2)查看版本
storm version
3)运行storm程序
storm jar [/路径/.jar][全类名][拓扑名称]
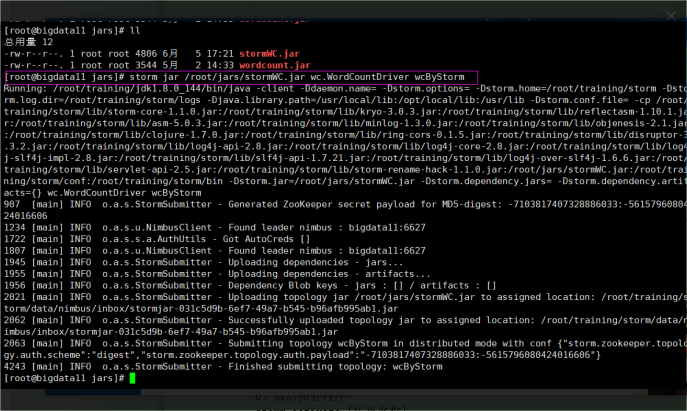
4)查看当前正在运行拓扑及其状态
storm list

5)终止拓扑程序
storm kill [拓扑名称]
6)激活拓扑程序
storm activate [拓扑名称]
7)禁止拓扑程序
storm deactivate [拓扑名称]