参与到开源项目的维护工作一般分两种,一种是由项目建立者拉入到贡献者列表中,拥有对项目的读写权限,而普通用户对项目仅有读取权限,另一种是fork项目到自己仓库,然后把修改后的内容发送给项目管理者者请求合并,是否合并到项目由项目管理者决定。
本文以symphony项目为例,项目地址https://github.com/b3log/symphony
1.fork到自己仓库
项目主页
fork完成
2.clone到本地
获取仓库地址
clone到本地完成
3.添加远程仓库
把原始仓库添加到本地远程仓库列表中,作用是当原始仓库有更新时本地可以及时的把原始仓库的最新数据拉取到本地然后合并,这样就可以使本地仓库与原始仓库保持同步,然后基于原始仓库我们就可以扩展新功能或修复问题
原始仓库地址

添加到本地远程仓库列表
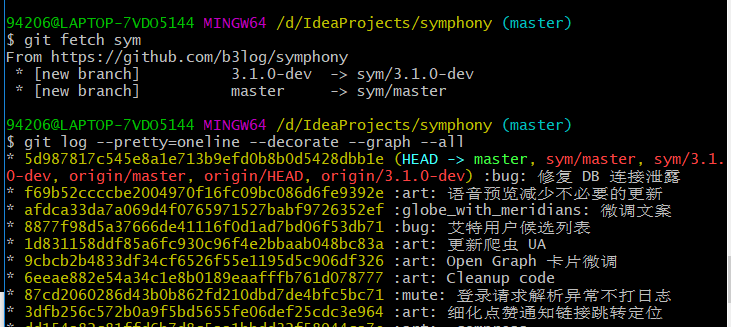
抓取远程仓库数据,可以看到sym仓库的分支被抓取下来了,origin指向的远程仓库是我fork到github上的地址,可以看到此时所有的分支都指向了同一个提交对象,都是最新的代码,并且本地分支还未创建,所以无需进行合并操作。如果本地分支已经创建,并且拉取的远程分支与本地对应的分支不在同一个提交对象上,那么我们才需要去合并他们,一般是把远程分支并入到本地分支,因为服务器上总是最新的代码。
4.建立对应的本地分支
执行git checkout -b 3.1.0-dev origin/3.1.0-dev 在本地新建一个3.1.0-dev分支并自动的把fork仓库的3.1.0-dev分支设置为跟踪分支,跟踪分支的作用是当在这个本地分支上指向git pull时自动就会去拉取fork库的数据然后自动合并入本地的3.1.0-dev分支中,注意当我们在clone fork库的时候git就自动把fork库的master设置为本地master的跟踪分支了。当然我们也可以把sym仓库的分支指定为本地跟踪分支,不过建议使用fork库,因为以后开发中主要操作的仓库是它,更新频率会比较频繁,而sym库我们仅在需要时拉取下最新数据而已,有新数据手动合并就好了。
5.总结
以上是我个人对如何参与到开源项目开发的见解和思路。
基本上就是那样,首先是fork,然后是clone,在然后是添加原始仓库地址(如果你很欣赏某项目,但对这项目的后续发展有了不同的看法,想在某版本后让其独立出来按自己的规划路线去发展,这种情况可以省略此步骤,因为它后面的更新与自己规划相冲突,没有拉取的必要了),最后就是开发了:无穷的拉取,合并,分支的创建和删除,提交,打标签,推送,给原始仓库发送pull request等操作。